需求
求每个小时内用户点击量的TOP3,每五分钟更新一次
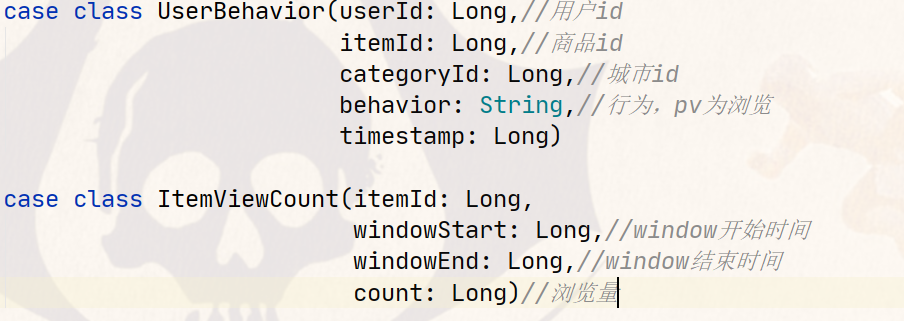
bean:
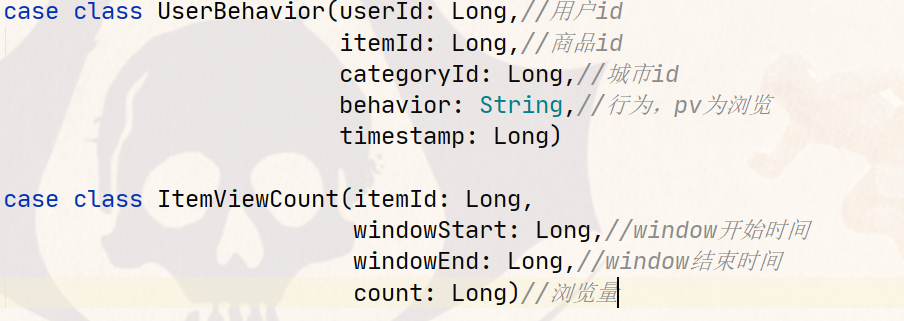
利用底层API实现
import java.sql.Timestamp import org.apache.flink.api.common.functions.AggregateFunction import org.apache.flink.api.common.state.{ListState, ListStateDescriptor} import org.apache.flink.api.scala.typeutils.Types import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.KeyedProcessFunction import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector import scala.collection.mutable.ListBuffer object TopHotItems { case class UserBehavior(userId: Long,//用户id itemId: Long,//商品id categoryId: Long,//城市id behavior: String,//行为,pv为浏览 timestamp: Long) case class ItemViewCount(itemId: Long, windowStart: Long,//window开始时间 windowEnd: Long,//window结束时间 count: Long)//浏览量 def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) val stream: DataStream[String] = env .readTextFile("filePath") //封装对象,并过滤出pv类型数据 .map(line => { val arr = line.split(",") UserBehavior(arr(0).toLong, arr(1).toLong, arr(2).toLong, arr(3), arr(4).toLong * 1000L) }) .filter(_.behavior.equals("pv")) .assignAscendingTimestamps(_.timestamp) // 分配升序时间戳 DataStream .keyBy(_.itemId) // 使用商品ID分流 .timeWindow(size = Time.hours(1), slide = Time.minutes(5)) // 按需求开窗 .aggregate(preAggregator = new CountAgg, windowFunction = new WindowResult) // 增量聚合和全窗口聚合结合,最大化优化内存的使用 .keyBy(_.windowEnd) // 按窗口结束时间分流,这样就能保证每条流中的数据都是同一个窗口的数据 .process(keyedProcessFunction = new TopN(3)) // DataStream stream.print() env.execute() } class CountAgg extends AggregateFunction[UserBehavior, Long, Long] { override def createAccumulator(): Long = 0L override def add(value: UserBehavior, accumulator: Long): Long = accumulator + 1 override def getResult(accumulator: Long): Long = accumulator override def merge(a: Long, b: Long): Long = a + b } class WindowResult extends ProcessWindowFunction[Long, ItemViewCount, Long, TimeWindow] { override def process(key: Long, context: Context, elements: Iterable[Long], out: Collector[ItemViewCount]): Unit = { //封装对象并附加窗口结束时间信息 out.collect(ItemViewCount(key, context.window.getStart, context.window.getEnd, elements.head)) } } class TopN(val topSize: Int) extends KeyedProcessFunction[Long, ItemViewCount, String] { // 只针对当前key可见的 lazy val listState: ListState[ItemViewCount] = getRuntimeContext.getListState( new ListStateDescriptor[ItemViewCount]("list-state", Types.of[ItemViewCount]) ) override def processElement(value: ItemViewCount, ctx: KeyedProcessFunction[Long, ItemViewCount, String]#Context, out: Collector[String]): Unit = { listState.add(value) // 