首先了解一下消息队列。
对于传统消息队列,遇到下述情况,可以使用消息队列进行改造。
那么使用消息队列的好处?
1.解耦,可以独立扩展以及修改两边的处理过程,只需要确保接口的一致性即可,
2.可恢复性,当系统中一部分组件失效时候,不会影响整个系统,消息队列降低了程序之间的耦合度,因此当处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复之后被处理
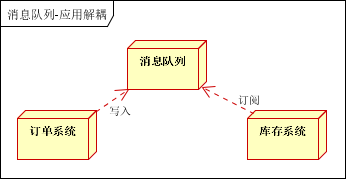
举个例子:对于电商系统的订购,对于常规操作,可能订单系统在在调用库存系统时,由于库存系统故障,导致订单创建失败,订单系统与库存系统高度耦合
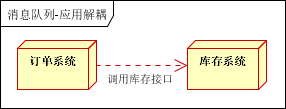
那么引入消息队列,订单系统创建订单完成之后,将减少库存放入消息队列中,就算库存系统崩溃,订单系统也可以完成创建,并且在库存系统启动之后读取消息队列中的信息,完成较少库存任务。
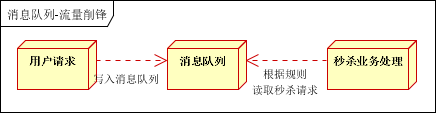
