1.Solr7.1.0 安装部署(centos7)
Solr7.1.0为目前的最新版,安装环境需要jdk1.8 或者更高,容器我用的tomcat,也建议tomcat8.0或者更高
1.1、下载solr7.1.0与tomcat8,JDK没有安装的话,可以百度下
1 mkdir -p /usr/local/tools 2 cd /usr/local/tools 3 wget http://archive.apache.org/dist/lucene/solr/7.1.0/solr-7.1.0.zip 4 wget http://mirrors.shuosc.org/apache/tomcat/tomcat-8/v8.5.24/bin/apache-tomcat-8.5.24.tar.gz
1.2、新建目录存放solr与tomcat
1 mkdir -p /usr/local/tools/2 cd /usr/local/tools/
解压第一步中下载的源文件
1 tar -zxvf /usr/local/tools/apache-tomcat-8.5.24.tar.gz 2 mv /usr/local/tools/apache-tomcat-8.5.24 tomcat 3 unzip -oq solr-7.1.0.zip -d /usr/local/tools/
新建solr配置存放目录:
mkdir solr_home
完成之后如下图:

1.3、将运行solr7所需的文件以及jar复制到tomcat中
cd /usr/local/tools/tomcat/webapps/
可以选择将不需要项目的都删掉
rm -rf *
mkdir solr
cd solr
接下来复制solr运行需要的文件
cp -r /usr/local/tools/solr7.1.0/server/solr-webapp/webapp/* /usr/local/tools/tomcat/webapps/solr cp -r /usr/local/tools/solr7.1.0/server/lib/ext/* /usr/local/tools/tomcat/wenapps/solr/WEB-INF/lib/ cp -r /usr/local/tools/solr7.1.0/server/lib/metrics*.* /usr/local/tools/tomcat/webapps/solr/WEB-INF/lib/ cp -r /usr/local/tools/solr7.1.0/dist/solr-dataimporthandler-* /usr/local/tools/tomcat/webapps/solr/WEB-INF/lib/
日志配置:
mkdir -p /usr/local/tools/tomcat/webapps/solr/WEB-INF/classes
cp /usr/local/tools/solr7.1.0/server/resources/log4j.properties /usr/local/tools/tomcat/webapps/solr/WEB-INF/classes/
指定solr的配置目录,修改两点,放开env-entry,注释掉security-constraint
vim WEB-INF/web.xml,修改后的如下: 

接下来配置solr运行的配置
cd /usr/local/tools/solr_home/ cp -r /usr/local/tools/solr7.1.0/server/solr/* . cp -r /usr/local/tools/solr7.1.0/contrib/ . cp -r /usr/local/tools/solr7.1.0/dist/ .
1.4、修改tomcat端口,并启动,这块不多说,启动之后在浏览器输入:http://ip:port/solr/index.html,可看到管理页面,如下:

1.5、新建Core,solr存放的字段和索引都需要自定义,这里core就是存放这些自定义东西的地方。网上有些说要在管理界面add,其实不用,直接在手动配置就行。
1 cd /usr/local/tools/solr_home/ 2 mkdir -p spc_core/conf/ 3 cd spc_core/conf/ 4 cp -r /usr/local/tools/solr7.1.0/server/solr/configsets/_default/conf/* .
修改jar的相对目录:
vim solrconfig.xml

返回上一级:cd ..
新建data目录,
mkdir data
新建core.properties文件:
vim core.properties
内容如下:
name=spc_core config=conf/solrconfig.xml schema=conf/schema.xml dataDir=data

1.6、重启tomcat,再访问首页,就可以选择我们新建的core了,后面再建core,可以直接复制这一份改改。

1.7、添加中文分词器,我用的IK,以此为例
下载IK分词器包。
链接:https://pan.baidu.com/s/1kWWJ7mv 密码:j8i4
下载解压之后,两个jar包复制到WEB_INF/lib/目录

修改/opt/solr7/solr_home/spc_core/conf目录下的managed-schema
vim managed-schema,自定义IK的fieldType,再将需要分词的field指定IK分词器
<fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>

重启tomcat,我们来对比下IK分词器与默认text分词器之间的区别
默认分词器:
IK分词器:
可以看到,IK分词还挺准的,默认分词器完全不能区分中文~~


1.8.通过配置文件,添加数据导入(DataImport)插件,从数据库导入数据
1.8.1.创建一个数据库,使用课前提供的items.sql导入数据

表明:items,有三个字段:it、title、price

1.8.2.打开配置文件:core1/conf/solrconfig.xml ,添加导入数据的插件
A:添加插件依赖的jar:
<lib dir="${solr.install.dir:../../}/contrib/dataimporthandler/li/b" regex=".*.jar" />
<lib dir="${solr.install.dir:../../}/dist/" regex="solr-dataimporthandler-d.*.jar" />
注意,相对路径需要跟你的dist所在位置一致!
B:配置导入数据处理请求Handler,并且指定该Handler的配置文件名称
<requestHandler name="/import" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <!-- 这个插件Handler的配置文件名称 --> <str name="config">db-data-config.xml</str> </lst> </requestHandler>
1.8.3.在core1/conf/下创建新的配置文件:db-data-config.xml,配置数据库信息

