加载模块:
from django.core import serializers
# get请求通过HttpResponse方式返回数据
class Books2(APIView):
def get(self,request):
book_list=models.Book.objects.all() # 查询所有数据
# serializers.serialize使用django内置的serialize方法,把QuserySet对象转换为json格式
res = serializers.serialize("json",book_list)
return HttpResponse(res)
前端数据展示:

缺点:会把一些无用的数据全部展示出去,包括库名字,表名字,不能够展示单独的字段信息
序列化组件:
Python中的对象转换为json格式的字符串
注意:前后端分离,不能只能直接反序列,json不能序列化对象,只能序列化字典和列表
添加model(生成数据库表格字段)
class Book(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=32) price = models.DecimalField(max_digits=5, decimal_places=2) publish_date = models.DateField(null=True) xx=models.IntegerField(choices=((0,'文学类'),(1,'情感类')),default=1,null=True) publish = models.ForeignKey(to='Publish',to_field='id',on_delete=models.CASCADE,null=True) authors=models.ManyToManyField(to='Author') def __str__(self): return self.name class Author(models.Model): id = models.AutoField(primary_key=True) age = models.IntegerField() class Publish(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=32) city = models.CharField(max_length=32) email = models.EmailField() def __str__(self): return self.name
新增一个文件:
例如:app01Serializer.py
from rest_framework import serializers class BookSerializer(serializers.Serializer): name=serializers.CharField() # price=serializers.DecimalField() price=serializers.CharField()
其中name和price都是表字段
在视图文件views.py中创建类
添加模块:
from rest_framework.views import APIView from rest_framework.response import Response from app01 import models from app01.app01Serializer import BookSerializer
# 把对象转换成json字符串
class Books(APIView): def get(self,request): books = models.Book.objects.all() # 当序列化一条数据的时候many=True可以不写,序列化多条数据的时候(也就是queryset对象)必须要写 bookser=BookSerializer(books,many=True) print(type(bookser.data)) return Response(bookser.data)
前端访问:自带页面,只会展示我在app01Serializer.py文件中定序列化的字段
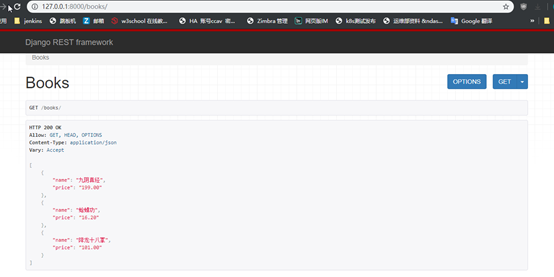
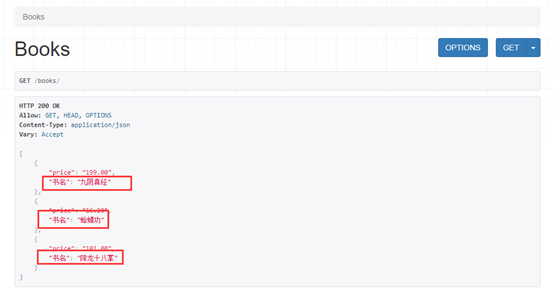
设置别名:避免前端直接看到数据的字段名:
# 指定source='name',表示序列化模型表中的name字段,重命名为name5或者别的名字(自定义)
修改app01Serializer.py文件

原字段是name,设置成别名为'书名'
重新启动服务web查看获取的数据样式:
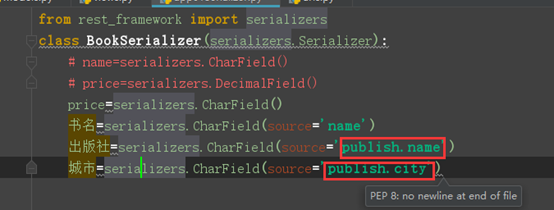
根据book表中的publish_id字段和publish(出版社)的id字段进行关联,查询显示该书对应的出版社和城市
和上面设置别名一样,通过本表中的关联字段点方法获取关联表的指定字段
查看效果:

Source不仅可以指定一个字段,还可以指定一个方法
表格字段设置:
xx=models.IntegerField(choices=((0,'文学类'),(1,'情感类')),default=1,null=True)
在app01Serializer.py文件中设置xx字段序列化设置:
book_type = serializers.CharField(source='get_xx_display')
查看数据展示效果:

在数据库存储的是对应的选项,数据展示的是对应的值
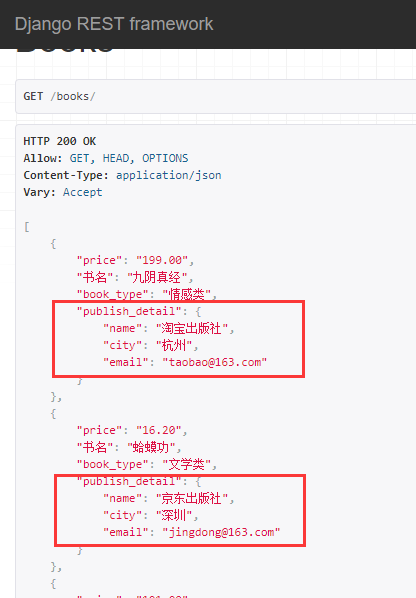
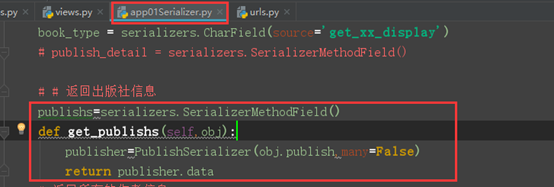
序列化出版社的详细信息,指定SerializerMethodField之后,可以对应一个方法,返回什么内容,publish_detail就是什么内容
publish_detail = serializers.SerializerMethodField() def get_publish_detail(self,obj): return {'name':obj.publish.name,'city':obj.publish.city,'email':obj.publish.email}
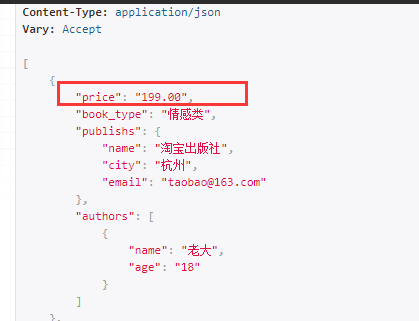
展示效果:
返回作者的信息:
方式一:
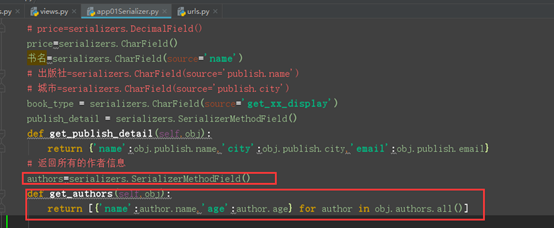

