Python之MySQL
一.概述
数据库(Database,简称DB)
数据库技术是计算机应用领域中非常重要的技术,它产生于20世纪60年代末,是数据管理的最新技术,也是软件技术的一个重要分支。
简单的说,数据库就是一个存放数据的仓库,这个仓库是按照一定的数据结构(数据结构是指数据的组织形式或数据之间的联系)来组织、存储的,我们可以通过数据库提供的多种方法来管理数据库里的数据。更简单的形象理解,数据库和我们生活中存放杂物的仓库性质一样,区别只是存放的东西不同。
数据库表(table)
数据表是关系数据库中一个非常重要的对象,是其它对象的基础,也是一系列二维数组的集合,用来存储、操作数据的逻辑结构。根据信息的分类情况。
一个数据库中可能包含若干个数据表,每张表是由行和列组成,记录一条数据,数据表就增加一行,每一列是由字段名和字段数据集合组成,列被称之为字段,
每一列还有自己的多个属性,例如是否允许为空、默认值、长度、类型、存储编码、注释等.例如

数据(data)
存储在表中的信息就叫做数据.
数据库系统有3个主要的组成部分
1.数据库(Database System):用于存储数据的地方。
2.数据库管理系统(Database Management System,DBMS):用户管理数据库的软件。
3.数据库应用程序(Database Application):为了提高数据库系统的处理能力所使用的管理数据库的软件补充。
数据库的发展史(五个阶段)
1.文件系统
数据库系统的萌芽阶段,通过文件来存取数据.
文件系统是数据库系统的萌芽阶段,出现在上世纪五六十年代,可以提供简单的数据存取功能,但无法提供完整、统一的数据管理功能,例如复杂查询等。所以在管理较少、较简单的数据或者只是用来存取简单数据,没有复杂操作的情况下,会使用文件系统
2.层次型数据库
数据库系统真正开始阶段,数据的存储形式类似树形结构,所以也叫树型数据库.
3.网状数据库
数据的存储形式类似网状结构.
从二十世纪六十年代开始,第一代数据库系统(层次模型数据库系统、网状模型数据库系统)相继问世,它们为统一管理和共享数据提供了有力的支撑
在这个阶段,网状模型数据库由于它的复杂、专用性,没有被广泛使用。而在层次模型数据库中,IBM公司的IMS(Information Management System,信息管理系统)层次模型数据库系统则得到了极大的发展,一度成为最大的数据库管理系统,拥有巨大的客户群
4.关系型数据库
二十世纪七十年代初,关系型数据库系统开始走上历史舞台,并一直保持着蓬勃的生命力.关系型数据库系统使用结构化查询语言(Structured Query Language,SQL)作为数据库定义语言DDL和数据库操作语言DML
5.面向对象数据库
把面向对象的方法和数据库技术结合起来,可以使数据库系统的分析、设计最大程度地与人们对客观世界的认识相一致,并且能够有效的为面向对象程序提供更好的数据库支撑
二.数据库的特点
⑴ 实现数据共享
数据共享包含所有用户可同时存取数据库中的数据,也包括用户可以用各种方式通过接口使用数据库,并提供数据共享。
⑵ 减少数据的冗余度
同文件系统相比,由于数据库实现了数据共享,从而避免了用户各自建立应用文件。减少了大量重复数据,减少了数据冗余,维护了数据的一致性。
⑶ 数据一致性和可维护性,以确保数据的安全性和可靠性
主要包括:①安全性控制:以防止数据丢失、错误更新和越权使用;
②完整性控制:保证数据的正确性、有效性和相容性;
③并发控制:使在同一时间周期内,允许对数据实现多路存取,又能防止用户之间的不正常交互作用。
⑷ 故障恢复

 权限列表
权限列表
由数据库管理系统提供一套方法,可及时发现故障和修复故障,从而防止数据被破坏。数据库系统能尽快恢复数据库系统运行时出现的故障,可能是物理上或是逻辑上的错误。比如对系统的误操作造成的数据错误等。
三.系统数据库
- information_schema :虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息、列信息、权限信息、字符信息等
- mysql:核心数据库,里面包含用户、权限、关键字等信息。不可以删除