3.流量削峰,在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这个突发流量并不常见,如果以能处理这类的访问标准来投入资源随时待命,这就是巨大的浪费,当然对于可预见的比如双十一,这个增加应用的副本数量无疑对用户体检以及访问速度会提升很多。对于这种情况,消息队列可以换件短时间内高流量压垮应用。
举个例子,例如秒杀活动,有时候会瞬间带来超大的用户访问量,这个时候容易造成服务器瘫痪,这个时候引入消息队列,秒杀系统逐步处理消息队列中情况,可以短时间缓解系统压力
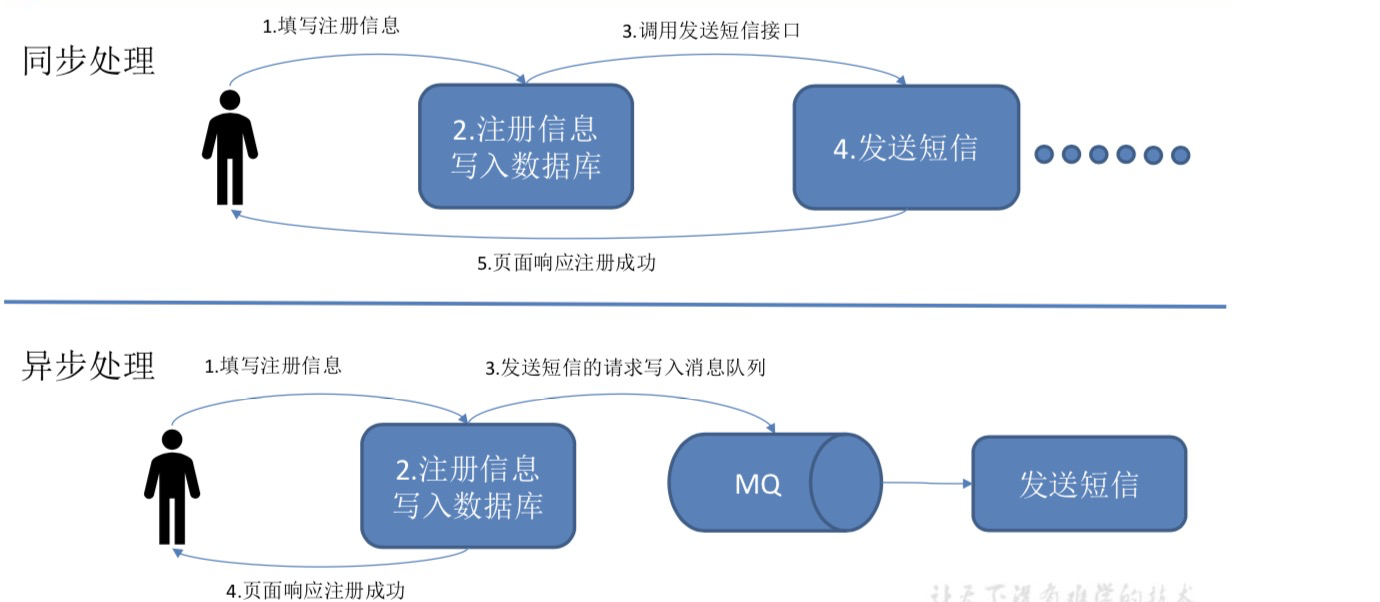
4.异步通信,有时候对于产生出的消息,用户并不想立即进行处理,这个石斛可以放入消息队列中,以后想处理的时候在进行处理。
消息队列分为两种模式:
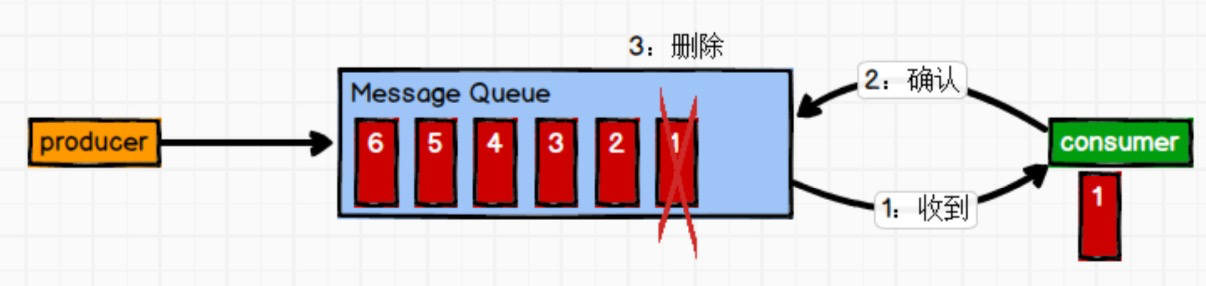
1.点对点模式,也即是P2P(point to point)
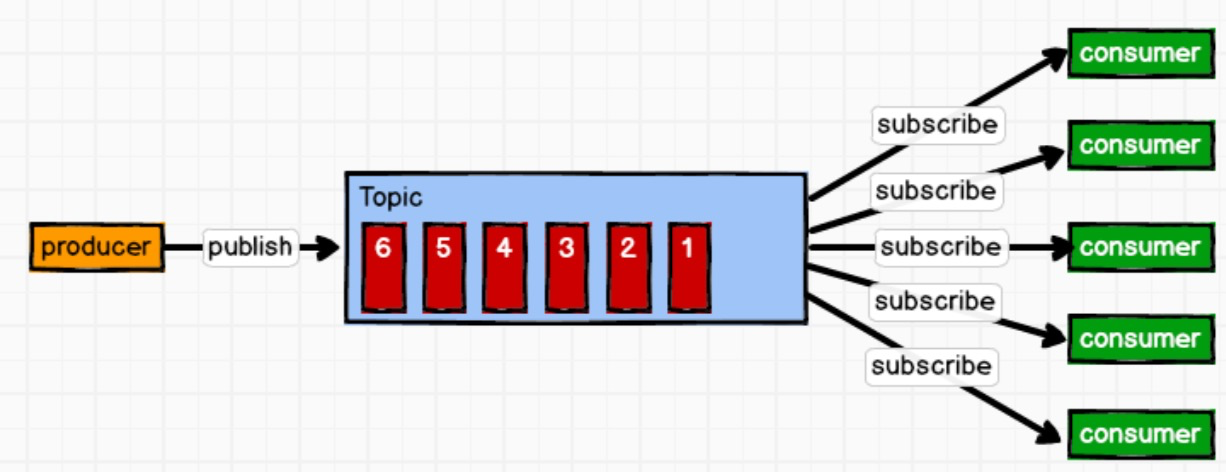
2. 发布/订阅模式,也就是Pub/Sub模式
这个包含三个角色:主题(Topic),生产者(producer),消费者(consumer)。多个消费者可以将消息发送到Topic中,系统将这些消息传递给多个消费者。
