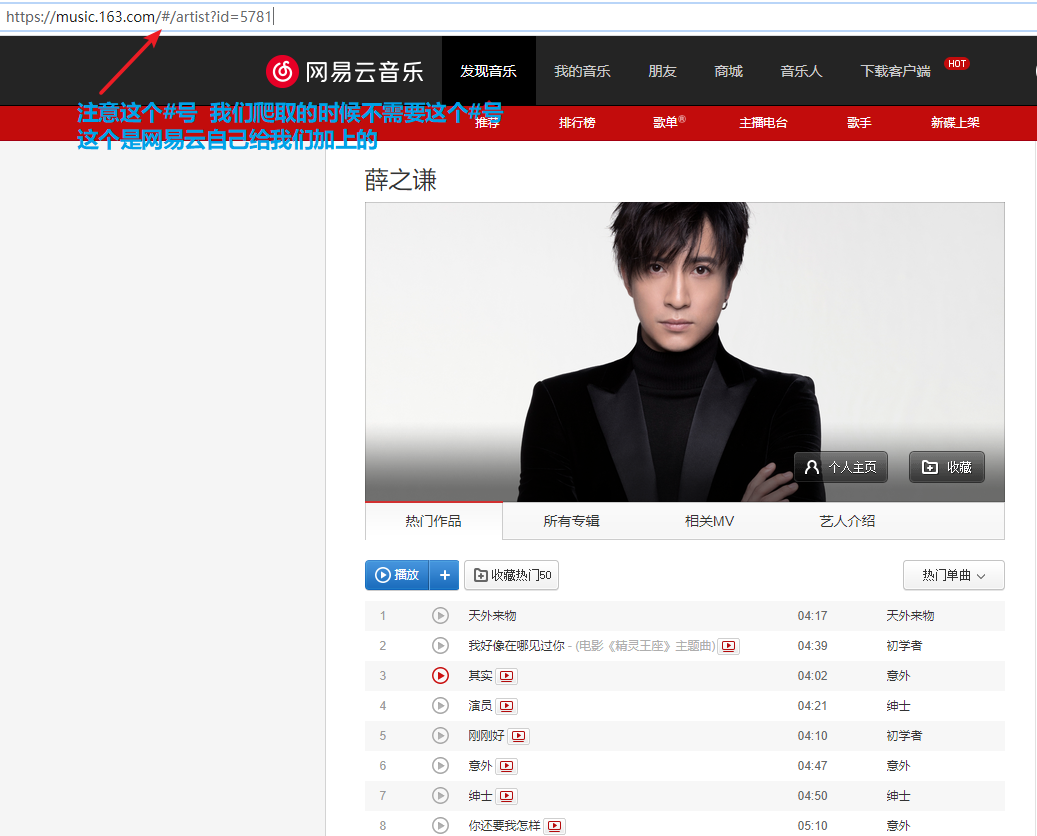
使用 requests 爬取网易云音乐
Python 代码:


import json import os import time from bs4 import BeautifulSoup import requests class Music: """ 下载网易云歌手排行前50的歌曲 """ def __init__(self, init_url, download): self.init_url = init_url self.download = download def mkdir(self, path): """ 创建文件夹 :param path: :return: """ path = path.strip() if not os.path.exists(path): # 判断此文件夹存不存在 print('创建 ', path, '文件夹') os.makedirs(path) return True else: print(path, '文件夹已存在,无需创建') return False def download_video(self, video_url, name): """ 下载 :param video_url: 音乐的链接 :param name: 歌曲名称 :return: """ path = self.download + "\" + name + '.mp3' # 拼接保存后的文件路径 # print(path) headers = { "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36", } header = { "Origin": "http://music.163.com/", "Referer": video_url, # 请求头必须添加referer } headers.update(header) # 更新头部信息 size = 0 start = time.time() try: result = requests.get(video_url, headers=headers, stream=True, verify=False) # print('result', result) with open(path, "wb") as f: for chunk in result.iter_content(1024): f.write(chunk) f.flush() # 清空缓存 size = size + len(chunk) print("已下载:%0.2f Mb" % (size / (1024 * 1024))) except Exception as e: print("url下载错误:%s" % video_url) print(e) stop = time.time() print("下载完成,耗时:%0.2f秒" % (stop - start)) def spider(self): r = requests.get(self.init_url).text soupObj = BeautifulSoup(r, 'lxml') song_ids = soupObj.find('textarea').text # print(song_ids) jobj = json.loads(song_ids) list01 = [] for item in jobj: dict01 = {} # print(item['id']) # 歌曲id # print(item['name']) # 歌曲名称 dict01['name'] = item['name'] dict01['id'] = item['id'] list01.append(dict01) print(list01) len_list = len(list01) print("一共", len_list, "首歌曲") self.mkdir(self.download) print('开始切换文件夹') os.chdir(self.download) for i in list01: name = i['name'] id = i['id'] song_url = "http://music.163.com/song/media/outer/url?id=" + str(id) + ".mp3" print(song_url) # 最终下载的音乐链接 self.download_video(song_url, name) # 下载 len_list = len_list - 1 print("还剩", len_list, "首歌曲需要下载") if __name__ == '__main__': # init_url = 'https://music.163.com/artist?id=5781' # 薛之谦 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\xzq' # 保存地址 # init_url = 'https://music.163.com/artist?id=12429072' # 隔壁老樊 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\gblf' # 保存地址 # init_url = 'https://music.163.com/artist?id=861777' # 华晨宇 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\hcy' # 保存地址 # init_url = 'https://music.163.com/artist?id=6452' # 周杰伦 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\zjl' # 保存地址 # init_url = 'https://music.163.com/artist?id=2116' # 陈奕迅 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\cyx' # 保存地址 # init_url = 'https://music.163.com/artist?id=3684' # 林俊杰 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\ljj' # 保存地址 # init_url = 'https://music.163.com/artist?id=12138269' # 毛不易 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\mby' # 保存地址 # init_url = 'https://music.163.com/artist?id=4292' # 李荣浩 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\lrh' # 保存地址 # init_url = 'https://music.163.com/artist?id=30116848' # 阿冗 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\ar' # 保存地址 # init_url = 'https://music.163.com/artist?id=5771' # 许嵩 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\xs' # 保存地址 # init_url = 'https://music.163.com/artist?id=6472' # 张杰 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\zj' # 保存地址 # init_url = 'https://music.163.com/artist?id=5538' # 汪苏泷 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\wsl' # 保存地址 # init_url = 'https://music.163.com/artist?id=1197168' # 徐秉龙 # download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\xbl' # 保存地址 init_url = 'https://music.163.com/artist?id=30284835' # 枯木逢春 download = 'C:\Users\AIERXUAN\Desktop\BeautifulPicture\Music\kmfc' # 保存地址 s = Music(init_url, download) s.spider()
"http://music.163.com/song/media/outer/url?id=417859631.mp3" 打开这个链接就可以直接播放音乐 后面的id代表的是歌曲在网易云里面的id
由于网易云有的音乐链接已经弃用,所以有的音乐会下载失败
网易云的许多post请求都是被加密的,如果你们破解不了可以点击这个链接去看看大佬是怎么破解的:https://blog.csdn.net/xiaoming_xiaoli/article/details/88019016
关于网易云api的其他接口可以进去这里面查看:http://www.goodpm.net/postreply/python/1010000008139311/关于网易云音乐爬虫的api接口.html
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
每天一个表情包,给生活加个油
