小编今天在做Sharding-jdbc时出现了一些问题,就上网百一百,发现网上的sharding-jdbc的参考是挺少的,唉还是要继续学习看文档。
Sharding-jdbc介绍
Sharding-JDBC是当当应用框架ddframe中,关系型数据库模块dd-rdb中分离出来的数据库水平扩展框架,即透明化数据库分库分表访问。
在互联网高并发的时代,为了应付DB的高并发读写,我们会采用读写分离技术。读写分离指的是利用数据库主从技术(把数据复制到多个节点中),分散读多个库以支持高并发的读,而写只在master库上。DB的主从技术只负责对数据进行复制和同步,而读写分离技术需要业务应用自身去实现。sharding-jdbc通过简单的开发,可以方便的实现读写分离技术。
读写分离实现
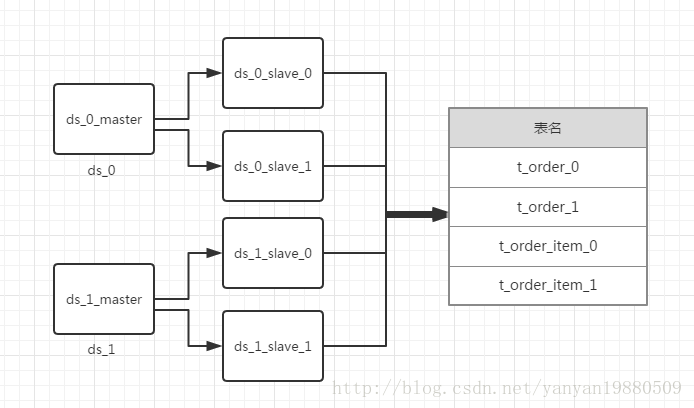
库和表结构设计图:
代码示例
这里我采用了SSH来做的测试(Spring+Struts2+Hibernate)配置请参考: http://www.cnblogs.com/niechen/p/8619713.html
这里我们采用yml的方式进行分库分表,这里只演示了分表,分库的原理是一样的 首先创建sharding-jdbc-core.yml文件
dataSources: ds: !!com.alibaba.druid.pool.DruidDataSource driverClassName: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/数据库 username: root password: shardingRule: tables: class: actualDataNodes: ds.class_${0..3} tableStrategy: inline: shardingColumn: id algorithmExpression: class_${id % 4} keyGeneratorColumnName: id defaultKeyGeneratorClass: com.bdqn.lyrk.ssh.study.generator.MyKeyGenerator
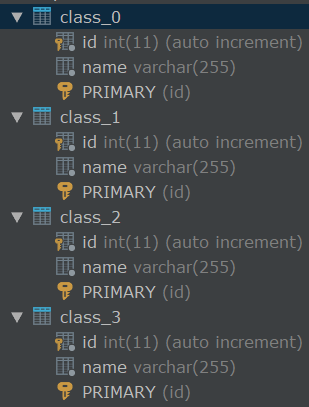
采用了4张表为例子
这里简单介绍一下上面是数据的拆分这里只做了一个 数据源 !!后面跟的是我们使用的那种数据源有很多dbcp等等..这里用的阿里的druid,后面的不用多说了吧
下面是对表的拆分
class:代表的是逻辑表名
actualDataNodes:数据源名.class_${0..3} 也就是class_0,class_1,class_2,class_3对应的这三张表 ,如果是多个数据源的话就是:数据源名_${....}.class_${0..3}
tableStategy下面的参数是设置拆表的规范
shardingColumn:根据哪一列来约定拆表,一般我们都根据主键 所以这里是id
algorithmExpression:约定了拆表的规则,这里是4张表对应0,1,2,3,那么如果对4求余那么值肯定在0~3之间,那么所以是class_${id % 4}
keyGeneratorColumnName:这里指定的是id的生成器
defaultKeyGenerotorClass:指定对应我们自己的生成器


package com.bdqn.lyrk.ssh.study.generator; import io.shardingjdbc.core.keygen.KeyGenerator; import org.springframework.context.annotation.Configuration; import java.util.Random; /** * @author 杨天乐 * @date 2018/4/16 21:10 */ @Configuration public class MyKeyGenerator implements KeyGenerator { @Override public Number generateKey() { Random random = new Random(); int rom= random.nextInt(100); return rom; } }
注意这里用Random生成不要用Math来生成,不然会有小数,那么一定找不到对应的表,这是小编今天遇到坑爹的问题之一。
接下来我们要加载刚才配置的yml,我们创建一个ShardingJdbcConfig.java
package com.bdqn.lyrk.ssh.study.config; import io.shardingjdbc.core.api.ShardingDataSourceFactory; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import javax.sql.DataSource; import java.io.File; import java.io.IOException; import java.sql.SQLException; /** * @author 杨天乐 * @date 2018/4/16 17:10 */ @Configuration public class ShardingJdbcConfig { @Bean public DataSource dataSource() throws IOException, SQLException { DataSource dataSource = ShardingDataSourceFactory.createDataSource(new File( ShardingJdbcConfig.class.getClassLoader().getResource("sharding-jdbc-core.yml").getFile())); return dataSource; } }
加载我们yml配置。这里一定要从ClassLoader里才能拿到配置
接下来我们来测试一下添加操作(业务层我就不写了,就一个hibernate的save方法),插入5条数据看他们分别都插入到了哪?(表的数据我都清空了)

这是我插入的5条数据按顺序0~3
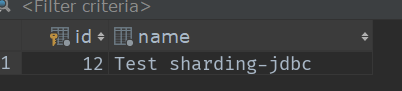
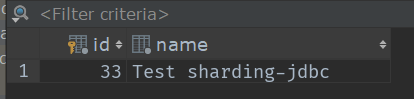
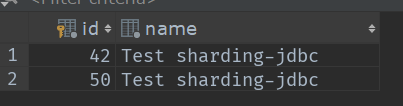
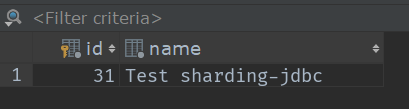
大家也可以根据这些id来求一下余,看对应表吗?
参考sharding官方文档和官方demo,SSH集成例子 http://www.cnblogs.com/niechen/p/8619713.html