倒排列表
倒排列表用来记录有哪些文档包含了某个单词。一般在文档集合里会有很多文档包含某个单词,每个文档 会记录文档编号(DocID),单词在这个文档中出现的次数(TF)及单词在文档中哪些位置出现过等信息,这样与一个文档相关的信息被称做倒排索引项(Posting),包含这个单词的一 系列倒排索引项形成了列表结构,这就是某个单词对应的倒排列表。图 1-1 是倒排列表的示意图,在文档集合中出现过的所有单词及其对应的倒排列表组成了倒排索引。
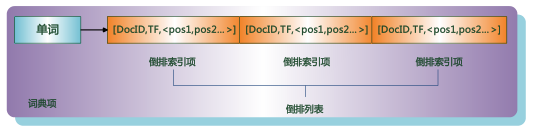
图1-1 倒排列表示意图
在实际的搜索引擎系统中,并不存储倒排索引项中的实际文档编号,而是代之以文档编号差 值(D-Gap)。文档编号差值是倒排列表中相邻的两个倒排索引项文档编号的差值,一般在索引构建过程中,可以保证倒排列表中后面出现的文档编号大于之前出现的文档编号,所以文档编号差值总是大于 0 的整数。如图 1-10 所示的例子中,原始的 3 个文档编号分别是 187、196 和 199,通过编号差值计算,在实际存储的时候就转化成了:187、9、3。
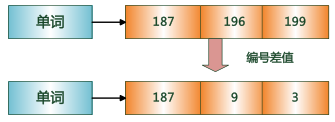
图1-2 文档编号差值示例
之所以要对文档编号进行差值计算,主要原因是为了更好地对数据进行压缩,原始文档编号一般都是大数值,通过差值计算,就有效地将大数值转换为了小数值,而这有助于增加数据的压缩率。