- performance_schema:mysql 5.5版本后添加的新库,主要收集系统性能参数,记录处理查询请求时发生的各种事件、锁等现象
- sys : mysql5.7版本新增加的库,通过这个库可以快速的了解系统的元数据信息,可以方便DBA发现数据库的很多信息,解决性能瓶颈都提供了巨大帮助
四.数据库操作
1、创建数据库
#语法:CREATE DATABASE db_name charset utf8;
2、查看数据库
#查看当前用户下所有数据库 show databases; #查看创建数据库的信息 show create database db_name; #查看数据库版本 select version(); #查看当前登录用户 select user(); #查看当前数据库里有哪些用户 select user,host from mysql.user; #删除数据库 drop database db_name; #选择数据库 use db_name;
3、数据库的用户权限
创建用户 create user '用户名'@'ip地址' identified by '密码'; 删除用户 drop user '用户名'@'ip地址'; 修改用户 rename user '用户名'@'ip地址';to '新用户名'@'ip地址' 查看用户权限 show grants for '用户名'@'ip地址'; 授权 grant 权限 on 数据库.表 to '用户名'@'ip地址'; 取消权限 revoke 权限 on 数据库.表 from '用户名'@'ip地址';
授权用户所有权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123.com' WITH GRANT OPTION;
权限列表4、忘记密码和修改数据库密码;
1:使用mysqladmin修改用户密码;

2:进入数据库直接设置用户名密码:(注意:下图为mysql5.7版本的)
mysql5.6版本修改密码为:
update mysql.user set password = password('新密码') where user= '用户名'
flush privileges; -- 刷新权限
3:忘记密码:
忘记密码:
1、首先关闭mysql服务:
service mysqld stop
2、跳过权限检查,启动mysql并进入mysql
mysqld_safe --skip-grant-tables&
mysql
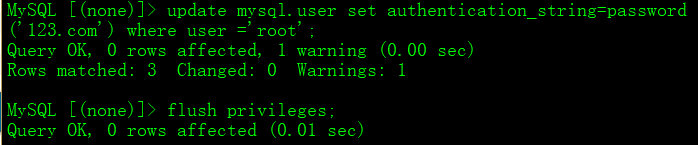
3、进入mysql数据库并更新用户的密码:
use mysql;
update mysql.user set authentication_string=password('新密码') where user='root';
4、刷线权限
flush privileges;
5、停止后台的跳过权限检查任务,然后启动数据库;
kill %后台任务的pid
services mysqld start
五.数据表操作
1、表操作
创建表: CREATE TABLE 表名( 字段名1 类型[(宽度) 约束条件], 字段名2 类型[(宽度) 约束条件], 字段名3 类型[(宽度) 约束条件] )ENGINE=innodb DEFAULT CHARSET utf8; 约束条件: not null :表示此列不能为空 auto_increment :表示自增长,默认每次增长+1 注意:自增长只能添加在主键或者唯一索引字段上 primary key :表示主键(唯一且不为空) engine =innodb :表示指定当前表的存储引擎 default charset utf8 :设置表的默认编码集
#查询表数据
select 字段(多个以","间隔) from 表名;
#查看表结构
desc 表名;
#查看创建表信息
show create table 表名;
删除表;
drop tables 表名;
示例

2、修改表结构:
#添加表字段
alter table 表名 add 字段名 类型 约束;
ps: after name 表示在name字段后添加字段 age.
