HTTP权威指南------Web服务器
Web服务器
Web服务器实现了HTTP协议与相关的TCP连接处理,管理相关的资源,并且具有对相关服务的管理控制。系统为Web服务器提供底层的网络支持,文件系统,进程管理等。Web服务器的核心是请求的处理与内容的相应。具体的种类可以是软件或者一体的软硬件设备,嵌入式服务器等。
服务器的基本任务
下面列举的是服务器要处理的基本任务,也就是一个基本的请求处理到响应的过程。

大致分为六个部分:建立连接,接受请求,处理请求,访问资源,构建响应,发送响应,记录日志。
建立连接
接受客户端的连接是处理的第一步,如果之前建立的持久连接也可以直接使用持久连接。
处理新连接
对于新连接的处理是从TCP连接开始的,通过TCP报文很容易可以解析出IP(具体可以使用系统的调用),如果接受该连接,就会将其存入Web服务器中的连接列表中以便监视后续的数据传输,Web服务器也可以拒绝连接或者关系任意连接。
主机名识别
Web服务器也可以访问DNS来反向获得客户端的主机名以便于日志的记录,但是DNS的处理是相当费时的,这对于服务器的性能来说是不利的,因此一般会禁用这一过程,或者对少量内容进行反向的主机名识别。
ident用户识别
Web服务器是支持或者说是实现了ident协议的,服务器可以通过ident协议来获得客户端的用户名以便进行日志记录。

ident协议的工作过程是服务器打开自己80端口到客户端113端口的连接,服务器请求客户端连接对应的用户名,服务器收到响应后解析出用户名。
由于协议的自身并不安全容易伪造,并且涉及隐私,许多防火墙是限制ident流量的,其具体的使用不广泛,一般在内部网络中工作。
接受请求
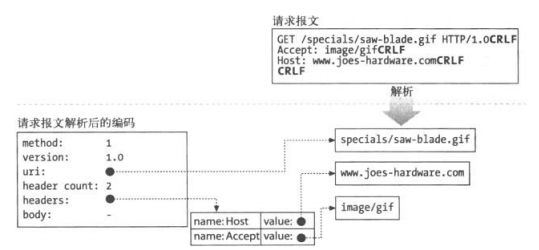
接受请求是在TCP连接上读取相应的请求报文,并且进行相应的解析,解析的过程具体为:
解析请求行
按照报文的格式找出请求方法,URL,版本号,其用空格隔开,并以回车换行为结束。
解析报文首部
报文首部是键值对的列表,每个键值对也是以回车换行结尾。
解析请求主体
根据报文中的Content-Length首部表明的长度读取相应的请求实体(有些请求报文是没有主体的)。
报文内部表示
在网络传输的过程中是存在延迟的,所以读取的数据是存到缓存中的,等到足够数据量的时候再进行解析。此外报文的内部可以使用一些数据结构进行表示,比如指针或者是片段的长度用于辅助表示。
连接的I/O结构
服务器是要并发处理多条连接的,并且请求的到达是不确定的,所以服务器会不停的查看是否有请求到来,不同的结构处理数据I/O工作的方式不同。常用的结构有:
- 单线程Web服务器

这是一种简单的实现方式,使用一个线程或者进程来处理,一次只能处理一个连接请求,并且是阻塞式的访问,直到该请求完成后才继续处理其他请求,这一实现方式的性能是较差的。 - 多线程/进程Web服务器

多个线程或进程为连接提供服务,可以实现对于多个连接的并发处理,如果是多核cpu则是并行处理,为了更好的处理连接,服务器有时会预先创建并维护一组进程或者线程,比如线程池这种结构,以便及时处理请求,但是如果是为每一个连接单独创建线程或者进程,在多连接的情况下就会消耗极大的内存与资源,所以一般服务器都会对线程或进程的数量进行限制。 - I/O复用的Web服务器

之前的两种方式上都将连接与线程进行了绑定,在连接的请求未处理完之前线程或进程是阻塞的,但是请求往往是有延迟的,在时间上是有空闲的。
I/O复用是对多个连接进行监视,当连接需要进行I/O处理时将其取出,处理之后再放回队列取出下一个需要处理的连接。这样的好处是可以使用连接的时延去处理其他连接的请求,减少处理的空等时间。 - 多线程复用的Web服务器

将上面的复用结构给到每个线程中,即每个线程可以负责多个连接的复用处理,使得多线程中处理中的空等时间减少,提高处理效率。
处理请求
处理请求的过程就比较复杂了,不同的请求方法,请求不同的资源,服务,报文首部不同的控制项,报文实体中不同的数据信息,都对应着不同的处理,所以处理请求是多样的,复杂的,具体要根据报文的内容进行具体的分析。
访问资源
访问资源首先要获得资源在服务器中的具体位置,实际的处理是实现URL到服务器中资源的映射。除此之外服务器还可以通过相应的认证机制实现资源的访问控制。
docroot
在服务器中会设置一个单独的文件夹存放Web内容,其为根目录(document root),即docroot。服务器在请求报文中获得URL,解析出域名后的路径可以直接映射到docroot中的对应文件,但是对应的URL是无法访问到docroot以外的内容。

