Baidu All Reduce,即Ring All Reduce。Ring All Reduce技术在高性能计算领域很常用,2017年被百度用于深度学习训练。
朴素All Reduce的通信时间随GPU节点数线性增长。Ring All Reduce的通信时间跟GPU节点数无关,只受限于GPU间最慢的连接。
Ring All Reduce包含两步:scatter reduce和all gather。
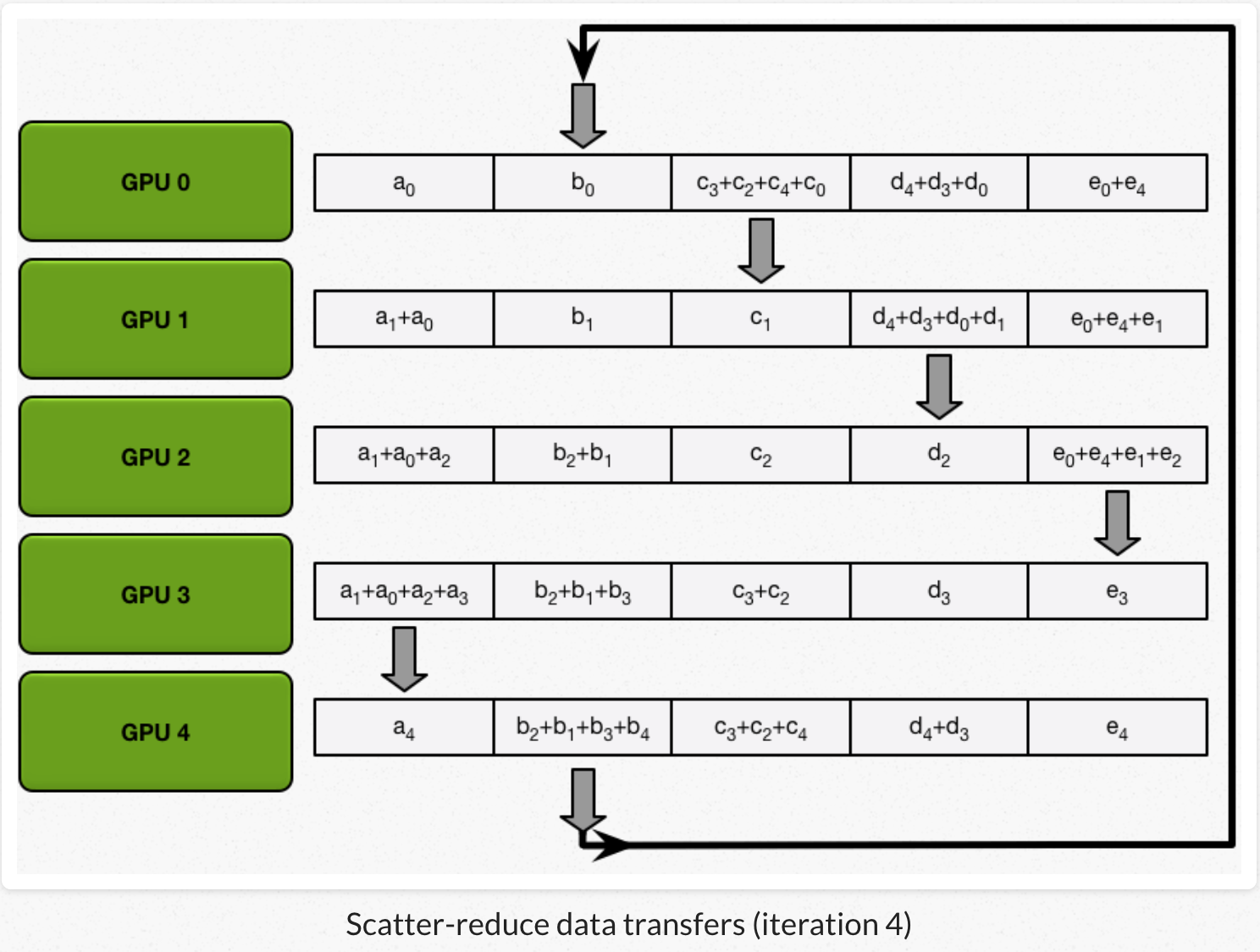
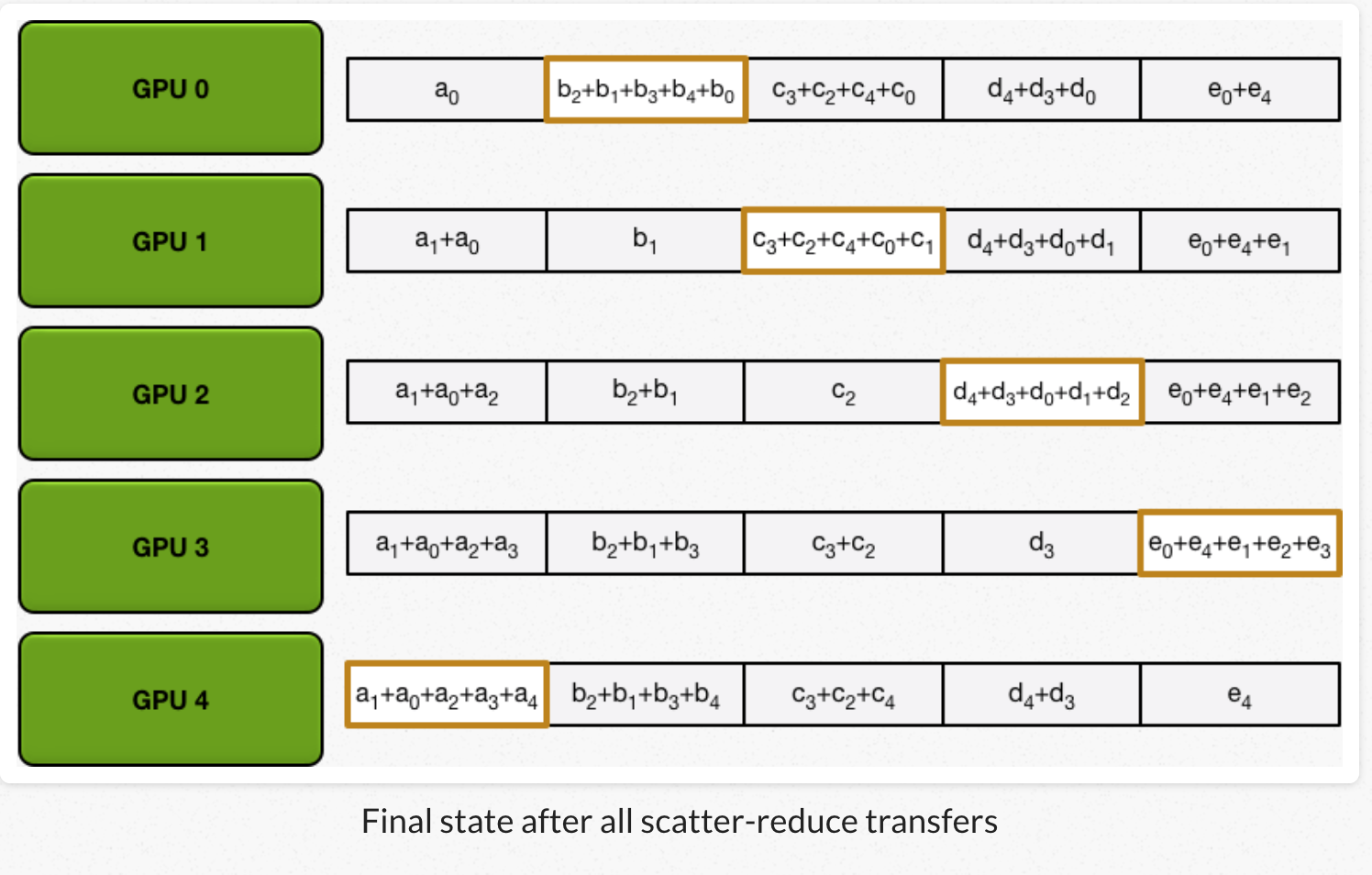
1)scatter reduce:GPU交换数据,每个GPU得到最后结果的一部分(chunk)。

