BytePS是一个高性能通用的分布式训练框架。支持TensorFlow,Keras,PyTorch和MXNet,可以跑在TCP和RDMA(Remote Direct Memory Access,远程直接内存访问)网络上。BytePS的性能比现有的开源分布式训练框架都好很多,例如,在流行的公有云上,用相同数量的GPU,BytePS的训练速度是Horovod+NCCL的两倍。
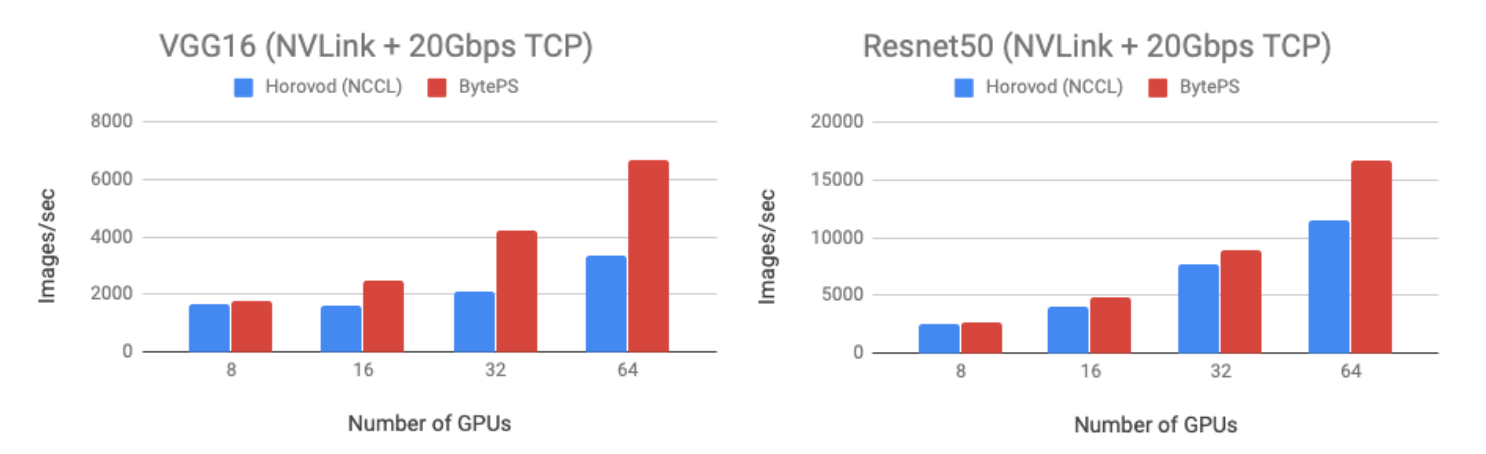
为了证明,我们测试两个模型:VGG16(通信敏感)和Resnet50(计算敏感),两个模型都是用fp32训练。
我们使用Tesla V100 16GB GPU,并且设置每个GPU的batch size为64。训练机器是云上的虚拟机,每台机器8个GPU,并且开着NVLink。机器之间用20Gbps的TCP/IP网络互连。
BytePS的性能比Horovod+NCCL在Resnet50上好44%,在VGG16上好100%。
你可以用我们提供的Dockerfiles和样例脚本来复现上述结果。
在RDMA网络上的评估可以查看performance.md。
BytePS的性能为什么可以比Horovod好这么多?一个主要的原因是,BytePS弃用了MPI,基于云和共享集群设计。
MPI产生于HPC,适用于同质硬件构建的一个集群,以及跑单个任务。但是,云(或者大量共享集群)就不一样了。
这让我们重新思考最好的通信策略。简而言之,BytePS只在机器内部使用NCCL,而重新实现了机器之间的通信。
BytePS还集成了很多加速技术,如分层策略,pipelining,张量分区,NUMA-aware本地通信,基于优先级的调度等等。
我们为你提供了一个step-by-step的教程,来跑训练任务的benchmark。BytePS依赖CUDA和NCCL,而且需要gcc>=4.9。
可以使用pypi源来构建BytePS。
可以使用源代码来构建BytePS。
git clone --recurse-submodules https://github.com/bytedance/byteps cd byteps python setup.py install
你可以设置BYTEPS_USE_RDMA=1来安装RDMA支持,前提是RDMA驱动要装好。关于你的服务器和调度器节点,我们强烈推荐你只使用我们提前构建好的docker镜像bytepsimage/byteps_server。否则,你就得手动编译我们修改过得MXNet。镜像中没有RDMA支持。
虽然核心完全不一样,但是BytePS高度兼容Horovod的接口。
如果你的任务只依赖Horovod的allreduce和broadcast,那么可以很快切换到BytePS,用import byteps.tensorflow as bps替换import horovod.tensorflow as hvd,再用bps替换hvd。如果你原来直接用了hvd.allreduce,那么还需要替换成bps.push_pull。
BytePS目前不支持纯的CPU训练。以下特性还没支持:
稀疏模型训练。
异步训练。
容错。
Straggler-mitigation。
参考链接: