本博客是MIT的分布式系统课程的课后作业Cos418的GO语言实现思路。由于时间有限,目前只实现了assignment1~2。
在common.go中设置debugEnabled = true,go test时增加-v参数可以获得更多调试信息。
Assignment 1: Sequential Map/Reduce
目标:需要写一个简单的线性执行的mapreduce程序,实现wordcount功能。
Part I: Map/Reduce input and output
在mapreduce目录下执行如下命令:
go test -run Sequential
执行命令后会运行test_test.go中的TestSequentialSingle()函数和TestSequentialMany()函数
以TestSequentialSingle()函数为例:
func TestSequentialSingle(t *testing.T) {
mr := Sequential("test", makeInputs(1), 1, MapFunc, ReduceFunc)
mr.Wait()
check(t, mr.files)
checkWorker(t, mr.stats)
cleanup(mr)
}
makeInputs(1)会生成一个输入文件824-mrinput-0.txt,里面是递增的数字0~99999,一个数字为一行。文件名将作为参数传递给Sequential()。
ManFunc()和ReduceFunc()已经在test_test.go中被定义好,被作为参数传递给Sequential()
func Sequential(jobName string, files []string, nreduce int,
mapF func(string, string) []KeyValue,
reduceF func(string, []string) string,
) (mr *Master) {
mr = newMaster("master")
go mr.run(jobName, files, nreduce, func(phase jobPhase) {
switch phase {
case mapPhase:
for i, f := range mr.files {
doMap(mr.jobName, i, f, mr.nReduce, mapF)
}
case reducePhase:
for i := 0; i < mr.nReduce; i++ {
doReduce(mr.jobName, i, len(mr.files), reduceF)
}
}
}, func() {
mr.stats = []int{len(files) + nreduce}
})
return
}
在Sequential()函数中会调用run()函数,调用时,需要将schedule()函数和finish()函数传递给它:
func (mr *Master) run(jobName string, files []string, nreduce int,
schedule func(phase jobPhase),
finish func(),
) {
mr.jobName = jobName
mr.files = files
mr.nReduce = nreduce
debug("%s: Starting Map/Reduce task %s
", mr.address, mr.jobName)
schedule(mapPhase)
schedule(reducePhase)
finish()
mr.merge()
debug("%s: Map/Reduce task completed
", mr.address)
mr.doneChannel <- true
}
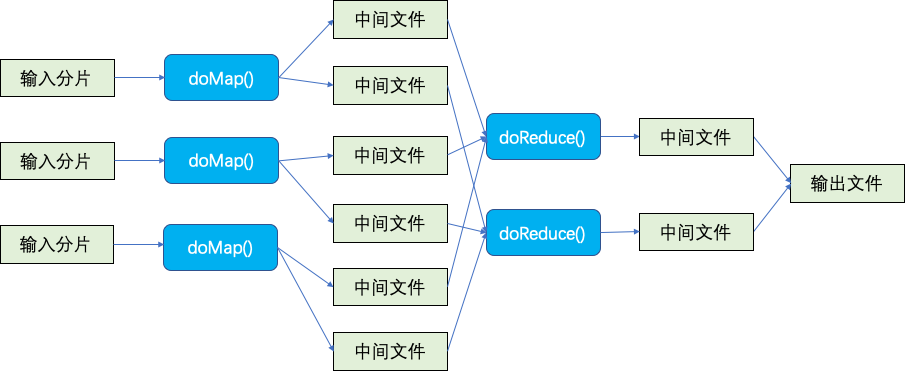
首先,它会通过schedule()函数调度worker来执行map任务,schedule()只通过一个参数判断是Map阶段还是Reduce阶段;所有的map任务都完成后,它会通过schedule()函数调度worker来执行reduce任务;所有的reduce任务都完成后,它会通过finish()函数结束相关工作;最后会调用mr.merge()函数将nreduce个输出文件合并为一个最终输出文件。
此处作为参数传递给run()的schedule()函数就是:
func(phase jobPhase) {
switch phase {
case mapPhase:
for i, f := range mr.files {
doMap(mr.jobName, i, f, mr.nReduce, mapF)
}
case reducePhase:
for i := 0; i < mr.nReduce; i++ {
doReduce(mr.jobName, i, len(mr.files), reduceF)
}
}
}
它会根据输入文件的数目依次串行地调用doMap()方法实现Map功能,每个输入文件分给一个map任务,生成中间键值对;每个map任务又会将这些中间键值对分发给所有reduce任务形成nreduce个中间文件;然后按照nreduce的数量,依次串行地调用doReduce()方法实现Reduce功能。每个调用任务完成时才会进行下一次调用。
由于此处只有一个输入文件和一个reduce任务,所以doMap()和doReduce()只会执行一次。