假设要实现数组间对应元素求和,GPU节点数为N,每个GPU都有一个相同size的数组。
1、每个GPU把自己的数组划分成N份。
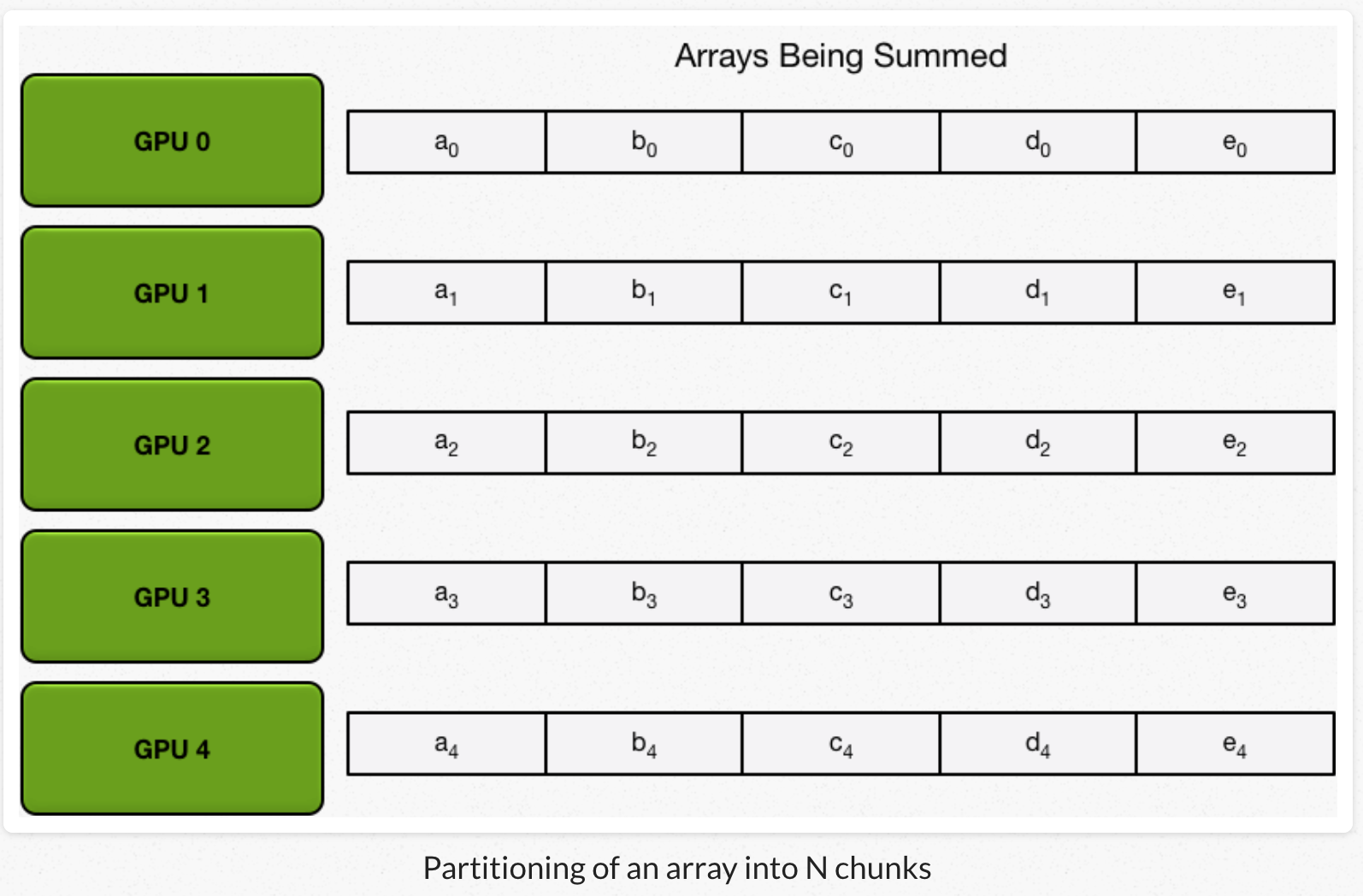
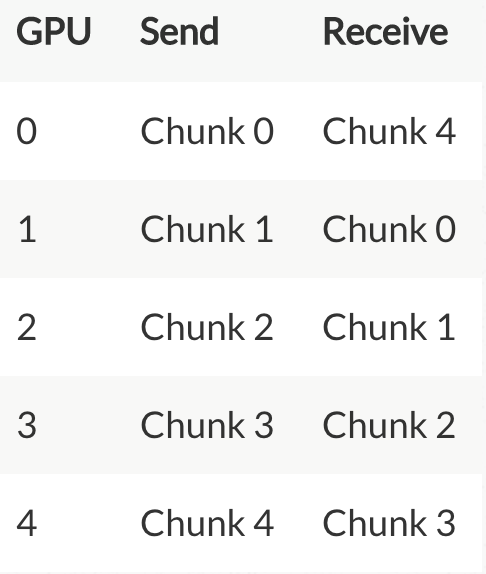
2、每个GPU做N-1次迭代,每次迭代:GPU向它的右相邻节点发送一个chunk,同时从它的左相邻节点接收一个chunk并跟本地对应chunk累加。