说一下浏览器缓存:
强缓存相关字段有expires,cache-control。如果cache-control与expires同时存在的话,cache-control的优先级高于expires。
协商缓存相关字段有Last-Modified/If-Modified-Since,Etag/If-None-Match

fetch发送2次请求的原因:
fetch发送post请求的时候,总是发送2次,第一次状态码是204,第二次才成功?
原因很简单,因为你用fetch的post请求的时候,导致fetch 第一次发送了一个Options请求,询问服务器是否支持修改的请求头,如果服务器支持,则在第二次中发送真正的请求。
第一次是探域,至于跨域的情况下才会发送两次
在地址栏里输入一个URL,到这个页面呈现出来,中间会发生什么?
TCP连接
发送HTTP请求
服务器处理请求并返回HTTP报文
浏览器解析渲染页面
连接结束
当浏览器接收到服务器相应来的HTML文档后,会遍历文档节点,生成DOM树,
CSSOM规则树由浏览器解析CSS文件生成,
csrf和xss的网络攻击及防范
XSS:跨站脚本攻击,是说攻击者通过注入恶意的脚本,在用户浏览网页的时候进行攻击,比如获取cookie,或者其他用户身份信息,可以分为存储型和反射型,存储型是攻击者输入一些数据并且存储到了数据库中,其他浏览者看到的时候进行攻击,反射型的话不存储在数据库中,往往表现为将攻击代码放在url地址的请求参数中,防御的话为cookie设置httpOnly属性,对用户的输入进行检查,进行特殊字符过滤
描述一下XSS和CRSF攻击?防御方法?
CSRF(Cross Site Request Forgery,跨站请求伪造),字面理解意思就是在别的站点伪造了一个请求。专业术语来说就是在受害者访问一个网站时,其 Cookie 还没有过期的情况下,攻击者伪造一个链接地址发送受害者并欺骗让其点击,从而形成 CSRF 攻击。
XSS防御的总体思路是:对输入(和URL参数)进行过滤,对输出进行编码。也就是对提交的所有内容进行过滤,对url中的参数进行过滤,过滤掉会导致脚本执行的相关内容;然后对动态输出到页面的内容进行html编码,使脚本无法在浏览器中执行。虽然对输入过滤可以被绕过,但是也还是会拦截很大一部分的XSS攻击。
防御CSRF 攻击主要有三种策略:验证 HTTP Referer 字段;在请求地址中添加 token 并验证;在 HTTP 头中自定义属性并验证。
说一下对Cookie和Session的认知,Cookie有哪些限制?
2. cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
考虑到安全应当使用session。
3. session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能
考虑到减轻服务器性能方面,应当使用COOKIE。
4. 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
什么是BFC?什么是IFC?
不要试图去讲解 BFC 的定义!!
如何说明 BFC ,举例子!!不要试图去讲定义!!
格式化上下文(block formatting context)
当一个HTML元素满足下面条件的任何一点,都可以产生Block Formatting Context:
a、float的值不为none
b、overflow的值不为visible
c、display的值为table-cell, table-caption, inline-block中的任何一个
d、position的值不为relative和static
IFC(Inline Formatting Context)即行内格式化上下文。常规流(也称标准流、普通流)是一个文档在被显示时最常见的布局形态。
(块级格式化上下文,用于清楚浮动,防止margin重叠等)
BFC区域不会与float box重叠
BFC是页面上的一个独立容器,子元素不会影响到外面
计算BFC的高度时,浮动元素也会参与计算
那些元素会生成BFC:
根元素
float不为none的元素
position为fixed和absolute的元素
display为inline-block、table-cell、table-caption,flex,inline-flex的元素
overflow不为visible的元素
BFC 特性(功能)
- 使 BFC 内部浮动元素不会到处乱跑;
- 和浮动元素产生边界。
画一条0.5px的线
<meta name="viewport" content="initial-scale=1.0, maximum-scale=1.0, user-scalable=no" />
采用border-image的方式
采用transform: scale()的方式
.hairline-bottom { position: relative; border: none; } .hairline-bottom::after { content: ""; position: absolute; left: 0; bottom: 0; border-bottom: 1px solid #dddee3; 100%; -webkit-transform: scale(1, 0.5); transform: scale(1, 0.5); -webkit-transform-origin: center bottom; transform-origin: center bottom; z-index: 1; }
介绍一下盒模型
标准盒模型:一个块的总宽度=width+margin(左右)+padding(左右)+border(左右)