1 <?xml version="1.0" encoding="UTF-8" ?> 2 <dataConfig> 3 <dataSource 4 type="JdbcDataSource" 5 driver="com.mysql.jdbc.Driver" 6 url="jdbc:mysql://localhost:3306/solr" 7 user="root" 8 password="123"/> 9 <document> 10 <entity name="item" query="select id,title,price from items"></entity> 11 </document> 12 </dataConfig>
1.8.4.打开配置文件:core1/conf/schemal.xml,添加字段信息

1.8.5.在tomcat的solr服务中添加mysql依赖
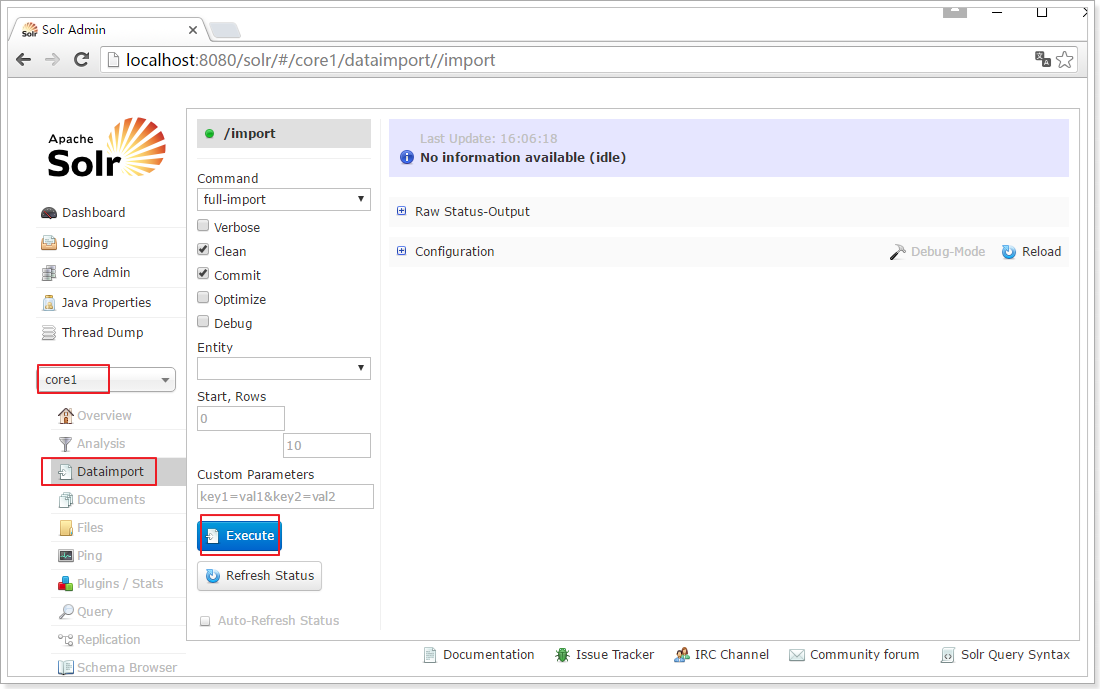
1.8.6.重启tomcat,进入Solr管理页面,到core1中的DataImport界面中:
2、SolrJ的使用
2.1、概述
SolrJ是Apache官方提供的一套Java开发的,访问Solr服务的API,通过这套API可以让我们的程序与Solr服务产生交互,让我们的程序可以实现对Solr索引库的增删改查!
SolrJ的官方wiki地址:https://wiki.apache.org/solr/Solrj
2.2、使用SolrJ添加或修改索引库数据
2.2.1、添加依赖