此处作为参数传递给run()的finish()函数就是:
func() {
mr.stats = []int{len(files) + nreduce}
}
Assignment 1要实现的是domap()函数和doreduce()函数。
doMap()函数需要实现的任务:读取输入文件inFile,调用实现Map功能的函数mapF()。此处的mapF()函数仅仅把文件按单词拆分为切片[]KeyValue(key是单词,value是空)。对这个切片中的每个key,doMap()需要调用ihash()方法并mod nReduce,来选择该键值对放在哪个中间文件中。每个reduce task有一个中间文件,doMap()需要调用common.go的reduceName()方法生成所有中间中间文件的名称:
func reduceName(jobName string, mapTask int, reduceTask int) string {
return "mrtmp." + jobName + "-" + strconv.Itoa(mapTask) + "-" + strconv.Itoa(reduceTask)
}
最终实现的domap()函数:
func doMap(
jobName string, // the name of the MapReduce job
mapTaskNumber int, // which map task this is
inFile string,
nReduce int, // the number of reduce task that will be run
mapF func(file string, contents string) []KeyValue,
) {
dat, err := ioutil.ReadFile(inFile)
if err != nil {
debug("file open fail:%s", inFile)
} else {
kvs := mapF(inFile, string(dat))
partitions := make([][]KeyValue, nReduce)
for _ , kv:= range kvs {
r := int(ihash(kv.Key)) % nReduce
partitions[r] = append(partitions[r], kv)
}
for i := range partitions {
j, _ := json.Marshal(partitions[i])
f := reduceName(jobName, mapTaskNumber, i)
ioutil.WriteFile(f, j, 0644)
}
}
}
其中,partitions的type是[]keyvalue切片,len是nreduce。此处使用json.Marshal()将partitions[i]转换为json。
使用ioutil.WriteFile()进行写入,如果文件存在会清空文件然后写入。
此处只会生成一个中间文件mrtmp.test-0-0:

doReduce()函数需要实现的任务:根据map任务的数量,遍历nMap个中间文件,读取所有的keyvalue对;对所有keyvalue对进行合并和排序;对每对keyvalue调用reduceF,并写入最后的输出文件。
调用common.go的mergeFileName()方法即可生成输出文件名称:
func mergeName(jobName string, reduceTask int) string {
return "mrtmp." + jobName + "-res-" + strconv.Itoa(reduceTask)
}
最终实现的doreduce()函数:
func doReduce(
jobName string, // the name of the whole MapReduce job
reduceTaskNumber int, // which reduce task this is
nMap int, // the number of map tasks that were run ("M" in the paper)
reduceF func(key string, values []string) string,
) {
kvs := make(map[string][]string)
for m := 0; m < nMap; m++ {
fileName := reduceName(jobName, m, reduceTaskNumber)
dat, err := ioutil.ReadFile(fileName)
if err != nil {
debug("file open fail:%s", fileName)
} else {
var items []KeyValue
json.Unmarshal(dat, &items)
for _ , item := range items {
k := item.Key
v := item.Value
kvs[k] = append(kvs[k], v)
}
}
}
// create the final output file
mergeFileName := mergeName(jobName, reduceTaskNumber)
file, err := os.Create(mergeFileName)