#修改表字段
方式一: alter table student modify 字段 varchar(100) null;
方式二: alter table student change 旧字段 新字段 int not null default 0;
ps:二者区别:
change 可以改变字段名字和属性
modify只能改变字段的属性
#删除表字段 :
alter table student drop 字段名;
#更新表名称:
rename table 旧表名 to 新表名;
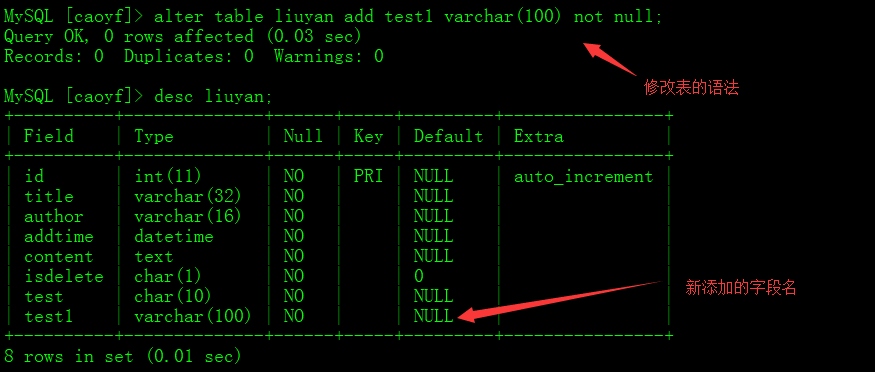
六.数据操作
1、数据操作语法
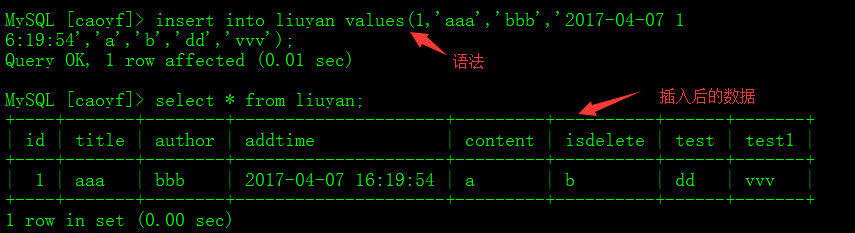
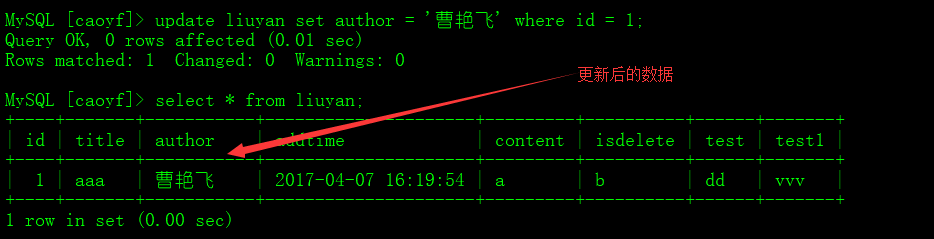
插入数据 #语法一: 按字段进行插入 insert into 表(字段1,字段2 ...) values (值1,值2 ...); #语法二:按字段顺序插入 insert into 表 values (值1,值2 ...); #语法三: 插入多条记录 insert into 表 values (值1,值2 ...) ,(值1,值2 ...) ,(值1,值2 ...); #语法四:插入查询结果 insert into 表(字段1,字段2 ...) select 字段1,字段2 ... from 表; 更新操作 #语法一: 更新整表数据 update 表 set 字段1= '值1', 字段2='值2' ... ; #语法二:更新符合条件字段3的数据 update 表 set 字段1= '值1', 字段2='值2' ... where 字段3 = 值3; 删除操作 #语法一:整表数据删除 delete from 表 ; #语法二:删除符合 where后条件的数据 delete from 表 where 字段1=值1;
2、单表查询
简单查询
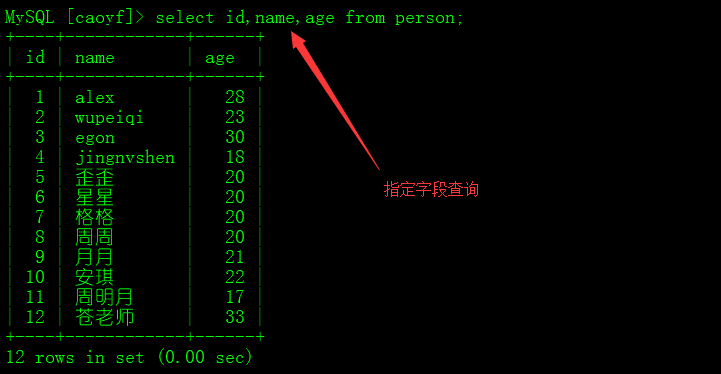