每次迭代每个GPU发送和接受的chunk都不一样。第N个GPU,一开始发送chunk N并且接收chunk N-1,然后不断向后处理。每一次迭代都把上一次迭代收到的chunk,发送出去。

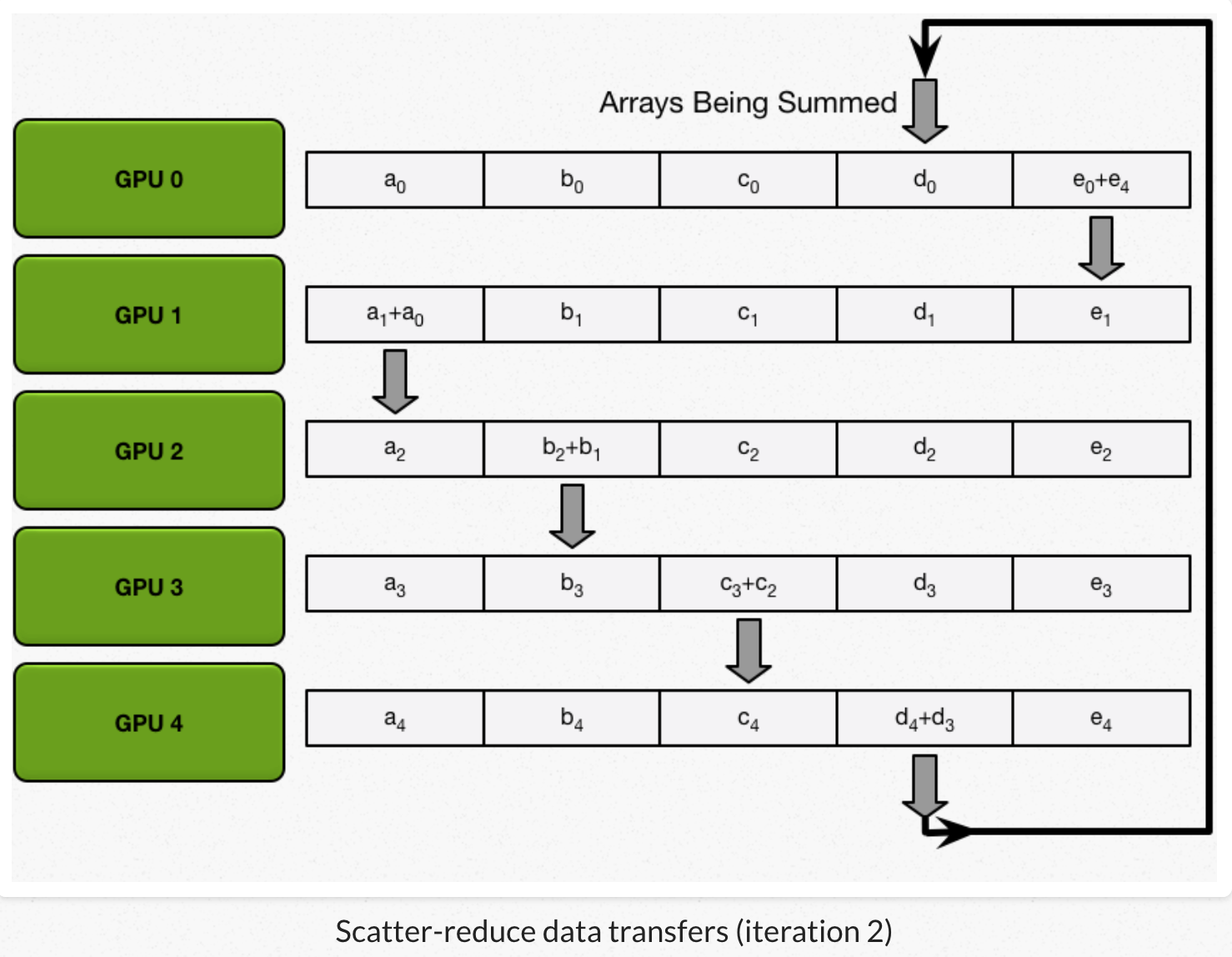