if err != nil {
debug("file open fail:%s", mergeFileName)
}
// sort
var keys []string
for k := range kvs {
keys = append(keys, k)
}
sort.Strings(keys)
enc := json.NewEncoder(file)
for _, key := range keys {
enc.Encode(KeyValue{key, reduceF(key, kvs[key])})
}
file.Close()
}
kvs是集合,其key是string,value是[]string
此处使用json.Unmarshal将json转换为[]keyValue切片,再转换为集合存到kvs里;对kvs里所有的key,存到[]string切片里,使用sort.String进行排序。
此处ReduceFunc()中只是打印了key值,没做什么处理。(最后把打印的部分注释掉,否则调式的时候很麻烦)
最后只会生成一个输出文件mrtmp.test-res-0:
最终,所有输出文件合并为一个文件mrtmp.test
TestSequentialMany()的逻辑与TestSequentialSingle()函数类似,不同的是会生成三个输入文件824-mrinput-0.txt~824-mrinput-4.txt,且nreduce=3,所以会生成15个中间文件,最终有3个输出文件mrtmp.test-res-0~mrtmp.test-res-2。master会调用mr.merge()函数将所有输出文件合并为一个文件mrtmp.test。
Part II: Single-worker word count
在main目录下执行如下命令:
go run wc.go master sequential pg-*.txt
master、sequential、pg-*.txt将作为参数传递给wc.go的main()函数。
同样会调用mapreduce.go的Sequential()函数,不同的是这次传递的mapF和reduceF在wc.go目录下,需要自己实现。
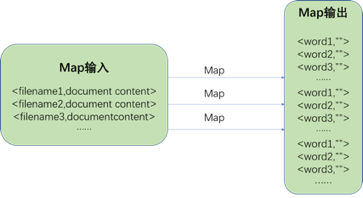
Map输入格式为<filename,document content>,输出格式为list(<word,””> )。处理过程如下图所示:
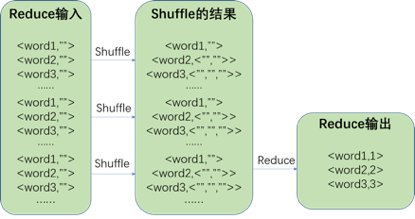
Reduce输入格式为list(<word,””> ),输出格式为list(<word,num>) 。处理过程如下图所示:
mapF()函数需要实现的任务:把输入文件按单词拆分为切片[]KeyValue
func mapF(document string, value string) (res []mapreduce.KeyValue) {
words := strings.FieldsFunc(value, func(r rune) bool {
return !unicode.IsLetter(r)
})
res = []mapreduce.KeyValue{}
for _, w := range words {
res = append(res, mapreduce.KeyValue{w, ""})
}
return res
}
reduceF()函数需要实现的任务:计算values的len,并把数字转换成对应的字符串类型的数字
func reduceF(key string, values []string) string {
return strconv.Itoa(len(values))
}
由于txt文件共16个,nreduce=3,最终产生48个中间文件和3个最终输出文件mrtmp.wcseq-res-0~mrtmp.wcseq-res-2
最终,master会调用mr.merge()函数将所有输出文件合并为一个输出文件mrtmp.wcseq,通过sort命令列举出现最多的几个单词是:
sort -n -k2 mrtmp.wcseq | tail -10 he: 34077 was: 37044 that: 37495 I: 44502 in: 46092 a: 60558 to: 74357 of: 79727 and: 93990 the: 154024
Assignment 2: Distributed Map/Reduce
目标:需要一个master为多个worker安排任务,并处理worker出现的错误。
Part I: Distributing MapReduce tasks
Assignment 1都是串行地执行任务,Map/Reduce最大的优势就是能够自动地并行执行普通的代码,不用开发者进行额外工作。
在Assignment 2里会把任务分配给一组worker thread,在多核上并行进行。worker thread间会用RPC来模拟分布式计算。
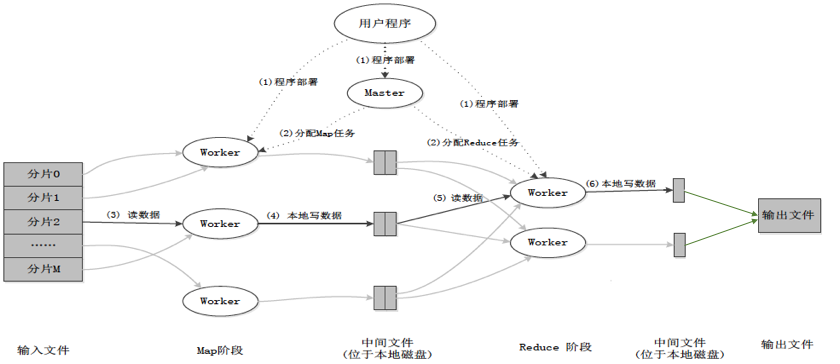
在mapreduce目录下执行:
go test -run TestBasic
执行命令后会运行test_test.go中的testBasic()方法:
func TestBasic(t *testing.T) {
mr := setup()
for i := 0; i < 2; i++ {
go RunWorker(mr.address, port("worker"+strconv.Itoa(i)),
