一、列表的特点
- 列表也是一种数据类型
- 列表元素是有序的,有编号的
- 列表元素的下标从0开始
- 列表中的每一个值叫一个元素,编号叫下标(索引/角标):
stu_name=['崔海龙','杨帆','lrx',1,1.5]
这里,崔海龙是一个元素,它的索引是0。
二、列表操作
1、增删改查操作
#增:
使用.append()方法:
stu_name.append('杨月') #list的末尾追加元素
使用.insert()方法:
stu_name.insert(2,'小军')#在指定位置之前添加元素,要指定元素下标
- 区别:
.append()是只能追加到list末尾,而.insert()可以指定角标位置。
- 重复执行一条语句多次,会不会添加多个相同的值?
# #由于写代码都是在内存中运行的,一旦执行完毕就会释放变量,因此重复执行多次都只插入一个变量值,不会重复插入同样的值。
# # 列表定义的变量是在内存中执行的,一旦关闭程序就会丢失,而文件则是在磁盘中保存的,关闭程序不会丢失数据。
- 重复添加多次,会不会添加多个相同的值?
会。一条语句就是添加一个值:
stu_name.insert(2,'小军') stu_name.insert(2,'小军') #结果为[x,x,'小军','小军',x]
#改:
直接赋新值,覆盖原值:
stu_name[5]='孔垂顶'
#删:
- 使用.pop()方法:
.pop()方法默认删的是最后一个元素。
stu_name.pop()#删除最后一个元素 stu_name.pop(4)#删除指定下标的元素
- 使用.remove()方法:
stu_name.remove('小军')#删除指定的元素,如果有一样的元素,只会删掉第一个
- 使用del方式:
del stu_name[-1]#下标从右往左数,-1代表最后一个,-2代表倒数第二个
区别:
- .pop()里面是元素的下标,而.remove()里面是元素。
- .pop()里面如果写的是不存在的下标,则运行会报错。
- 如果存在多个相同的元素,.remove()只会删除第一个。
- 如果想删除多个元素,就需要用到列表循环了。
下标:
- 下标从右往左数,-1代表最后一个,-2代表倒数第二个;
-
下标从左往右数,0代表第一个,1代表第2个。
#查:
- 指定下标查:
my_list=['小黑','小白',1,1,2,1.5] print(my_list[-1]) print(my_list[0])
- 使用.index()方法查询指定元素的下标:
print('index方法:',my_list.index(3))#查找下标的元素
使用.index()方法,如果输入不存在的下标,则执行会报错。
- 使用.count()方法查询某个元素在list里出现的次数:
print(my_list.count(5))#查询某个元素在list里面出现的次数
.count()的应用场景:可以用于校验用户名
.count()里面是元素,而不是下标!
2、反转
使用.reverse()方法:
print('reverse:',my_list.reverse())#结果是None print(my_list)#.reverse()本身不会给出结果,需要打印列表
-
.reverse()本身不会给出结果,没有返回值,需要打印列表
3、清空列表
使用.clear()方法:
my_list.clear()#清空整个list
4、排序
- 使用.sort()方法,默认为升序排序:
nums.sort()#排序,默认升序
- 使用.sort()方法,指定reverse=True,则降序排列:
nums.sort(reverse=True)#排序,如果指定了reverse=True,那么就降序排列了
- 使用.reverse()方法,降序排序:
nums.reverse()
5、将其他列表里的元素加入到本列表中
使用.extend()方法:
nums.extend(my_list)#把一个list里面的元素加入到nums列表里面
6、合并列表
使用“+”进行列表合并:
new_list=nums+my_list
## extend和+的区别:extend是将my_list的内容加入到nums里;而+是nums和my_list内容不变,重新建立一个新的list。
7、复制列表
使用“*”进行列表复制:
print(new_list*3) #复制3个new_list
8、取列表长度,也就是list里面元素的个数
使用len()方法:
passwords =['123456','123123','7891234','password'] print(len(passwords)) #取长度,也就是list里面元素的个数
三、列表应用
#校验手机号是否存在,使用.count()或 in not in都可以
users =[]
for i in range(5): username=input('请输入用户名:') #如果用户不存在的话,就说明可以注册 # if users.count(username)>0: #关键字in not in-------------------------------------------- if username not in users: print('用户未注册,可以注册') users.append(username) else: print('用户已经被注册')
四、数组
nums1=[1,2,3] #一维数组 nums2=[1,2,3,[4,56]] #二维数组 nums=[1,2,3,4,['a','b','c','d','e',['一','二','三']],['四','五']] #三维数组
nums4=[1,2,3,4,['a','b','c','d','e',['一','二','三',[1,2,3]]]]#四维数组
- 多维数组取值:
三维数组取“五”:print(nums[-1][-1])
四维数组取“2”:print(nums4[-1][-1][-1][1])
五、列表循环
-
原理
#循环list取值 count=0 #最原始的list取值方式,是通过每次计算下标来获取元素的 while count<len(passwords): s=passwords[count] print('每次循环的时候',s) count+=1
-
利用元素下标进行循环
index = 0 for p in passwords:#for循环直接循环一个list,那么循环的时候就是每次计算下标获取元素 print('每次循环的值'+p) passwords[index]='abc_'+p index+=1 print(passwords)
Python中的列表循环内置了列表下标,因此只用一个变量p就可以,p就是每次取下标时对应的元素值。
-
使用enumerate()枚举函数
使用enumerate()函数,会自动将list的下标和元素都显示出来:
for index,p in enumerate(passwords):#使用枚举函数时,它会帮你计算下标和元素 passwords[index]='abc_'+p print('enumerate每次循环的时候',index,p) print(passwords)
-
列表循环删除元素
-
循环删list元素的时候,会导致下标错位:
1、现象:
l=[1,1,1,2,3,4,5] #1,1,2,3,4,5 #0 1 2 3 4 5 6 for i in l: if i%2!=0: l.remove(i) #.remove()里面是元素;.pop()里面是下标 print(l) #结果为[1,2,4] #循环删list元素的时候,会导致下标错位
2、解决方法:
l1=[1,1,1,2,3,4,5] #1,1,2,3,4,5 #0 1 2 3 4 5 6 l2=[1,1,1,2,3,4,5] for i in l2: #使用l2中的元素判断,删除l1里的元素,由于l1没有参与判断,因此下标不会错位 if i%2!=0: l1.remove(i) print(l) #结果为[2,4]
循环删除列表元素时,要定义两个相同的列表,一个判断,另一个删除。
- 存址方式:
列表中:
1、现象:
l1=[1,1,1,2,3,4,5] #1,1,2,3,4,5 #0 1 2 3 4 5 6 l2=l1 for i in l2: if i%2!=0: l1.remove(i) print(l1) #结果为[1,2,4] #l1和l2其实指向的是同一块内存地址,因此删除l1的元素时,l2也会跟着变
2、原因:
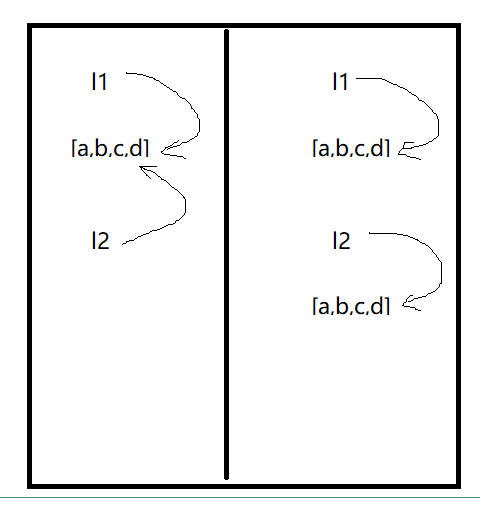
字符串中:
1、现象:
a='tanailing' b=a a='niuniu' print(b)#结果为tanailing print(a)#结果为niuniu
2、原因:
- 字符串是直接开辟新的内存空间,不会共用一块内存空间,因此修改了a的内容后,b不会变。
六、深拷贝与浅拷贝
1、现象:
l1=[1,1,1,2,3,4,5] #1,1,2,3,4,5 #0 1 2 3 4 5 6 l2=l1 #浅拷贝 for i in l2: if i%2!=0: l1.remove(i) print(l1) #打印内存地址 print(id(l1)) #结果为:1986281423432 print(id(l2)) #结果为:1986281423432
2、用法:
import copy #引入copy模块 l1=[1,1,1,2,3,4,5] #1,1,2,3,4,5 #0 1 2 3 4 5 6 l2=l1 #浅拷贝方式1 l4=l1.copy() #浅拷贝方式2 l3=copy.deepcopy() #深拷贝 #打印内存地址 print(id(l1)) #结果:2629934030152 print(id(l2)) #结果:2629934030152 print(id(l3)) #结果:2629934028872
3、区别:
- 浅拷贝内存地址不变,深拷贝内存地址改变。
- 循环删除列表元素时,使用深拷贝方式。
七、切片
1、range()生成器
就是list取值的一种方式。
- 生成器range(),用于写列表的范围,如果只写一个数,就表示从0开始,到写入的值-1:
l=list(range(10))#生成的是[0,1,2,3,4,5,6,7,8,9]
- 如果写入范围,则是从写入的第一个数值开始,从写入的第二个数-1结束:
l=list(range(1,11)) l=['a','b','c','d','e','j','k','l','m','n','o'] # 0 1 2 3 4 5 6 7 8 9 10
print(l[2:8])#顾头不顾尾 print(l[:5])#如果冒号前面没写的话,代表从0开始取的 print(l[4:])#如果冒号后面没写的话,代表取到最后 print(l[:])#如果冒号前后都没写的话,代表取全部
切片操作的特点:
- 顾头不顾尾
- 使用range()生成器时,如果冒号前面没写的话,代表从0开始取元素
- 使用range()生成器时,如果冒号后面没写的话,代表取到最后的元素
- 如果冒号前后都没写的话,代表取全部
2、 步长
步长是从自己元素开始,再走几步到想要的元素:
nums=list(range(1,11)) print(nums[1::2])#打印偶数 #1 2 3 4 5 6 ...10 print(nums[::2])#打印奇数 print(nums[::-2]) #取偶数,从右往左取值
步长特点:
- 如果步长是正数的话,就从前往后开始取值;
- 如果步长是负数的话,就从后往前开始取值,类似于reverse()。