requests
Python标准库中提供了:urllib等模块以供Http请求,但是,它的 API 太渣了。它是为另一个时代、另一个互联网所创建的。它需要巨量的工作,甚至包括各种方法覆盖,来完成最简单的任务。
# 发送get请求 import urllib.request f = urllib.request.urlopen('http://www.webxml.com.cn//webservices/qqOnlineWebService.asmx/qqCheckOnline?qqCode=424662508') result = f.read().decode('utf-8')
# 发送携带请求头的GET请求 import urllib.request req = urllib.request.Request('http://www.example.com/') req.add_header('Referer', 'http://www.python.org/') r = urllib.request.urlopen(req) result = f.read().decode('utf-8')
注:更多见Python官方文档:https://docs.python.org/3.5/library/urllib.request.html#module-urllib.request
Requests 是使用 Apache2 Licensed 许可证的 基于Python开发的HTTP 库,其在Python内置模块的基础上进行了高度的封装,从而使得Pythoner进行网络请求时,变得美好了许多,使用Requests可以轻而易举的完成浏览器可有的任何操作。
安装模块
pip3 install requests
使用模块
# 1、无参数实例 import requests ret = requests.get('https://github.com/timeline.json') print(ret.url) print(ret.text) # 2、有参数实例 import requests payload = {'key1': 'value1', 'key2': 'value2'} ret = requests.get("http://httpbin.org/get", params=payload) print(ret.url) print(ret.text) GET请求
# 1、基本POST实例 import requests payload = {'key1': 'value1', 'key2': 'value2'} ret = requests.post("http://httpbin.org/post", data=payload) print(ret.text) # 2、发送请求头和数据实例 import requests import json url = 'https://api.github.com/some/endpoint' payload = {'some': 'data'} headers = {'content-type': 'application/json'} ret = requests.post(url, data=json.dumps(payload), headers=headers) print(ret.text) print(ret.cookies) POST请求
requests.get(url, params=None, **kwargs) requests.post(url, data=None, json=None, **kwargs) requests.put(url, data=None, **kwargs) requests.head(url, **kwargs) requests.delete(url, **kwargs) requests.patch(url, data=None, **kwargs) requests.options(url, **kwargs) # 以上方法均是在此方法的基础上构建 requests.request(method, url, **kwargs) 其他请求
更多requests模块相关的文档见:http://cn.python-requests.org/zh_CN/latest/
Http请求和XML实例
实例:检测QQ账号是否在线


import urllib import requests from xml.etree import ElementTree as ET # 使用内置模块urllib发送HTTP请求,或者XML格式内容 """ f = urllib.request.urlopen('http://www.webxml.com.cn//webservices/qqOnlineWebService.asmx/qqCheckOnline?qqCode=424662508') result = f.read().decode('utf-8') """ # 使用第三方模块requests发送HTTP请求,或者XML格式内容 r = requests.get('http://www.webxml.com.cn//webservices/qqOnlineWebService.asmx/qqCheckOnline?qqCode=424662508') result = r.text # 解析XML格式内容 node = ET.XML(result) # 获取内容 if node.text == "Y": print("在线") else: print("离线")
实例:查看火车停靠信息
