论文:https://arxiv.org/abs/1409.1556
译文:用于大规模图像识别的非常深的卷积网络
摘要
本文,我们研究,在大规模图像识别中,卷积网络的深度对准确度的影响。我们的主要贡献是,利用3*3的卷积核来增加网络的深度,并且做了全面的评估,当深度达到16~19个权值层时,已有最好网络的性能都能得到显著的提升。这些发现让我们在2014ImageNet挑战赛的定位和分类跟踪任务中,分别拿到了第一名和第二名的成绩。当然,我们的模型,在其他数据集上的表现也达到了当前最好的水平。我们已经公开了两种性能最好的网络模型,希望能促进深度视觉表达在计算机视觉领域之后的研究和应用。
介绍
卷积网络最近在大规模图像和视频识别中取得了很大的成功,这得益于大型公开图像库(如ImageNet),和高性能计算系统(如GPU、大规模分布式集群)。特别是ImageNet Large-Scale Visual Recognition Challenge(简称ILSVRC),作为几代大规模图像分类系统(从高维浅层特征编码到深度卷积网络)的测试平台,在深度视觉识别架构的发展中扮演着很重要的角色。
随着卷积网络在计算机视觉领域越来越重要,很多人尝试在原有架构上进行改进,以期提高准确度。例如,ILSVRC2013的冠军,在第一个卷积层使用更小的接受窗口和更小的步长。再例如,在整张图像以及多个尺寸上,稠密地训练和测试网络。而我们关注网络深度,固定网络的其他参数,然后通过添加卷积层来增加网络的深度,这是可行的,因为我们的卷积核很小(3*3)。
我们提出更准确的卷积网络,不仅在ILSVRC的分类和定位任务中表现最佳,而且可以应用到别的图像识别数据集上,甚至作为某些相对简单的pipeline(如没有微调的线性SVM深度特征分类)的一部分都能表现出优异的性能。我们已经公开两个性能最好的模型,以促进后续研究。
论文其余部分组织如下:第2节,描述我们卷积网络的配置;第3节,图像分类的训练和评估细节;第4节,对比ILSVRC分类任务中不同配置的网络;第5节,论文总结;附录A,描述我们在ILSVRC-2014中的目标定位系统;附录B,讨论“非常深的特征”在其他数据集上的泛化能力;附录C,本文的主要修订记录。
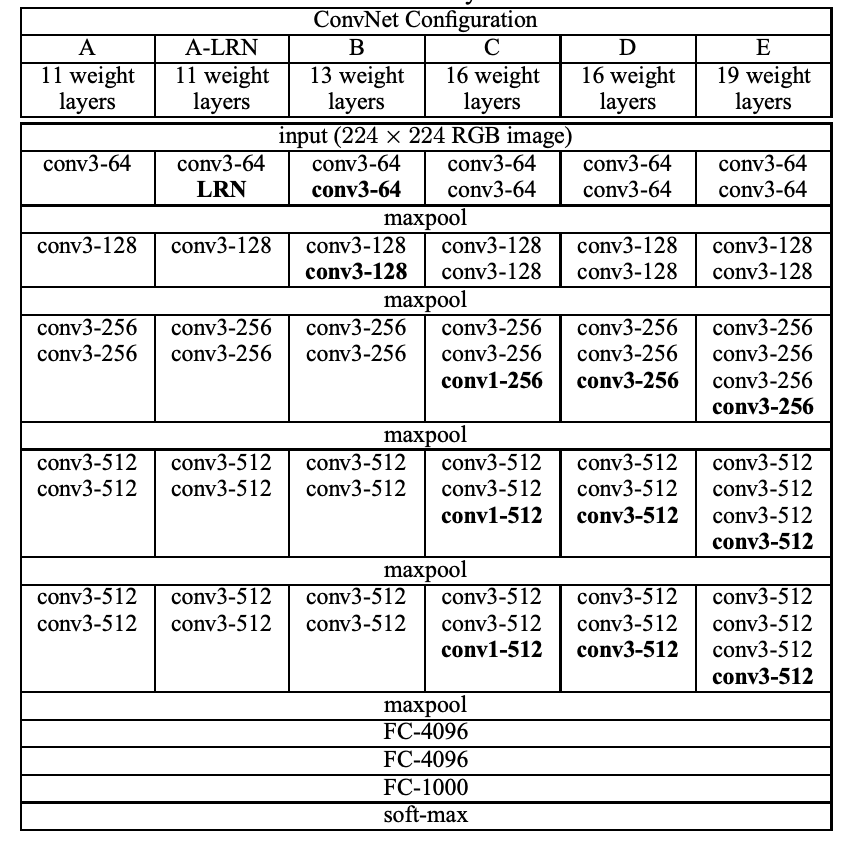
卷积网络配置
为了公平地衡量增加网络深度带来的提升,我们所有的卷积网络层设计都是根据相同的原则(受Ciresan2011和Krizhevsky2012启发)。本节中,我们首先描述卷积网络的通用结构,然后细化评估中用到的配置,再对比我们的设计和先前最好的网络。
- 架构
我们卷积网络的输入是固定尺寸的224*224RGB图像,做的唯一预处理就是对输入图像的每个像素都减去训练集的RGB均值。图像经过一堆卷积核为3*3(获取上下左右中的最小尺寸)的卷积层。
- 配置
- 讨论
我们卷积网络的配置与ILSVRC-2012和ILSVRC-2013那些性能出众的网络有很大的不同,没有在第一个卷积层使用较大的接受域(如2012,步长为4的11*11;2013,步长为2的7*7),而是在整个网络使用3*3的接受域。
所有隐含层都使用ReLU
分类框架
上一节,展示了我们网络配置的细节。这一节,我们描述分类卷积网络的训练和评估细节。
- 训练
- 测试
- 实现细节
分类实验
结论
本文,我们评估了非常深的卷积网络(达到19个权值层)在大规模图像分类中的性能表现。结果表明,深度有利于提高分类的准确度。传统卷积网络(如LeCun),增加深度也能在ImageNet数据集上取得更好的效果。附录中,展示了我们的模型在大范围的任务和数据集上的良好泛化能力,达到或者超越了较浅深度的图像表达在更复杂的识别pipeline中的效果,也再次证明了深度对视觉表达的重要性。
个人理解
1、16~19个权值层
VGG(Visual Geometry Group,牛津大学的视觉几何组)