MapFunc, ReduceFunc, -1)
}
mr.Wait()
check(t, mr.files)
checkWorker(t, mr.stats)
cleanup(mr)
}
通过RunWorker()函数启动了两个worker thread,它们会与master进行连接,注册地址并等待任务调度。
通过setup()函数启动了master:
func setup() *Master {
files := makeInputs(nMap)
master := port("master")
mr := Distributed("test", files, nReduce, master)
return mr
}
setup()函数中调用了Distributed()函数,它与此前的Sequential()函数类似,不同的是,它分布式的调度工作:
func Distributed(jobName string, files []string, nreduce int, master string) (mr *Master) {
mr = newMaster(master)
mr.startRPCServer()
go mr.run(jobName, files, nreduce,
func(phase jobPhase) {
ch := make(chan string)
go mr.forwardRegistrations(ch)
schedule(mr.jobName, mr.files, mr.nReduce, phase, ch)
},
func() {
mr.stats = mr.killWorkers()
mr.stopRPCServer()
})
return
}
此处作为参数传递给run()的schedule()函数就是:
func(phase jobPhase) {
ch := make(chan string)
go mr.forwardRegistrations(ch)
schedule(mr.jobName, mr.files, mr.nReduce, phase, ch)
}
其中调用的schedule.go中的schedule()函数就是本次要实现的函数。
此处作为参数传递给run()的finish()函数就是:
func() {
mr.stats = mr.killWorkers()
mr.stopRPCServer()
}
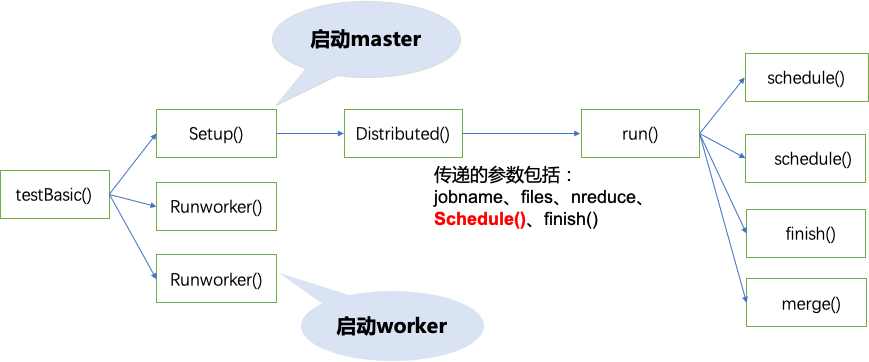
schedule()函数需要实现的任务:获取Workers信息,通过common_rpc.go的call()函数调度worker执行任务;所有任务都被执行完成时才能return。
func (mr *Master) schedule(phase jobPhase) {
var ntasks int
var nios int // number of inputs (for reduce) or outputs (for map)
switch phase {
case mapPhase:
ntasks = len(mr.files)
nios = mr.nReduce
case reducePhase:
ntasks = mr.nReduce
nios = len(mr.files)
}
debug("Schedule: %v %v tasks (%d I/Os)
", ntasks, phase, nios)
stats := make([]bool, ntasks)
currentWorker := 0
for {
count := ntasks
for i := 0; i < ntasks; i++ {
if !stats[i] {
mr.Lock()
numWorkers := len(mr.workers)
fmt.Println(numWorkers)
if numWorkers==0 {
mr.Unlock()
time.Sleep(time.Second)
continue
}
currentWorker = (currentWorker + 1) % numWorkers
Worker := mr.workers[currentWorker]
mr.Unlock()
var file string
if phase == mapPhase {
file = mr.files[i]
}
args := DoTaskArgs{JobName: mr.jobName, File: file, Phase: phase, TaskNumber: i, NumOtherPhase: nios}
go func(slot int, worker_ string) {
success := call(worker_, "Worker.DoTask", &args, new(struct{}))
if success {
stats[slot] = true
}
}(i, Worker)
} else {
count--
}
}
if count == 0 {
break
}
time.Sleep(time.Second)
}
debug("Schedule: %v phase done
", phase)
}
一共会启动ntask个任务。如果是map阶段,ntask则为输入文件数量;如果是reduce阶段,ntask则为nreduce。
