k

CAP帽子理论。
consistency:一致性 Availability:可用性 partition tolerance:分区容忍型


CA :mysql oracle(抛弃了网络分区)
CP:hbase redis mongodb(抛弃了可用性)
AP:cassandra simpleDB(抛弃了强一致性,采用弱一致性或者最终一致性,不定时一致性)
一致性的方案

master-slave(hadoop)
WNR 读取后还得判断哪个数据是最新的。常用做法(版本号或者时间戳)

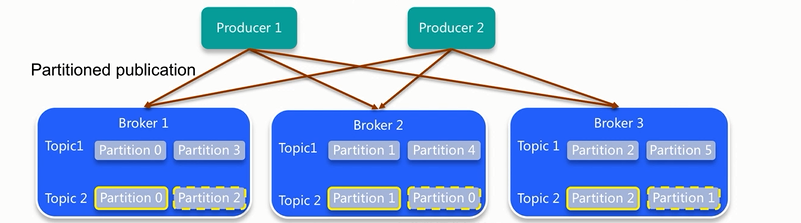

平时读取数据是从leader上读取,follower是为了防止leader宕机进行可用性保证。数据是follower从leader拉取,类似consumer

kafka既不是同步也不是异步机制,而是采用了isr机制。(kafka一旦数据进行commit就必须保证所有的数据都被commit)
一旦发现follower和leader相距的数据过大,就会进行节点移除。差距过大的条件为时间或者条目数:

这是kafka区别与其他系统一个亮点,既不采用同步复制也不采用异步,而且采用了中间的动态控制的设计。
min,insync.replicas是kafka备份的选取,通常是2比较安全一些
request.required.acks
0:这意味着生产者producer不等待来自broker同步完成的确认继续发送下一条(批)消息。此选项提供最低的延迟但最弱的耐久性保证(当服务器发生故障时某些数据会丢失,如leader已死,但producer并不知情,发出去的信息broker就收不到)。
1:这意味着producer在leader已成功收到的数据并得到确认后发送下一条message。此选项提供了更好的耐久性为客户等待服务器确认请求成功(被写入死亡leader但尚未复制将失去了唯一的消息)。
-1:这意味着producer在follower副本确认接收到数据后才算一次发送完成。
此选项提供最好的耐久性,我们保证没有信息将丢失,只要至少一个同步副本保持存活。
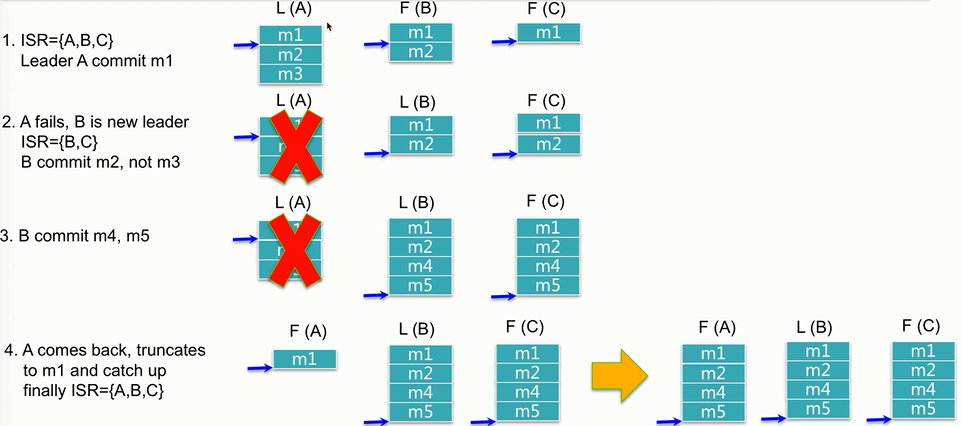
从上图可以看出kafka只有commit的数据才会可以被消费。比如3---4时候M3数据会丢失,因为leader宕机的时候M3从来没被commit过,所以数据在默认retry还没成功就会丢失,但是如果retry成功后会插入M5之后,顺序性也就变了(所以kafka的顺序性是comit顺序而不是发送顺序,而且处理不好也会存在数据丢失的情况),一旦宕机节点恢复就需要check out所有落后数据,直到isr设置的临界点(比如4K条目)才会被加入到ISR列表中。

有选项可以配置全部节点挂掉时候,是恢复isr中的列表,还是全部机器无论在不在ISR中(默认选项)

备份数目不能超过broker数量

默认kafka的replicas和leader都会尽量均匀分配。因为读写都是通过leader所以需要尽量性能均匀些