#查询语法:
select [distinct]*(所有)|字段名,...字段名 from 表名;
条件查询
#查询格式:
select [distinct]*(所有)|字段名,...字段名 from 表名 [where 条件过滤]
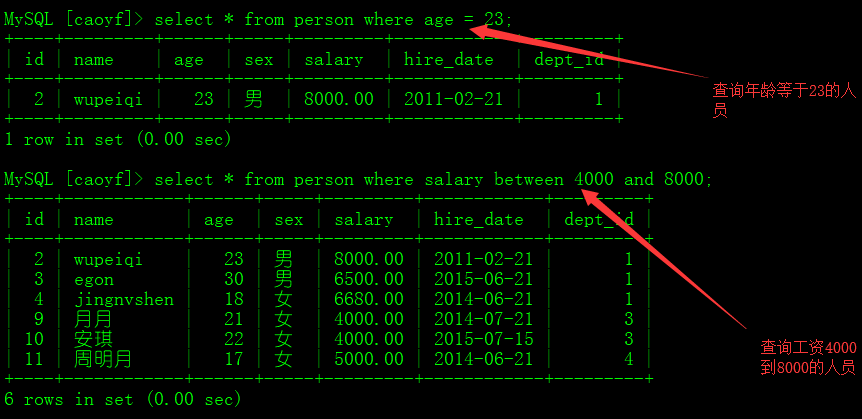
区间查询
关键字 between 10 and 20 :表示 获得10 到 20 区间的内容
# 使用 between...and 进行区间 查询
select * from person where salary between 4000 and 8000;
ps: between...and 前后包含所指定的值
等价于 select * from person where salary >= 4000 and salary <= 8000;
集合查询
关键字: in, not null
#使用 in 集合(多个字段)查询
select * from person where age in(23,32,18);
等价于: select * from person where age =23 or age = 32 or age =18;
#使用 in 集合 排除指定值查询
select * from person where age not in(23,32,18);
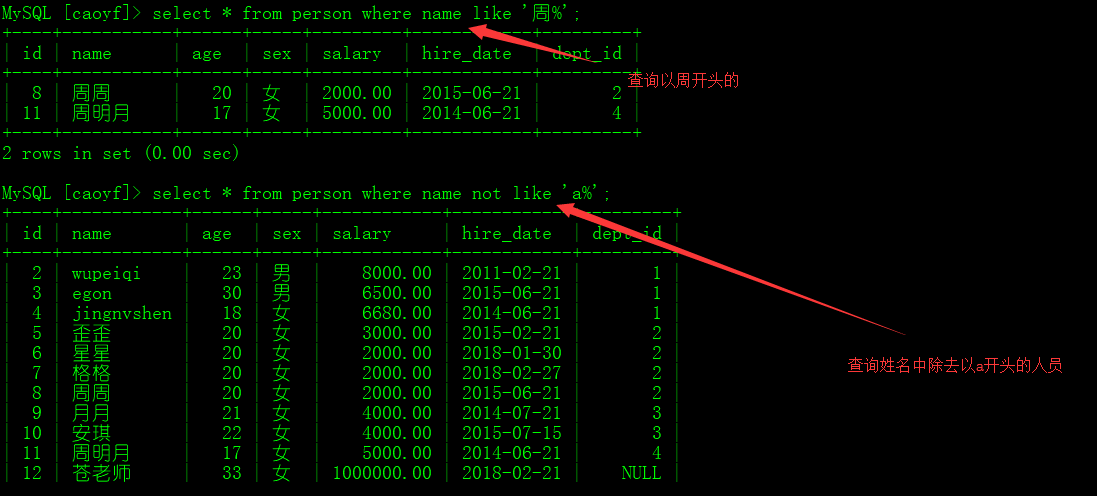
模糊查询
关键字 like , not like
%: 任意多个字符
_ : 只能是单个字符
排序查询
关键字: ORDER BY 字段1 DESC, 字段2 ASC
#排序查询格式:
select 字段|* from 表名 [where 条件过滤] [order by 字段[ASC] [DESC]]
升序:ASC 默认为升序
降序:DESC
PS:排序order by 要写在select语句末尾
聚合查询
聚合: 将分散的聚集到一起.