2.2.2、以Document形式添加或修改数据
1 /*
2 * 演示:SolrJ创建和修改索引
3 */
4 @Test
5 public void testWrite() throws Exception{
6 // 连接Solr服务器,注意:路径中一定不要有#
7 HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr/core2");
8
9 // 创建要添加的文档信息
10 SolrInputDocument doc = new SolrInputDocument();
11 // 添加字段
12 doc.addField("id", 15L);
13 doc.addField("title", "8848钛金手机,高端大气上档次");
14 doc.addField("price", 199900);
15
16 // 把文档添加到服务器
17 server.add(doc);
18 // 提交
19 server.commit();
20 }
2.2.3、使用注解和JavaBean添加或修改数据
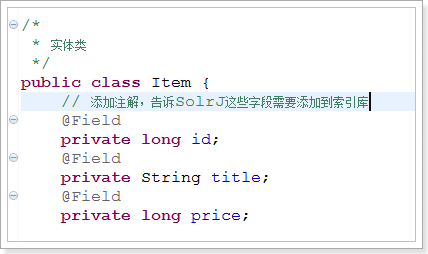
2.2.3.1.给实体类添加注解
2.2.3.2.创建或修改索引
1 /*
2 * 演示:SolrJ以JavaBean的形式创建和修改索引
3 */
4 @Test
5 public void testWrite2() throws Exception{
6 // 连接Solr服务器,注意:路径中一定不要有#
7 HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr/core2");
8
9 // 创建商品对象
10 Item item = new Item();
11 item.setId(16);
12 item.setTitle("Duang手机,加了特效,你值的拥有");
13 item.setPrice(88900);
14
15 // 把对象添加到服务
16 server.addBean(item);
17 // 提交
18 server.commit();
19 }
2.3、使用SolrJ删除索引库数据
1 /*
2 * 演示:SolrJ删除索引
3 */
4 @Test
5 public void testDelete() throws Exception{
6 // 连接Solr服务器,注意:路径中一定不要有#
7 HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr/core2");
8
9 // 根据ID删除索引
10 // server.deleteById("16");
11
12 // 根据查询语句删除,如果这里传的是*:*,那么会删除所有
13 server.deleteByQuery("*:*");
14
15 // 提交
16 server.commit();
17 }
2.4、使用SolrJ查询索引库数据
2.4.1、以Document形式返回查询结果
1 /*
2 * 演示:SolrJ查询索引,返回Document格式的结果
3 */
4 @Test
5 public void testQuery() throws Exception {
6 // 连接Solr服务器,注意:路径中一定不要有#
7 HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr/core2");
8 // 创建查询对象
9 SolrQuery query = new SolrQuery("title:华为");
10 // 执行查询,获取响应
11 QueryResponse response = server.query(query);
12 // 获取结果的文档集合
13 SolrDocumentList list = response.getResults();
14 System.out.println("本次共搜索到" + list.size() + "条数据");
15 for (SolrDocument document : list) {
16 // 取出结果
17 System.out.println("id: " + document.getFieldValue("id"));
18 System.out.println("title: " + document.getFieldValue("title"));
19 System.out.println("price: " + document.getFieldValue("price"));
20 }
21 }
2.4.2、以JavaBean形式返回查询结果
1 /*
2 * 演示:SolrJ查询索引,返回JavaBean格式的结果
3 */
4 @Test
5 public void testQuery2() throws Exception {
6 // 连接Solr服务器,注意:路径中一定不要有#
7 HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr/core2");
8 // 创建查询对象
9 SolrQuery query = new SolrQuery("title:华为");
10 // 执行查询,获取响应
11 QueryResponse response = server.query(query);
12 // 解析响应,获取JavaBean集合
13 List<Item> items = response.getBeans(Item.class);
14 System.out.println("共搜索到" + items.size() + "条数据");
15 for (Item item : items) {
16 System.out.println("id: " + item.getId());
17 System.out.println("title: " + item.getTitle());
18 System.out.println("price: " + item.getPrice());
19 }
20 }
2.4.3、SolrQuery对象的高级查询设置
在创建SolrQuery时,我们填写的Query语句,可以有以下高级写法:
1、匹配所有文档:*:*
2、布尔操作:AND、OR和NOT布尔操作(推荐使用大写,区分普通字段)
3、子表达式查询(子查询):可以使用“()”构造子查询。 比如:(query1 AND query2) OR (query3 AND query4)
4、相似度查询:
(1)默认相似度查询:title:appla~ ,此时编辑举例是2
(2)指定编辑举例的相似度查询:对模糊查询可以设置编辑举例,可选0~2的整数。
5、范围查询(Range Query):Lucene支持对数字、日期甚至文本的范围查询。结束的范围可以使用“*”通配符。
(1)日期范围(ISO-8601 时间GMT):a_begin_date:[1990-01-01T00:00:00.000Z TO 1999-12-31T24:59:99.999Z]
(2)数字:salary:[2000 TO *]
(3)文本:entryNm:[a TO a]
6、日期匹配:YEAR, MONTH, DAY, DATE (synonymous with DAY) HOUR, MINUTE, SECOND, MILLISECOND, and MILLI (synonymous with MILLISECOND)可以被标志成日期。
(1)r_event_date:[* TO NOW-2YEAR]:2年前的现在这个时间
(2)r_event_date:[* TO NOW/DAY-2YEAR]:2年前前一天的这个时间
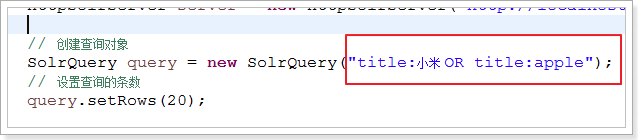
2.4.3.1、布尔查询
2.4.3.2、相似度查询