import urllib import requests from xml.etree import ElementTree as ET # 使用内置模块urllib发送HTTP请求,或者XML格式内容 """ f = urllib.request.urlopen('http://www.webxml.com.cn/WebServices/TrainTimeWebService.asmx/getDetailInfoByTrainCode?TrainCode=G666&UserID=') result = f.read().decode('utf-8') """ # 使用第三方模块requests发送HTTP请求,或者XML格式内容 r = requests.get('http://www.webxml.com.cn/WebServices/TrainTimeWebService.asmx/getDetailInfoByTrainCode?TrainCode=G666&UserID=') result = r.text # 解析XML格式内容 root = ET.XML(result) for node in root.iter('TrainDetailInfo'): print(node.find('TrainStation').text,node.find('StartTime').text,node.tag,node.attrib)
注:更多接口猛击这里
logging
用于便捷记录日志且线程安全的模块
1单文件日志
import logging
logging.basicConfig(filename='log.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10)
logging.debug('debug')
logging.info('info')
logging.warning('warning')
logging.error('error')
logging.critical('critical')
logging.log(10,'log')
日志等级:
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0
注:只有【当前写等级】大于【日志等级】时,日志文件才被记录。
日志记录格式:
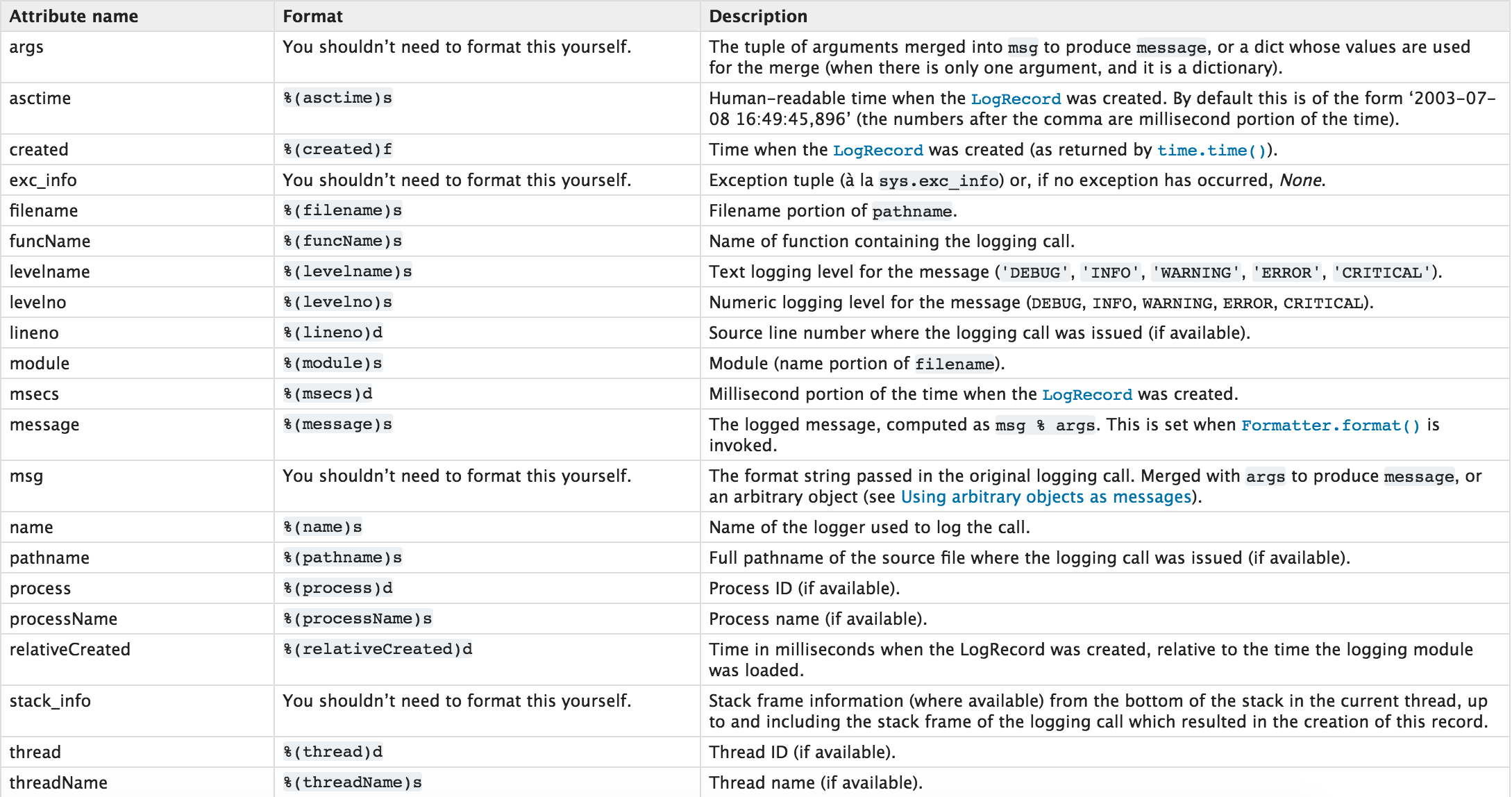
2 多文件日志
对于上述记录日志的功能,只能将日志记录在单文件中,如果想要设置多个日志文件,logging.basicConfig将无法完成,需要自定义文件和日志操作对象。
# 定义文件 file_1_1 = logging.FileHandler('l1_1.log', 'a') fmt = logging.Formatter(fmt="%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s") file_1_1.setFormatter(fmt) file_1_2 = logging.FileHandler('l1_2.log', 'a') fmt = logging.Formatter() file_1_2.setFormatter(fmt) # 定义日志 logger1 = logging.Logger('s1', level=logging.ERROR) logger1.addHandler(file_1_1) logger1.addHandler(file_1_2) # 写日志 logger1.critical('1111') 日志(一)
# 定义文件 file_2_1 = logging.FileHandler('l2_1.log', 'a') fmt = logging.Formatter() file_2_1.setFormatter(fmt) # 定义日志 logger2 = logging.Logger('s2', level=logging.INFO) logger2.addHandler(file_2_1) 日志(二)
如上述创建的两个日志对象
- 当使用【logger1】写日志时,会将相应的内容写入 l1_1.log 和 l1_2.log 文件中
- 当使用【logger2】写日志时,会将相应的内容写入 l2_1.log 文件中
系统命令subprocess
执行shell命令的相关模块和函数有:
- os.system
- os.spawn*
- os.popen* --废弃
- popen2.* --废弃
- commands.* --废弃,3.x中被移除
import commands result = commands.getoutput('cmd') result = commands.getstatus('cmd') result = commands.getstatusoutput('cmd')
以上执行shell命令的相关的模块和函数的功能均在 subprocess 模块中实现,并提供了更丰富的功能。
call
执行命令,返回状态码
ret = subprocess.call(["ls", "-l"], shell=False)
ret = subprocess.call("ls -l", shell=True)
check_call
执行命令,如果执行状态码是 0 ,则返回0,否则抛异常
subprocess.check_call(["ls", "-l"])
subprocess.check_call("exit 1", shell=True)
check_output
执行命令,如果状态码是 0 ,则返回执行结果,否则抛异常
subprocess.check_output(["echo", "Hello World!"])