聚合函数: 对列进行操作,返回的结果是一个单一的值,除了 COUNT 以外,都会忽略空值
COUNT:统计指定列不为NULL的记录行数;
SUM:计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
MAX:计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
MIN:计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
AVG:计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
#格式:
select 聚合函数(字段) from 表名;
分组查询
分组的含义: 将一些具有相同特征的数据 进行归类.比如:性别,部门,岗位等等
怎么区分什么时候需要分组呢?
套路: 遇到 "每" 字,一般需要进行分组操作.
分组查询格式:
select 被分组的字段 from 表名 group by 分组字段 [having 条件字段]
ps: 分组查询可以与 聚合函数 组合使用.
where 与 having区别:
#执行优先级从高到低:where > group by > having
#1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。
#2. Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
分页查询:
好处:限制查询数据条数,提高查询效率
正则查询
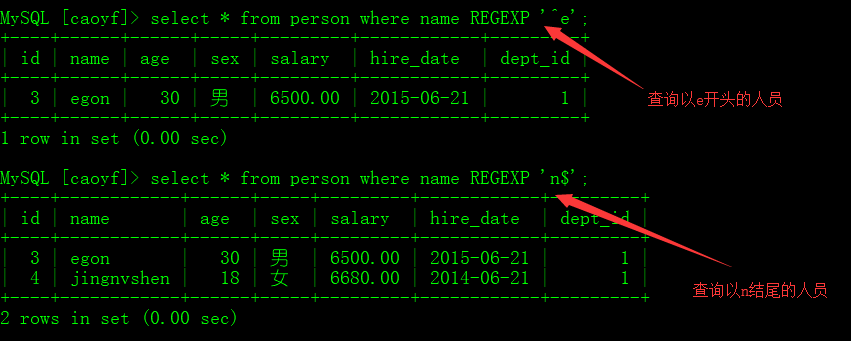
MySQL中使用 REGEXP 操作符来进行正则表达式匹配。
# ^ 匹配 name 名称 以 "e" 开头的数据
select * from person where name REGEXP '^e';
# $ 匹配 name 名称 以 "n" 结尾的数据
select * from person where name REGEXP 'n$';
# . 匹配 name 名称 第二位后包含"x"的人员 "."表示任意字符
select * from person where name REGEXP '.x';
# [abci] 匹配 name 名称中含有指定集合内容的人员
select * from person where name REGEXP '[abci]';
# [^alex] 匹配 不符合集合中条件的内容 , ^表示取反
select * from person where name REGEXP '[^alex]';
#注意1:^只有在[]内才是取反的意思,在别的地方都是表示开始处匹配
#注意2 : 简单理解 name REGEXP '[^alex]' 等价于 name != 'alex'
# 'a|x' 匹配 条件中的任意值
select * from person where name REGEXP 'a|x';
#查询以w开头以i结尾的数据
select * from person where name regexp '^w.*i$';
#注意:^w 表示w开头, .*表示中间可以有任意多个字符, i$表示以 i结尾
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。 |
| $ | 匹配输入字符串的结束位置。 |
| . | 匹配任何字符(包括回车和新行) |
| [...] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^...] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
3、多表查询
多联合查询
select 字段1,字段2... from 表1,表2... [where 条件]
注意: 如果不加条件直接进行查询,则会出现以下效果,这种结果我们称之为 笛卡尔乘积
多表连接查询
#多表连接查询语法(重点)
SELECT 字段列表
FROM 表1 INNER|LEFT|RIGHT JOIN 表2
ON 表1.字段 = 表2.字段;
内连接查询
select * from person inner join dept on person.did =dept.did;
左外连接查询
#查询人员和部门所有信息
select * from person left join dept on person.did =dept.did;
右外链接查询
#查询人员和部门所有信息
select * from person right join dept on person.did =dept.did;
全连接查询
全连接查询:是在内连接的基础上增加 左右两边没有显示的数据
注意: mysql并不支持全连接 full JOIN 关键字
注意: 但是mysql 提供了 UNION 关键字.使用 UNION 可以间接实现 full JOIN 功能
#查询人员和部门的所有数据
SELECT * FROM person LEFT JOIN dept ON person.did = dept.did
UNION
SELECT * FROM person RIGHT JOIN dept ON person.did = dept.did;