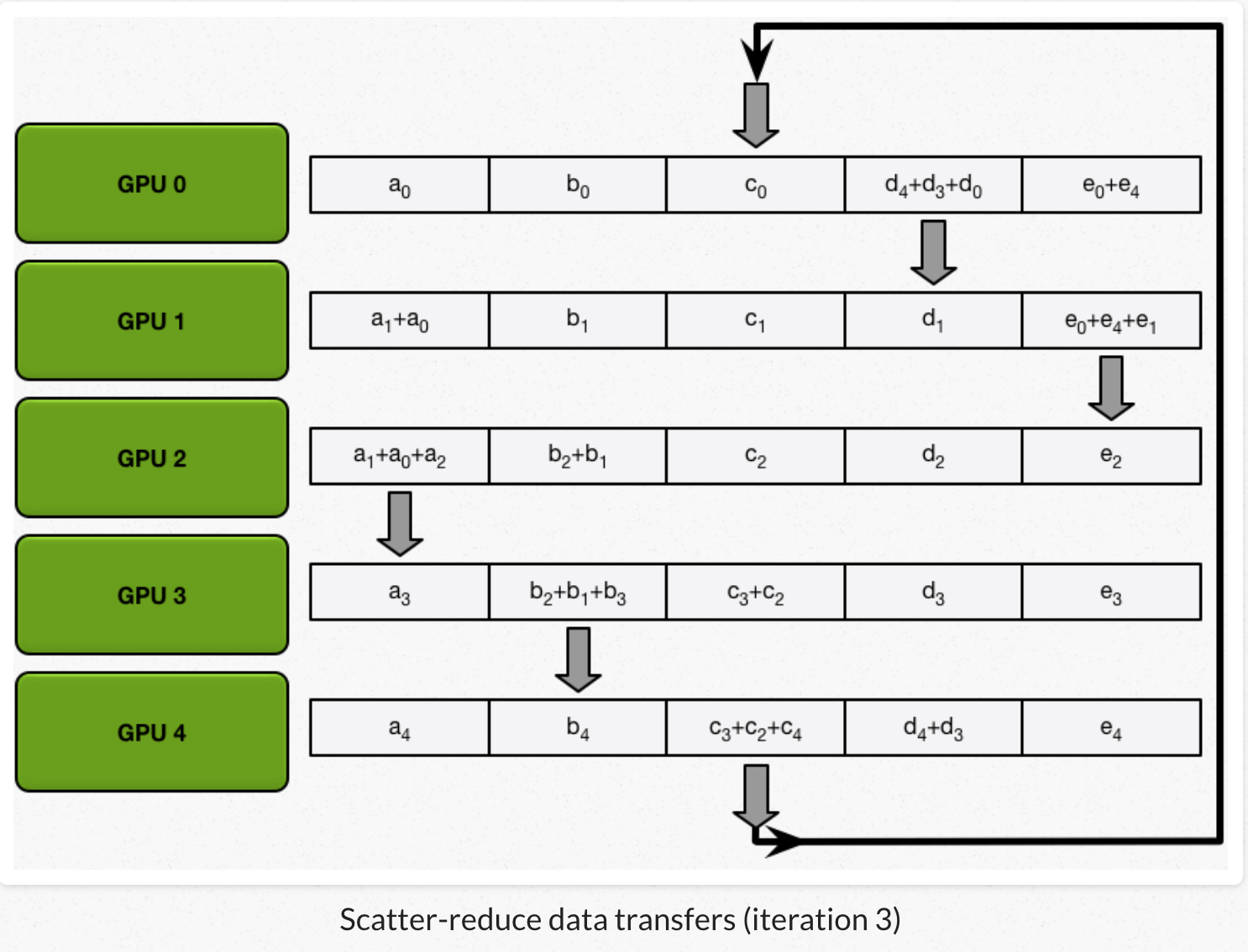
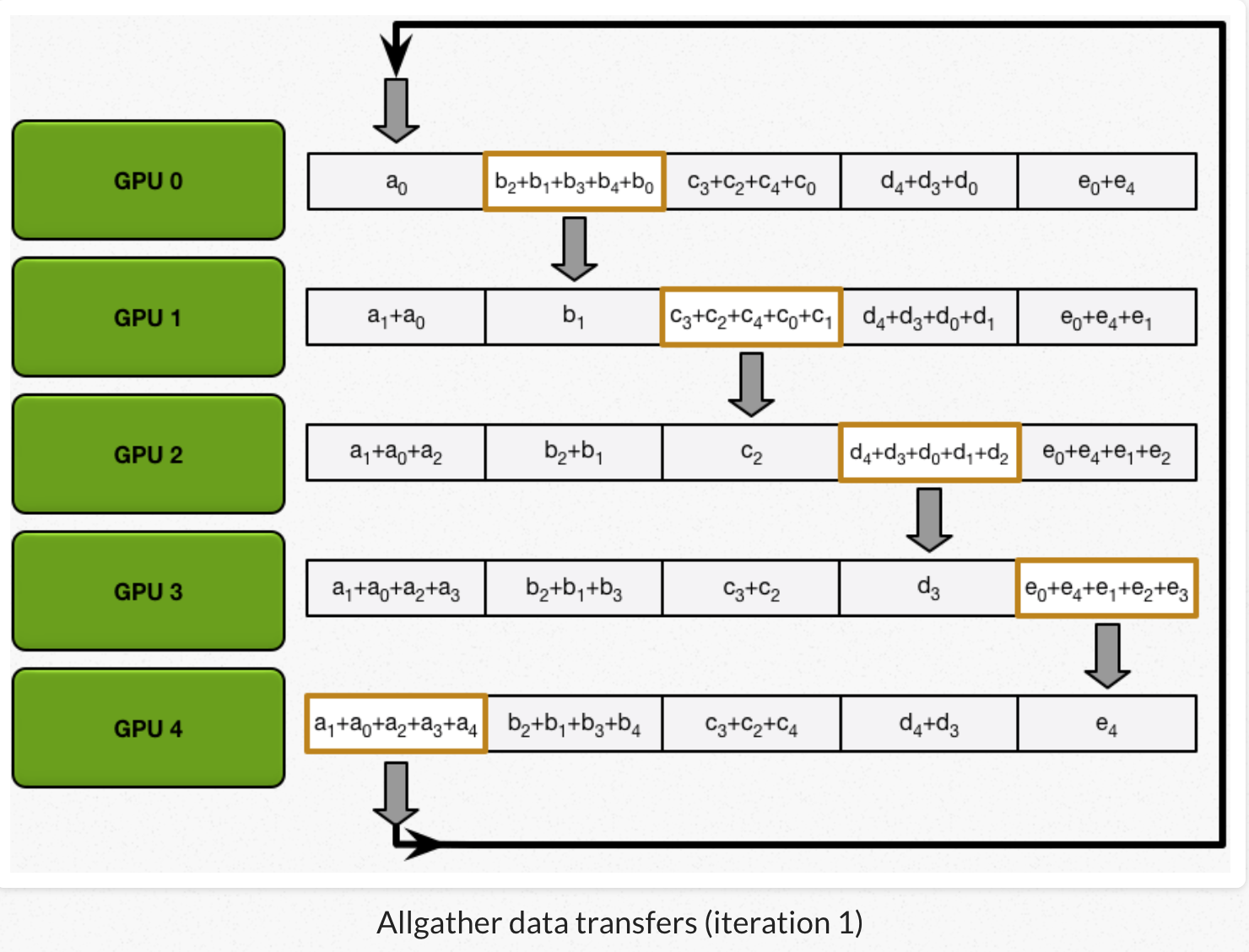
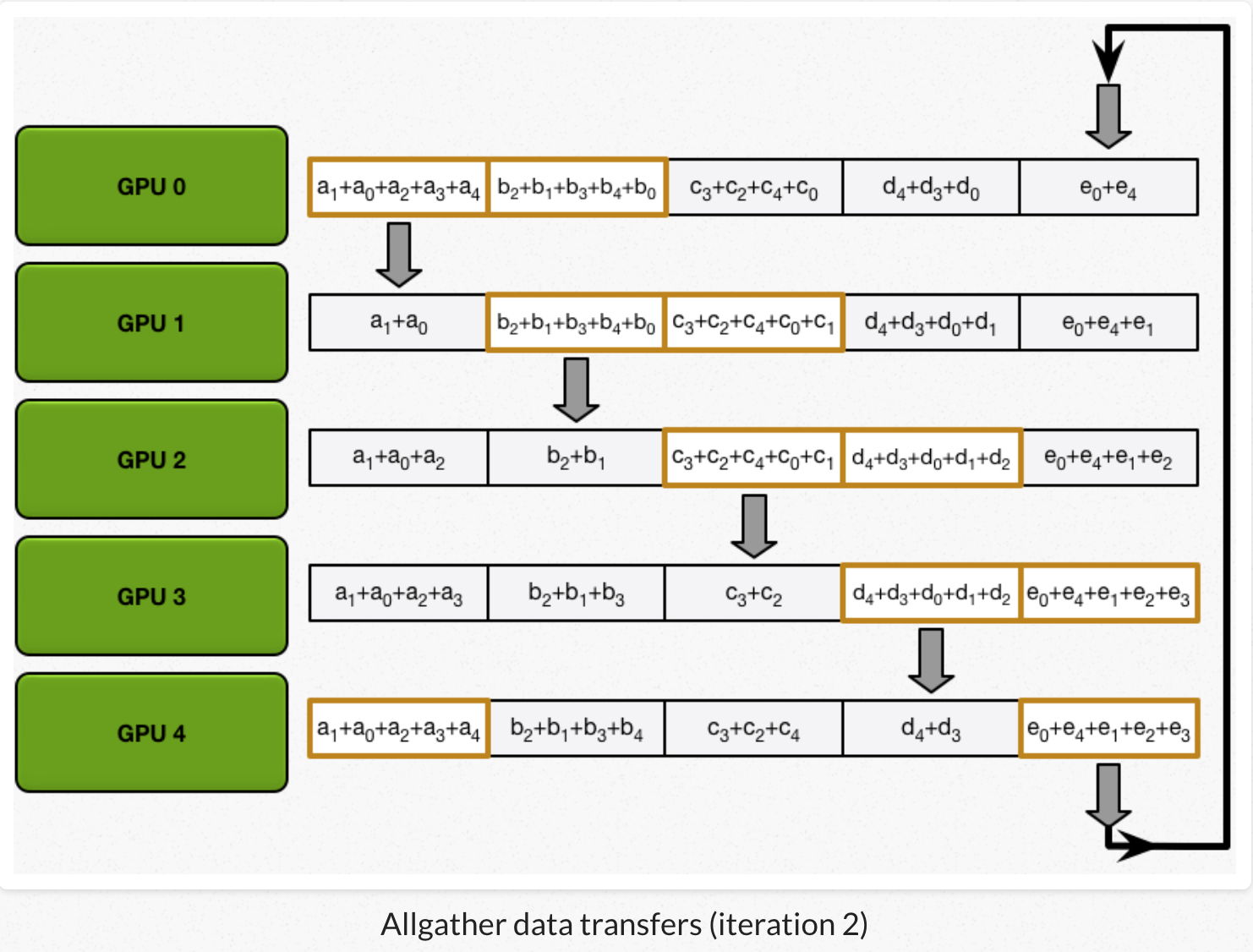
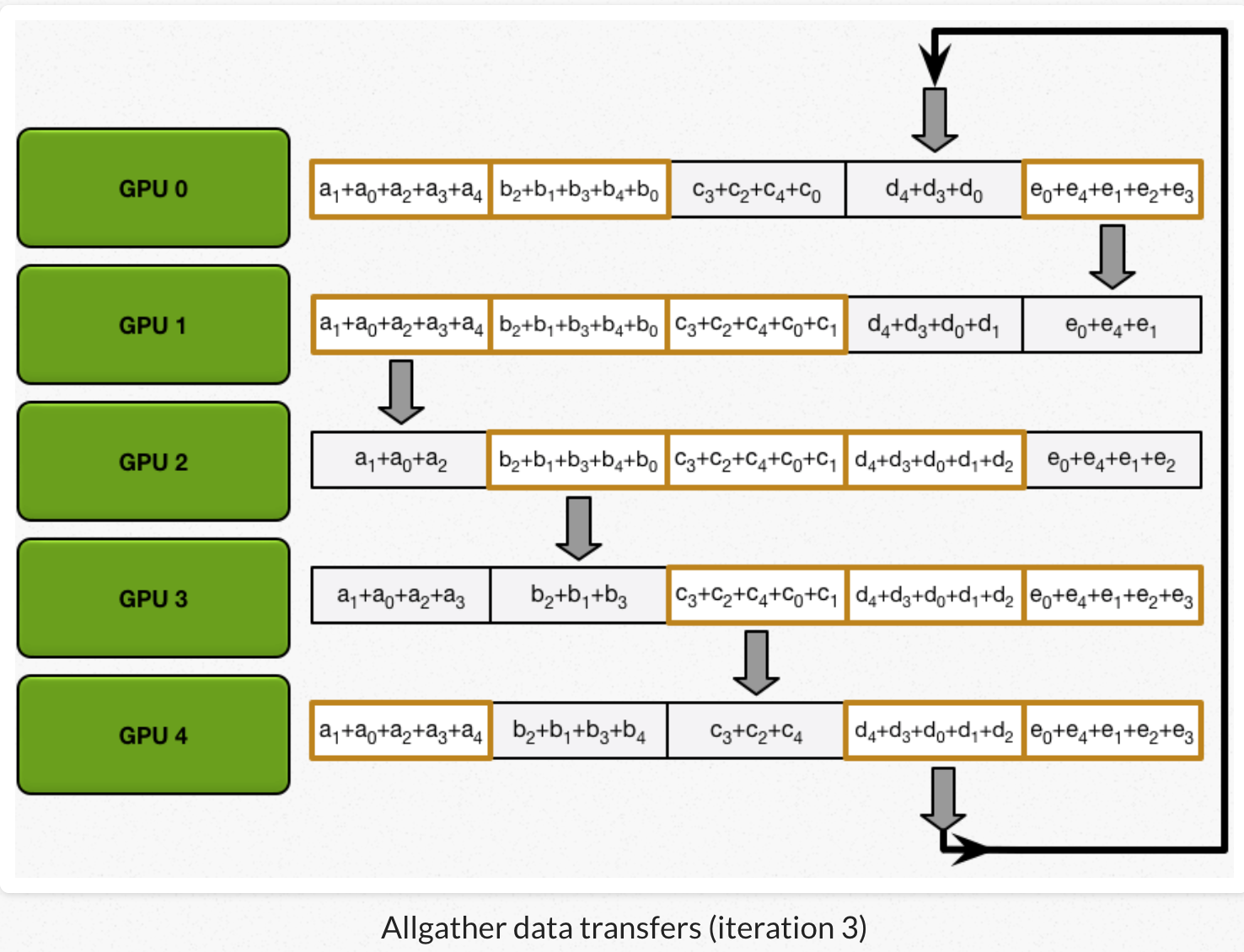
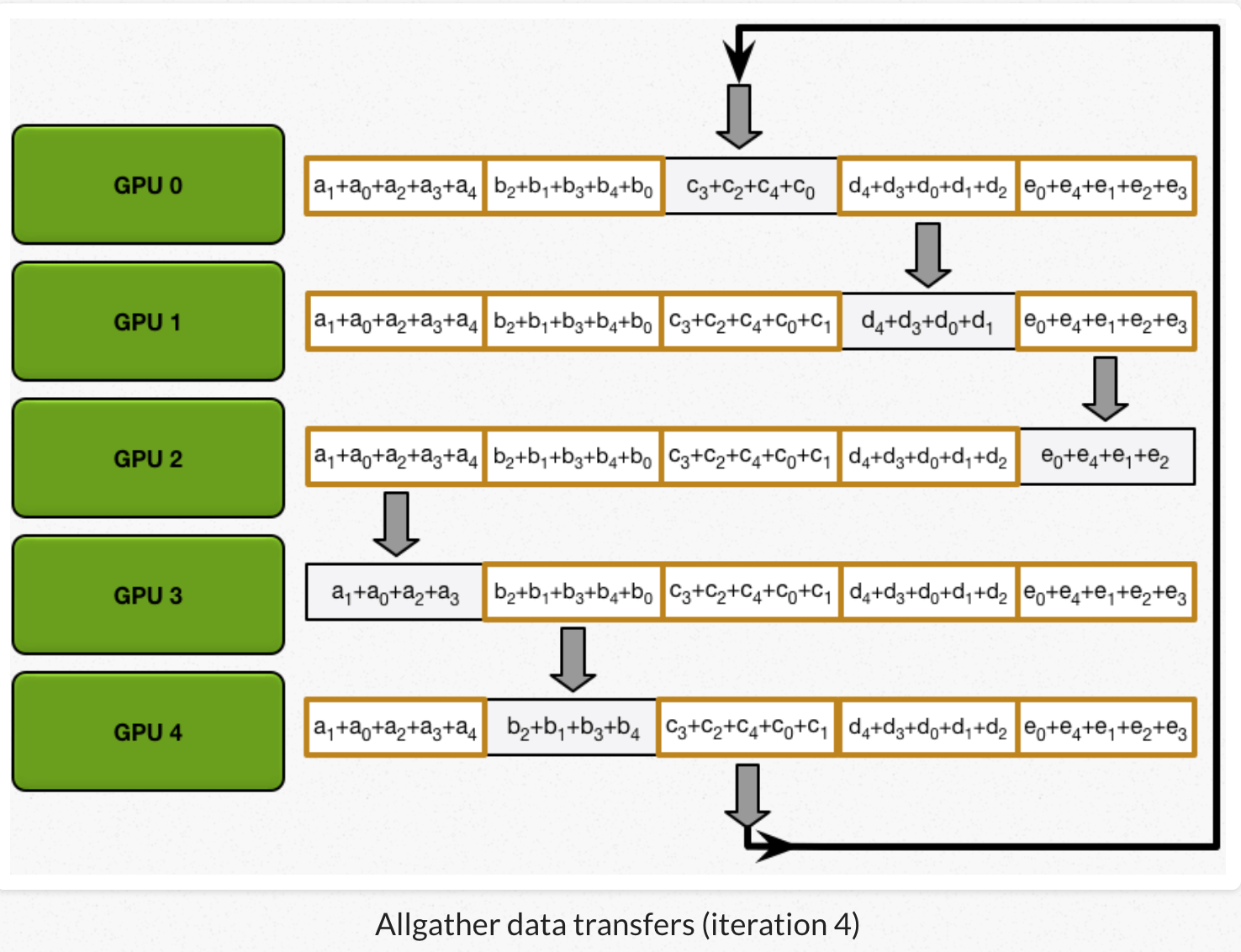
