什么叫不同分布的数据
举几个例子来说明
例子1,要训练一个手机端的猫识别器,现在有 10000 张手机端的照片,并且被人为标记为是不是猫,然后我们可以从互联网上得到 200000 张猫咪图片,网络上的照片和移动手机端的照片就属于不同分布;
例子2,要训练一个语音识别系统,将某个地址转换成语音,现在有 20000 个 用户说出地址 的样本,还有 500000 个其他音频样本,内容随机,这也是不同分布的数据;
在早期的机器学习中,由于数据有限,我们通常只有一个同分布的数据;
但是在大数据时代,我们可以获得大型的数据集,比如猫的网络图片,即使他们属于不同的分布,我们仍然希望使用它来学习,因为它可以提供大量的信息;
当然这需要比较复杂的模型,比如大规模的神经网络,此时添加不同分布的数据也很可能提升模型的性能
如何用不同分布的数据来训练模型
以例子1为例,通常我们可能会把这两种数据混合在一起,随机打乱,这样整个数据集仍然是同一分布,但是不建议这样做,为什么呢?
首先明确我们的目标,我们是想建立一个手机端的猫识别器,我们预测的目标是手机照片,如果混在一起,测试集中 90% 以上的数据都来自互联网,模型的表现不能反映我们期望数据分布的表现;
所以记住这个建议:验证集和测试集的选择要符合我们期望的数据分布
正确的做法是:我们拿出 5000 张(一半)手机照片作为验证集合测试集,然后把剩下的 205000 张作为训练集,这样我们的验证和测试集都能反映我们的期望分布,
虽然训练集有两种分布的数据,但我们可以通过某种手段来使得模型学到手机端的特征,而把网络端只作为参考
那是不是任何情况下都可以使用不同分布的数据呢?
显然不是;
这需要依赖一个事实,就是存在一个“理想模型”能够对不同分布的数据进行很好的识别,以猫识别器为例,人类就是一个“理想模型”,输入图片,人类就能判断是不是猫,而不需要知道它来自手机还是网络;
在存在“理想模型”的情况下,添加不同分布的数据有如下影响:
1. 好处:能够提供更多猫的信息,包括猫的品种、姿势等等,这能让神经网络学到更多猫的特性,而这种特性可能和手机端的并无差别;
2. 风险:可能使得神经网络花费大量的规模来学习网络图片,因为网络图片占比非常大,如果模型学到的网络图片的性质与手机端差别较大,这对手机端的识别无疑是有害的,对应我们关心的分布,可能降低模型的性能
所以,如果我们认为模型无法从另一种分布的数据上学到有用特征,那应该果断放弃
给数据添加权重
上文讲到如果我们添加了不同分布的数据,则存在降低模型性能的风险,
以例子1为例,网络图片:手机图片=40:1,从理论上讲,如果模型足够大,训练时间足够长,可以得到一个模型能够很好的识别不同分布的图片;但实际中并没有足够的资源,这意味着我们需要妥协;
此时我们可以给数据添加权重
为了方便说明,我们以均方误差为例(尽管是分类问题,但是道理是一样的)
模型的目标是最小化损失函数
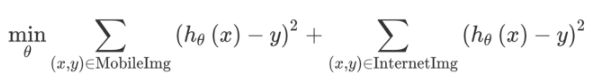
用如下方式进行优化
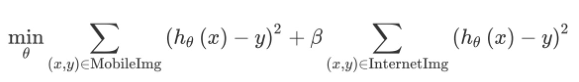
如果 β=1/40,则手机照片和网络照片权重相同,当然你可以根据需要选择不同的值,甚至其他方式
添加小于1的权重,使得模型不需要在两种分布的数据上都表现的很好,这样可以减少训练的时间
不同分布数据模型调优
假设我们在不同分布数据上的模型表现不好,如:
1. 在训练集上表现不佳,高偏差
2. 在训练集上表现可以,但在与训练集同分布的数据上表现不佳,高方差
3. 在训练集上表现可以,但在与测试集同分布的数据上表现不佳,这种情况也在情理之中,这种问题被称为数据不匹配
有没有发现,我们多了一种与训练集同分布的数据,所以判断不同分布数据模型的表现,需要把数据分为 4 部分
- 训练集:来自手机图片和网络图片
- 训练验证集:来自和训练集同分布的数据
- 测试验证集:来自和测试集同分布的数据
- 测试集:来自手机图片
假设模型表现如下
训练集错误率 1% 训练验证集错误率 5% 测试验证集错误率 5%
高方差,之前的方法可以解决
假设模型表现如下
训练集错误率 5% 训练验证集错误率 6% 测试验证集错误率 6%
高偏差,之前的方法可以解决
假设模型表现如下
训练集错误率 10% 训练验证集错误率 11% 测试验证集错误率 20%
这显然存在高偏差与数据不匹配问题,在训练集分布上表现无差异,
这表明两种分布的数据相差甚远
解决数据不匹配问题
1. 尝试理解数据属性在训练集和测试集分布上的差异
2. 尝试获取更多的训练数据,以便是算法更好的匹配测试集分布上的数据
例如我对语言识别系统进行误差分析:手动遍历 100 个样本,尝试理解算法错在哪,假如我们发现,大部分测试集是在车里录制的,噪声很大,而训练集都是在安静环境下录制;
这就需要我们获取更多的训练数据,包括在车里录制的样本,
误差分析的目的就是了解训练和测试集之间的差异,但不幸的是,我们可能无法获取更多的数据,或者无法找到差异点,此时我们可能会考虑人工合成数据
人工合成数据的风险
以上面的论述为例,我们需要车里录制的音频样本,我们可以下载一些车辆噪声,然后把它与安静环境下的音频进行合成,听起来就像是在车里录制的;
然后构建一个对人而言真实的数据比构建一个对算法而言真实的数据要简单的多,
比如,我们有一个 1000 小时的音频,只有 1 个小时的汽车噪声,那么我们把这 1 小时的噪声循环加在 1000 小时音频内,对人而言,都是听不清而已,但对算法而言,可能“过拟合”这 1 个小时的噪声;
再如,我们有 1000 个音频样本,只有 10 个不同汽车的噪声,合成之后,人听起来一样,但是算法可能“过拟合”这 10 辆车的噪声;
延伸一下,在类别不均衡问题中,采用过采样的方式也会过拟合,道理类似上面
总结
在不同分布的数据上进行建模,需要注意几点
1. 验证和测试集的选择要与目标数据同分布
2. 两种数据有很强的关联性,可以考虑是否存在一个“理想模型”,能够很好的识别两种数据,而不需要知道数据来自哪个分布
3. 可以采用数据加权方式,降低模型训练时间
4. 利用数据不匹配的概念对模型进行调优
参考资料:
吴恩达:完整翻译版《机器学习要领》