此处调用call()函数时需要传递的参数存储在args中,包括Jobname、File(如果是map阶段,则为第i个输入文件名;如果是reduce阶段,可以没有内容)、Phase、TaskNumber(第几个task)、NumOtherPhase(如果是map阶段,则为nreduce;如果是reduce阶段,则为输入文件数量)
每次循环前都会初始化count然后检查全部ntask个任务的执行结果,只有所有task的stats都为true时,count才会减少到0,结束循环。
Part II: Handling worker failures
本部分由于未考虑master的故障所以相对简单(如果考虑的话需要添加持久化存储以保存master的状态),只需要考虑worker的故障。
当1个worker宕机时,master发送的RPC都会失败,那么久需要重新安排任务,将宕机worker的任务分配给其它worker。因此,只有RPC的call返回true时才会将task对应的stats标记为true;若返回false会另选一个worker重试。
RPC调用的失败并不表示worker的宕机,worker可能只是网络不可达,仍然在工作。所以如果重新分配任务可能造成2个worker接受相同的任务并计算。但由于相同的任务生成相同的结果,此情况对最终结果没有影响。
在mapreduce目录下执行:
go test -run Failure
执行命令后会运行test_test.go中的TestOneFailure()函数和TestManyFailures()函数。
前者会启动2个worker,其中一个在执行10个task后会fail;
后者每秒钟启动2个worker,它们在执行10个task后会fail。
Part III: Inverted index generation
本部分要求实现倒排索引功能,即统计出所有包含某个词的文件,并以<单词>: <文件个数> <排序后的文件名列表>的形式输出。
在main目录下执行:
go run ii.go master sequential pg-*.txt
执行过程与此前相同,但本次mapF()函数和reduceF函数需要自己实现。
mapF()函数需要实现的任务:对文件进行分词,返回将单词和文件名组成的key-value对。
func mapF(document string, value string) (res []mapreduce.KeyValue) {
words := strings.FieldsFunc(value, func(c rune) bool {
return !unicode.IsLetter(c)
})
WordDocument := make(map[string]string, 0)
for _,word := range words {
WordDocument[word] = document
}
res = make([]mapreduce.KeyValue, 0)
for k,v := range WordDocument {
res = append(res, mapreduce.KeyValue{k, v})
}
return
}
此处使用strings.FieldsFunc()函数进行分词,单词和文件名组成的key-value对首先需要放到集合WordDocument中,以避免重复。
reduceF()函数需要实现的任务:只需要把单词(key)对应的文件名列表(values)进行排序后,按要求格式<文件个数> <排序后的文件名列表>转为string即可。
func reduceF(key string, values []string) string {
nDoc := len(values)
sort.Strings(values)
var buf bytes.Buffer;
buf.WriteString(strconv.Itoa(nDoc))
buf.WriteRune(' ')
for i,doc := range values {
buf.WriteString(doc)
if (i != nDoc-1) {
buf.WriteRune(',')
}
}
return buf.String()
}
执行如下命令:
head -n5 mrtmp.iiseq A: 16 pg-being_ernest.txt,pg-dorian_gray.txt,pg-dracula.txt,pg-emma.txt,pg-frankenstein.txt,pg-great_expectations.txt,pg-grimm.txt,pg-huckleberry_finn.txt,pg-les_miserables.txt,pg-metamorphosis.txt,pg-moby_dick.txt,pg-sherlock_holmes.txt,pg-tale_of_two_cities.txt,pg-tom_sawyer.txt,pg-ulysses.txt,pg-war_and_peace.txt ABC: 2 pg-les_miserables.txt,pg-war_and_peace.txt ABOUT: 2 pg-moby_dick.txt,pg-tom_sawyer.txt ABRAHAM: 1 pg-dracula.txt ABSOLUTE: 1 pg-les_miserables.txt
即可统计出出现文本数最多的5个单词。
代码在https://github.com/yangyuliufeng/cos418。