2.4.3.3、数值范围查询

2.4.4、SolrQuery实现排序
1 /*
2 * 演示:SolrJ查询索引。并且进行排序
3 */
4 @Test
5 public void testSortQuery() throws Exception {
6 // 连接Solr服务器,注意:路径中一定不要有#
7 HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr/core2");
8 // 创建查询对象
9 SolrQuery query = new SolrQuery("title:华为");
10 // 所有的高级的查询参数和功能,都是通过SolrQuery对象来进行的
11
12 // 排序
13 query.setSort("price", ORDER.desc);
14
15 // 执行查询,获取响应
16 QueryResponse response = server.query(query);
17 // 解析响应,获取JavaBean集合
18 List<Item> items = response.getBeans(Item.class);
19 System.out.println("共搜索到" + items.size() + "条数据");
20 for (Item item : items) {
21 System.out.println("id: " + item.getId());
22 System.out.println("title: " + item.getTitle());
23 System.out.println("price: " + item.getPrice());
24 }
25 }
2.4.5、SolrQuery实现分页
1 /*
2 * 演示:SolrJ查询索引。并且进行分页
3 */
4 @Test
5 public void testSortQuery() throws Exception {
6 // 连接Solr服务器,注意:路径中一定不要有#
7 HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr/core2");
8 // 创建查询对象
9 SolrQuery query = new SolrQuery("*:*");
10
11 // 分页参数:
12 int pageSize = 5;// 每页条数
13 int pageNum = 3;// 当前页
14 int start = (pageNum - 1) * pageSize;
15 query.setStart(start);// 设置起始编号
16 query.setRows(pageSize);// 设置每页条数
17
18 // 执行查询,获取响应
19 QueryResponse response = server.query(query);
20 // 解析响应,获取JavaBean集合
21 List<Item> items = response.getBeans(Item.class);
22 System.out.println("共搜索到" + items.size() + "条数据");
23 for (Item item : items) {
24 System.out.println("id: " + item.getId());
25 System.out.println("title: " + item.getTitle());
26 System.out.println("price: " + item.getPrice());
27 }
28 }
2.4.6、SolrQuery实现高亮显示
1 /*
2 * 演示:SolrJ查询索引。并且进行高亮显示
3 */
4 @Test
5 public void testHighlighterQuery() throws Exception {
6 // 连接Solr服务器,注意:路径中一定不要有#
7 HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr/core2");
8 // 创建查询对象
9 SolrQuery query = new SolrQuery("title:手机");
10 // 设置查询条数
11 query.setRows(20);
12 // 开启高亮显示
13 query.setHighlight(true);
14 query.setHighlightSimplePre("<em>");// 设置前置标签
15 query.setHighlightSimplePost("</em>");// 设置后置标签
16 query.addHighlightField("title");// 设置高亮的字段
17
18 // 执行查询,获取响应
19 QueryResponse response = server.query(query);
20 // 解析响应,获取高亮数据
21 // 这里返回的结果有两层Map,外层的Map,键是一个文档的ID,值是所有其它高亮字段的信息,又是一个Map
22 // 内层Map:键是某个高亮字段的名称,值就是这个字段的值,只不过这个值放到一个List中。
23 Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();
24 // 获取非高亮结果
25 List<Item> items = response.getBeans(Item.class);
26 for (Item item : items) {
27 System.out.println("id:" + item.getId());
28 // 根据ID获取当前商品的所有高亮字段的Map集合,然后从集合中获取高亮字段的值,然后获取其中第1个
29 System.out.println(highlighting.get(item.getId()+"").get("title").get(0));
30 System.out.println("price:" + item.getPrice());
31 }
32 // // 先获取所有的键,其实就是所有文档的ID集合
33 // Set<String> ids = highlighting.keySet();
34 // // 遍历取出每一个ID
35 // for (String id : ids) {
36 // System.out.println("id: " + id);
37 // // 根据ID取出这个文档的其它字段形成的Map集合
38 // Map<String, List<String>> fields = highlighting.get(id);
39 // // 从字段Map集合中,取出对应的字段,得到的是一个List,而我们只要List的第1条数据
40 // System.out.println("title: " + fields.get("title").get(0));
41 // }
42 }