发不到Topic的消息会被所有的订阅者消费
kafka就是一个发布订阅的模式。看一下kafka的官方介绍
kafka是一个分布式流数据处理平台,那么流数据处理平台一般都有下述三个特性
1.可以发布以及订阅流式的记录
2.储存流式的记录,并且有较好的容错性
3.在流式记录产生时就进行处理
那么kafka一般适用于的应用类别:
1.构造实时流数据管道,可以在系统或者应用之间可靠的获取数据
2.构建实时流式应用程序,对这些流数据进行转换或者影响。
kafka的概念:
1.kafka作为一个集群,运行在一台或者多台服务器上
2.kafka通过topic对存储的流数据进行分类
3.每条记录包含一个key,一个value和一个timestamp(时间戳)
kafka的四个核心API:
1. The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个kafka topic
2.The Consumer API 允许一个应用程序订阅一个或多个topic,并且对发布给他们的流式数据进行处理
3.The Streams API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或者多个topic中去,在输入输出流中进行有效的转换
4.The Connector API 允许构建并运行可重用的生产者或消费者,将kafka topics连接到已存在的应用程序挥着数据吸用。比如连接到一个关系型数据库,捕捉表的所有变更内容。
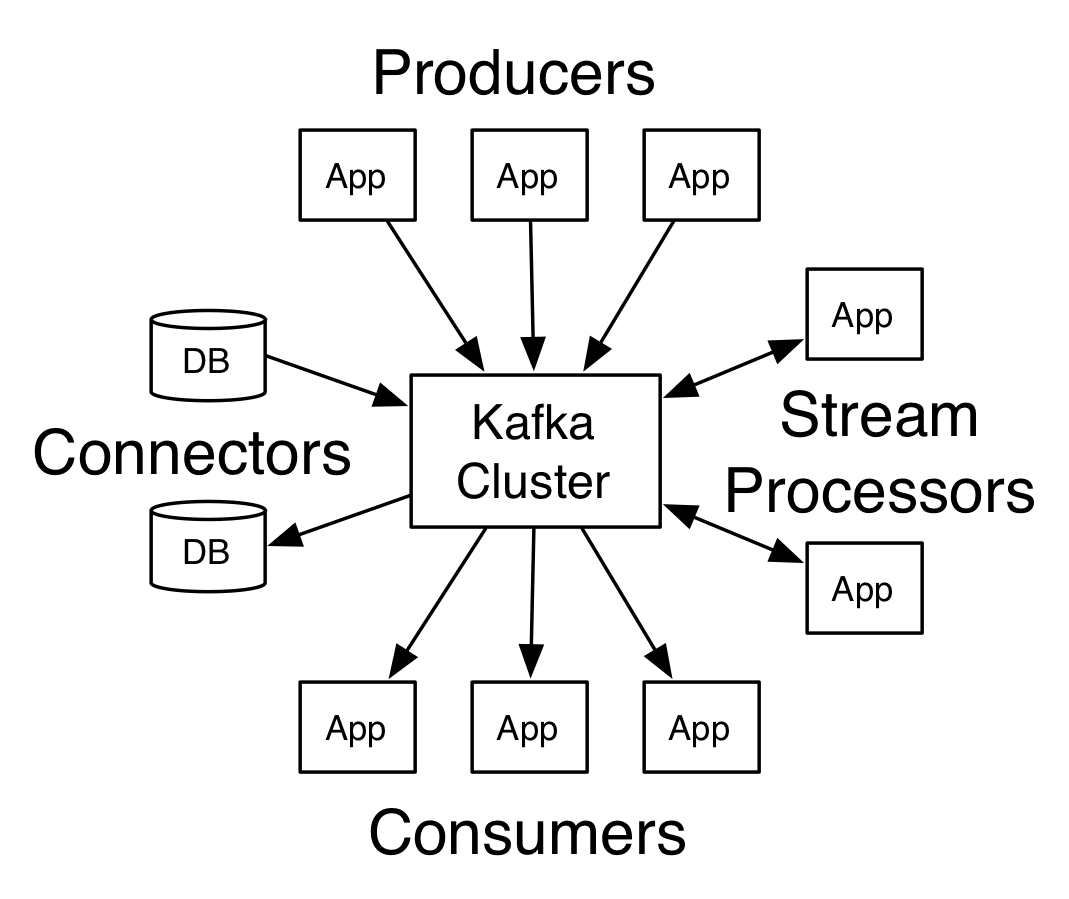
kafka客户端以及服务端通信使用的是简单,高性能支持多语言的TCP协议 。
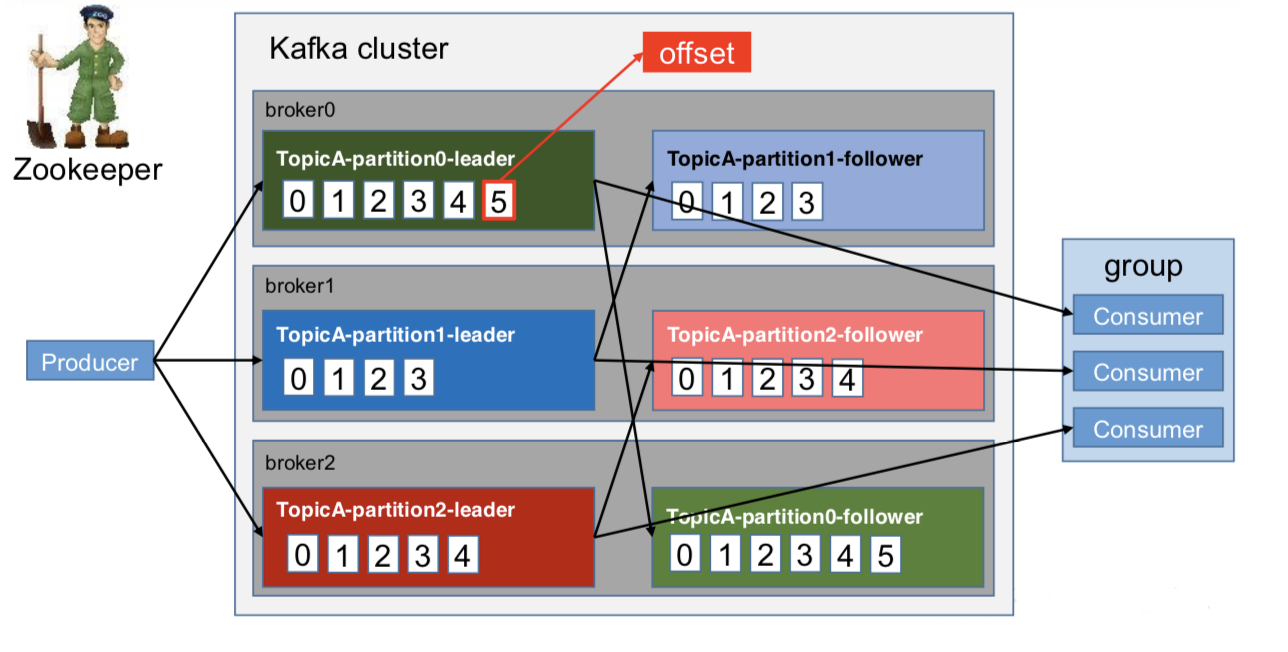
Kafka的基础架构:
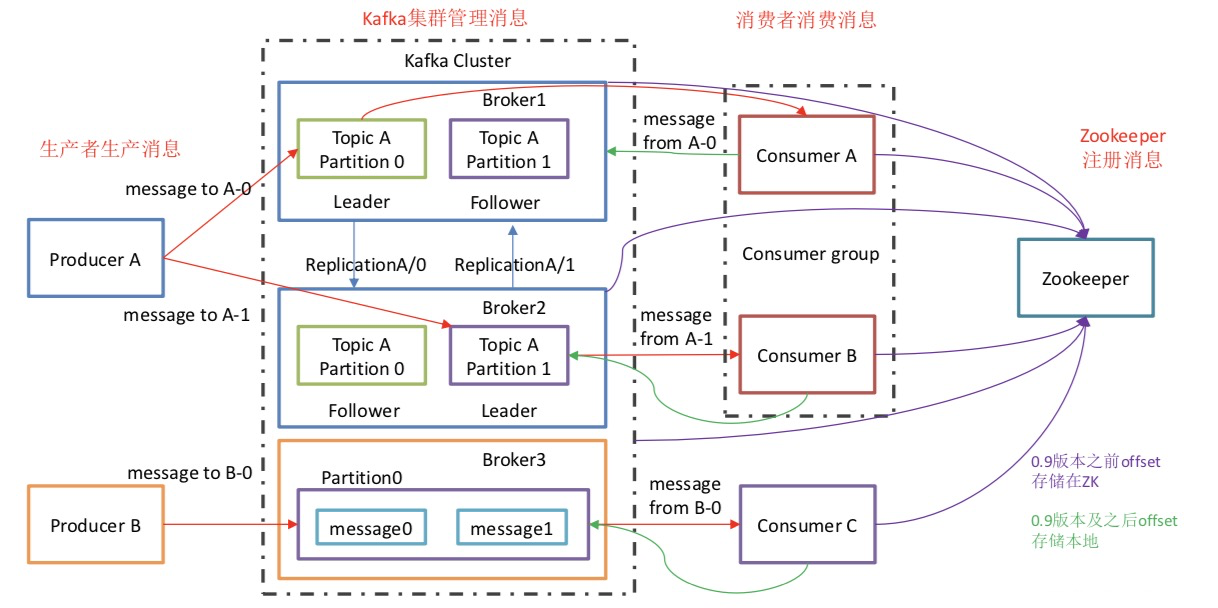
1.Producer:消息生产者,也就是向kafka broker发消息的客户端
2.Consumer:消息消费者,从kafka broker中去消息的客户端
3.Consumer Group:消费者组,由多个consumer组成。消费这组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,消费组之间互不影响。所有的消费者都属于某个消费组,也就是消费者组在逻辑上其实是一个订阅者
4.Broker:一台kafka服务器就是一个broker,一个集群由多个broker组成,一个broker可以融安多个topic
5.Topic:相当于一个队列,生产者以及消费者面向的都是一个topic
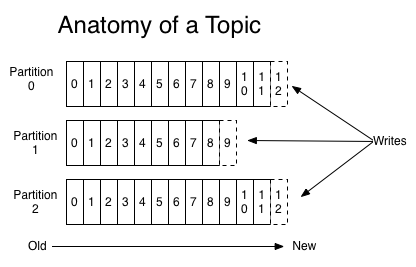
6.Partition:分区。主要是为了实现可扩展性,一个非常大的topic可以分布到多个broker上,一个topic可以分为多个partition,每个partition都是一个有序的队列
7.Replica:副本,为保证集群中的某个节点发生故障,这个节点的partition数据不对事,并且kafka仍可以进行正常工作,kafka提供了副本机制,一个topic的每个分区可以有若干个副本,一个leader和若干个follower,leader与follower不再同一个服务器上,部署在一个服务器上没有意义,因此副本数量加上leader一般小于等于服务器数量
8.leader:每个分区多个副本的“主”,生产这发送数据的对象,以及消费者消暑数据的对象都是leader
9.follower:每个分区多个副本的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障是,某个follower会成为新的leader。