具体的docroot路径映射可以在web服务器中进行配置,比如Apache可以通过httpd.conf中的DocumentRoot属性进行配置。
虚拟docroot
虚拟化的管理方式可以使一个主机站点上配置多个Web站点,每个站点使用不同的文档空间,在处理时可以通过URL中的Host或者路径来进行识别,这样在处理请求时就可以进行不同路径的内容映射来区分站点。

相应的在Web服务器中需要对每个Web站点进行虚拟配置,为每个站点提供独立的根目录来进行区分,通常在Web服务器配置文件中就能完成。
用户docroot
除了对站点进行区分外,也可以对用户进行细分,进一步的划分空间,每个用户拥有一个私有的docroot,根据URL中用户信息来进行对应的内容映射。

目录请求
除了对于固定文件的URL请求外,还可以对相应的目录路径进行请求,服务器对这种请求有三种处理方式:
- 允许访问目录中的内容,这时会返回一个文件,其中包含了该目录的具体信息,包括所有的文件的信息和对应的访问路径。
- 允许访问,但是以一个索引文件来代表目录,实际访问的是该文件中的内容。
- 不允许访问,返回错误。
使用web服务器中的具体指令可以实现对目录中索引文件的设置,也可以直接让服务器返回目录的全部索引(Apache中可以使用Options-Indexes指令实现)。
动态处理
程序映射
这种请求要完成的工作就不仅仅是一个静态资源的映射了,其实际映射的可能是一段后台程序,服务器要完成的是识别URL对应的请求的程序,并将请求交由后台程序处理。
Apache中提供了一个cgi类的文件目录,可以存放一些cgi后缀的程序文件,这是一种比较简单的程序结构,此外也可以是Tomcat中的servlet等。
服务器端包含项(SSI)
不同的请求得到的文件会有许多的重复部分,其不同的内容可以使用一种模板进行抽象,于是可以在固定的资源内部进行变量的标记(即服务器端包含项),服务器在返回给客户端内容前,根据不同的请求来对变量进行处理替换,以达到动态响应的目的。
构建响应
构建响应报文包括了响应状态码,响应首部,响应主体,响应状态码与首部只要按照对应的响应处理生成即可,而构建响应的重点是在于将处理的内容以相应的格式形成报文。
响应实体
响应实体是报文的主体,为了描述响应主体的长度,使用Content-Length首部进行描述,此外还有主体的类型(MINE类型),使用Content-Type首部描述。
MINE类型
如何将资源与对应的类型进行关联是服务器需要处理的一个问题,匹配的方式有:
- 根据文件的后缀名进行匹配,处理的时候只要与一个包含所有扩展名与MINE类型的文件进行比对,即可完成对应的类型映射。

- 扫描资源内容,并将其与一个模式表进行匹配,决定文件的MINE类型,这种方式速度较慢,但是在文件没有扩展名的时候使用方便。
- 按照固定的文件与文件夹进行分类,不考虑文件的后缀与内容,只看特定的路径与文件,这需要对服务器进行相应配置。
- 协商设置也是一种方式,对应文件的MINE类型是需要与用户进行相应的协商之后进行设定。
重定向
有些请求无法直接获得响应结果,可能需要请求其他路径或者服务器在获得响应,这时就使用重定向来进行处理,使用3XX的状态码并返回重定向的URL(存储到Location)来引导客户端进行再次访问。具体的情况有:
- 永久删除资源
资源由于移动或者重命名,在请求的路径中无法找到(相当于删除了旧路径中的文件),于是通过301状态码进行资源新位置的获取,重定向到资源的当前位置。 - 临时删除的资源
与上面的永久删除不同,永久删除是说明最先请求的URL永远无法对应得到资源,客户端得到响应后会修改对于的缓存,下次就不以这个URL请求了,而临时删除顾名思义,是短暂的时间无法通过该URL获得对应的资源,之后等这个时间过去原先的URL还是可以进行资源对应的,使用的状态码为303或307。 - URL增强
这里重定向的URL包含了一些处理过的状态信息,也就是原先请求的URL经过了一些处理后得到了相应的附加信息,这些附加信息会在重定向之后用于事务的处理,也是使用303或307状态码进行重定向响应。 - 负载均衡
这里重定向相当于一个请求的转发,将该请求转发到一个负载小一些的服务器中进行处理,使用的状态码也为303或307。 - 服务器关联
在一些服务器集群中服务器仅能存储部分用户的信息,所以其他的客户端请求过来时就可以进行重定向,将请求交由包含用户信息的服务器进行处理。 - 规范目录名称
这里的目录名称是在URL中的目录名称,比如其访问目录的尾部没有带"/"可以返回一个规范的URL重定向,令其再次请求。
重定向的响应是一个比较特殊的响应,仍需要客户端进行二次的请求才能得到其需要的最终结果。
发送响应
响应的发送与客户端发送请求相似,但是服务器是一个一对多的结构,所以还需要对每条连接进行管理,若是非持久连接完成发送后直接关闭就好,若是持久连接就要为每个报文设置好准确的Content-Length以方便客户端进行报文边界的处理。
记录日志
日志记录是对事务处理情况的记录,一般在一个事务完成后进行相应的记录,生成相应的日志文件,日志的格式也是多样的一般服务器会提供多种日志格式的配置。