方式二:

Write_only与read_only

当设置write_only=True序列化的时候,该字段不显示
当设置read_only=True 反序列化的时候,该字段不传
设置深度打印表及关联表的全部信息:

前端展示数据(depth=1,深度不建议超过10,个人建议不超过3):

数据显示:
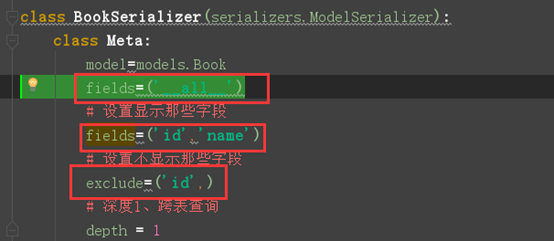
Fields设置显示数据,可以显示全部也可以显示一部分
Exclude与fields相反,设置不显示的字段
#注意:fields与exclude不能同时使用
继承ModelSerializers序列化类的对象,反序列化
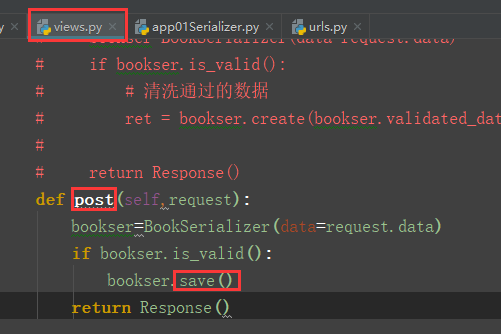
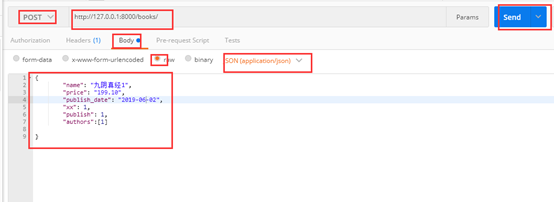
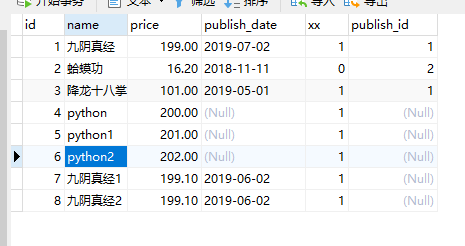
数据新增成功:
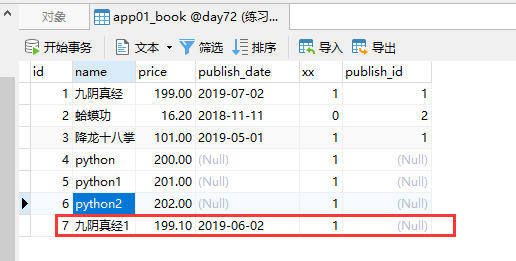
反序列化对数据进行效验:
局部校验:
判断name字段是否是以sb开头

测试插入数据name字段的带有sb开头数据,查看是否插入成功

插入数据成功
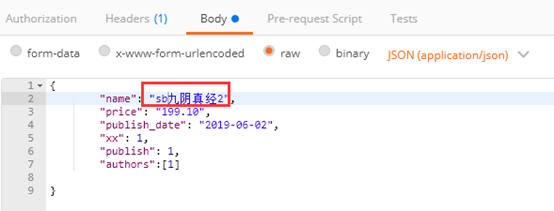
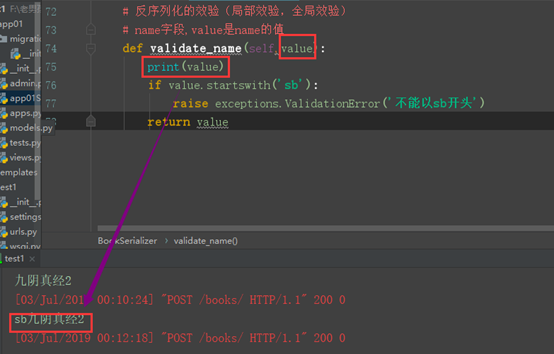
插入数据失败
全局校验:
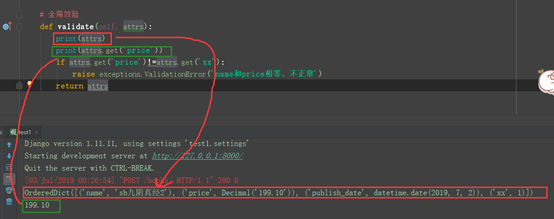
可以针对获取的值进行判断