subprocess.check_output("exit 1", shell=True)
subprocess.Popen(...)
用于执行复杂的系统命令
参数:
- args:shell命令,可以是字符串或者序列类型(如:list,元组)
- bufsize:指定缓冲。0 无缓冲,1 行缓冲,其他 缓冲区大小,负值 系统缓冲
- stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- preexec_fn:只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用
- close_sfs:在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。
所以不能将close_fds设置为True同时重定向子进程的标准输入、输出与错误(stdin, stdout, stderr)。 - shell:同上
- cwd:用于设置子进程的当前目录
- env:用于指定子进程的环境变量。如果env = None,子进程的环境变量将从父进程中继承。
- universal_newlines:不同系统的换行符不同,True -> 同意使用
- startupinfo与createionflags只在windows下有效
将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如:主窗口的外观,进程的优先级等等
# 执行普通命令 import subprocess ret1 = subprocess.Popen(["mkdir","t1"]) ret2 = subprocess.Popen("mkdir t2", shell=True)
终端输入的命令分为两种:
- 输入即可得到输出,如:ifconfig
- 输入进行某环境,依赖再输入,如:python
import subprocess
obj = subprocess.Popen("mkdir t3", shell=True, cwd='/home/dev',)
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
obj.stdin.write("print(1)
")
obj.stdin.write("print(2)")
obj.stdin.close()
cmd_out = obj.stdout.read()
obj.stdout.close()
cmd_error = obj.stderr.read()
obj.stderr.close()
print(cmd_out)
print(cmd_error)
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
obj.stdin.write("print(1)
")
obj.stdin.write("print(2)")
out_error_list = obj.communicate()
print(out_error_list)
import subprocess
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE, universal_newlines=True)
out_error_list = obj.communicate('print("hello")')
print(out_error_list)
shutil
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
import shutil
shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
shutil.copyfile(src, dst)
拷贝文件
shutil.copyfile('f1.log', 'f2.log')
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
shutil.copymode('f1.log', 'f2.log')
shutil.copystat(src, dst)
拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log')
shutil.copy(src, dst)
拷贝文件和权限
shutil.copy('f1.log', 'f2.log')
shutil.copy2(src, dst)
拷贝文件和状态信息
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
import shutil shutil.copytree('f1', 'f2', symlinks=True, ignore=shutil.ignore_patterns('*.pyc', 'tmp*'))
递归的去删除文件
shutil.rmtree('folder1')
shutil.move(src, dst)
递归的去移动文件,它类似mv命令,其实就是重命名。
shutil.move('folder1', 'folder3')
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如:www =>保存至当前路径
如:/Users/wupeiqi/www =>保存至/Users/wupeiqi/ - format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
#将 /Users/wupeiqi/Downloads/test 下的文件打包放置当前程序目录
import shutil
ret = shutil.make_archive("wwwwwwwwww", 'gztar', root_dir='/Users/wupeiqi/Downloads/test')
#将 /Users/wupeiqi/Downloads/test 下的文件打包放置 /Users/wupeiqi/目录
import shutil
ret = shutil.make_archive("/Users/wupeiqi/wwwwwwwwww", 'gztar', root_dir='/Users/wupeiqi/Downloads/test')
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
import zipfile # 压缩 z = zipfile.ZipFile('laxi.zip', 'w') z.write('a.log') z.write('data.data') z.close() # 解压 z = zipfile.ZipFile('laxi.zip', 'r') z.extractall() z.close() zipfile解压缩
import tarfile # 压缩 tar = tarfile.open('your.tar','w') tar.add('/Users/wupeiqi/PycharmProjects/bbs2.log', arcname='bbs2.log') tar.add('/Users/wupeiqi/PycharmProjects/cmdb.log', arcname='cmdb.log') tar.close() # 解压 tar = tarfile.open('your.tar','r') tar.extractall() # 可设置解压地址 tar.close() tarfile解压缩
练习题:
1、通过HTTP请求和XML实现获取电视节目
API:http://www.webxml.com.cn/webservices/ChinaTVprogramWebService.asmx
2、通过HTTP请求和JSON实现获取天气状况
API:http://wthrcdn.etouch.cn/weather_mini?city=北京