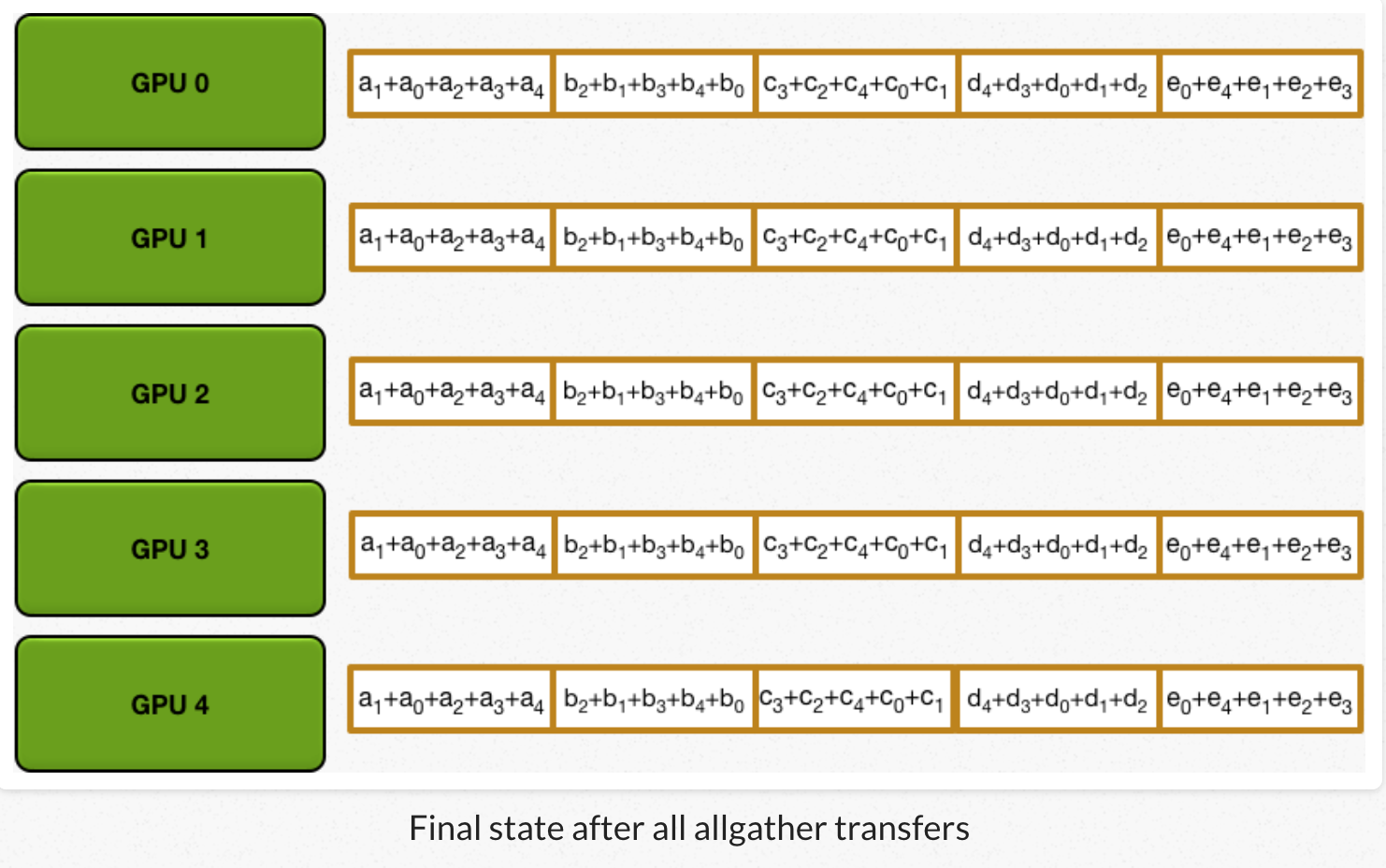
2)all gather:GPU交换chunk,每个GPU得到最后结果。
经过scatter reduce,每个GPU的某些chunk已经是最后结果了。all gather类似scatter reduce(也是N-1次迭代的发送和接收),但不是把接收到的chunk跟本地chunk累加,而是覆盖本地chunk。 第N个GPU,一开始发送第N+1个chunk,并且接收chunk N。在之后的迭代中,总是把上一次迭代接收到的chunk,发送出去。

每个GPU的通信数据量:D = 2(N-1)S/N。
通信时间:T = 2(N-1)S/(NB),可以看出,跟GPU节点数无关。
每次训练迭代(跟上面的迭代不是一回事),每个GPU前向传播计算误差,然后反向传播计算每个weight的梯度。反向计算梯度是从输出层的权值到输入层的权值,意味着,前面层的梯度没算出来时,后面层的梯度已经可用。因为All Reduce可以操作参数子集,所以在一些梯度还没算出来时,就可以开始All Reduce了。通信和计算之间的overlap取决于网络的实际优化情况。