不会重复注册 ctx.timerService().registerEventTimeTimer(value.windowEnd + 100) } override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Long, ItemViewCount, String]#OnTimerContext, out: Collector[String]): Unit = { //如果担心内存溢出可以考虑TreeSet,但是一般不会有那么大的数据量 val allItems: ListBuffer[ItemViewCount] = ListBuffer() import scala.collection.JavaConversions._ // 将列表状态中的数据转移到内存 for (item <- listState.get) { allItems += item } // 清空状态 listState.clear() // 使用浏览量降序排列 val sortedItems: ListBuffer[ItemViewCount] = allItems.sortBy(-_.count).take(topSize) val result = new StringBuffer() result.append("---------------------- ") .append(s"time: ${timestamp -100} ") for ( i <- 0 until allItems.size){ result.append(s" NO.${i+1} 商品id ${allItems(i).itemId} 点击量 ${allItems(i).count} ") } result.append("---------------------- ") Thread.sleep(5000) out.collect(result.toString) } } }
利用Flink SQL实现
import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.table.api.scala._ import org.apache.flink.api.scala._ import org.apache.flink.table.api.{EnvironmentSettings, Tumble} import org.apache.flink.types.Row // 使用sql实现实时top n需求 object HotItemsSQL { case class UserBehavior(userId: Long, itemId: Long, categoryId: Long, behavior: String, timestamp: Long) def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) env.setParallelism(1) // 新建表环境 val settings = EnvironmentSettings .newInstance() .useBlinkPlanner() .inStreamingMode() .build() val tableEnv = StreamTableEnvironment.create(env, settings) val stream = env .readTextFile("/Users/yuanzuo/Desktop/flink-tutorial/FlinkSZ1128/src/main/resources/UserBehavior.csv") .map(line => { val arr = line.split(",") UserBehavior(arr(0).toLong, arr(1).toLong, arr(2).toLong, arr(3), arr(4).toLong * 1000L) }) .filter(_.behavior.equals("pv")) .assignAscendingTimestamps(_.timestamp) // 分配升序时间戳 DataStream // 创建临时表 tableEnv.createTemporaryView("t", stream, 'itemId, 'timestamp.rowtime as 'ts) // top n只有blink planner支持 // 最内部的子查询实现了:stream.keyBy(_.itemId).timeWindow(Time.hours(1), Time.minutes(5)).aggregate(new CountAgg, new WindowResult) // 倒数第二层子查询:.keyBy(_.windowEnd).process(Sort) // 最外层:取出前三名 val result = tableEnv .sqlQuery( """ |SELECT * |FROM ( | SELECT *, | ROW_NUMBER() OVER (PARTITION BY windowEnd ORDER BY icount DESC) as row_num | FROM ( | SELECT itemId, count(itemId) as icount, | HOP_END(ts, INTERVAL '5' MINUTE, INTERVAL '1' HOUR) as windowEnd | FROM t GROUP BY itemId, HOP(ts, INTERVAL '5' MINUTE, INTERVAL '1' HOUR) | ) |) |WHERE row_num <= 3 |""".stripMargin) result .toRetractStream[Row] .filter(_._1 == true) .print() env.execute() } }