怪异盒模型:一个块的总宽度=width+margin(左右)(既width已经包含了padding和border值)
设置盒模型:box-sizing:border-box
对象深度克隆的简单实现
function deepClone(obj){ var newObj= obj instanceof Array ? []:{}; for(var item in obj){ var temple= typeof obj[item] == 'object' ? deepClone(obj[item]):obj[item]; newObj[item] = temple; } return newObj; } ES5的常用的对象克隆的一种方式。注意数组是对象,但是跟对象又有一定区别,所以我们一开始判断了一些类型,决定newObj是对象还是数组~
null == undefined为什么
要比较相等性之前,不能将null 和 undefined 转换成其他任何值,但 null == undefined 会返回 true 。ECMAScript规范中是这样定义的。
简单介绍一下symbol
Symbl确保唯一,即使采用相同的名称,也会产生不同的值,我们创建一个字段,仅为知道对应symbol的人能访问,使用symbol很有用,symbol并不是100%隐藏,有内置方法Object.getOwnPropertySymbols(obj)可以获得所有的symbol。
也有一个方法Reflect.ownKeys(obj)返回对象所有的键,包括symbol。
所以并不是真正隐藏。但大多数库内置方法和语法结构遵循通用约定他们是隐藏的
NaN
NaN是JS中的特殊值,表示非数字,NaN不是数字,但是他的数据类型是数字,它不等于任何值,包括自身,在布尔运算时被当做false,NaN与任何数运算得到的结果都是NaN,
redux里常用方法
提供 dispatch(action) 方法更新 state;
通过 subscribe(listener) 注册监听器;
react的生命周期函数


初始化 1、getDefaultProps() 设置默认的props,也可以用dufaultProps设置组件的默认属性. 2、getInitialState() 在使用es6的class语法时是没有这个钩子函数的,可以直接在constructor中定义this.state。此时可以访问this.props 3、componentWillMount() 组件初始化时只调用,以后组件更新不调用,整个生命周期只调用一次,此时可以修改state。 4、 render() react最重要的步骤,创建虚拟dom,进行diff算法,更新dom树都在此进行。此时就不能更改state了。 5、componentDidMount() 组件渲染之后调用,只调用一次。 更新 6、componentWillReceiveProps(nextProps) 组件初始化时不调用,组件接受新的props时调用。 7、shouldComponentUpdate(nextProps, nextState) react性能优化非常重要的一环。组件接受新的state或者props时调用,我们可以设置在此对比前后两个props和state是否相同,如果相同则返回false阻止更新,因为相同的属性状态一定会生成相同的dom树,这样就不需要创造新的dom树和旧的dom树进行diff算法对比,节省大量性能,尤其是在dom结构复杂的时候 8、componentWillUpdata(nextProps, nextState) 组件初始化时不调用,只有在组件将要更新时才调用,此时可以修改state 9、render() 组件渲染 10、componentDidUpdate() 组件初始化时不调用,组件更新完成后调用,此时可以获取dom节点。 卸载 11、componentWillUnmount() 组件将要卸载时调用,一些事件监听和定时器需要在此时清除。
setState之后的流程
在代码中调用setState函数之后,React 会将传入的参数对象与组件当前的状态合并,然后触发所谓的调和过程(Reconciliation)。 经过调和过程,React 会以相对高效的方式根据新的状态构建 React 元素树并且着手重新渲染整个UI界面。 在 React 得到元素树之后,React 会自动计算出新的树与老树的节点差异,然后根据差异对界面进行最小化重渲染。 在差异计算算法中,React 能够相对精确地知道哪些位置发生了改变以及应该如何改变,这就保证了按需更新,而不是全部重新渲染。
tcp三次握手过程
第二次握手:Server收到数据包后由标志位SYN=1得知Client请求建立连接,Server将标志位SYN和ACK都置为1,ack=x+1,随机产生一个值seq=y,并将该数据包发送给Client以确认连接请求,Server进入SYN-RCVD状态,此时操作系统为该TCP连接分配TCP缓存和变量;
第三次握手:Client收到确认后,检查ack是否为x+1,ACK是否为1,如果正确则将标志位ACK置为1,ack=y+1,并且此时操作系统为该TCP连接分配TCP缓存和变量,并将该数据包发送给Server,Server检查ack是否为y+1,ACK是否为1,如果正确则连接建立成功,Client和Server进入ESTABLISHED状态,完成三次握手,随后Client和Server就可以开始传输数据。
TCP和UDP的区别,为什么三次握手四次挥手
TCP和UDP之间的区别 OSI 和TCP/IP 模型在传输层定义两种传输协议:TCP(或传输控制协议)和UDP(或用户数据报协议)。 UDP 与TCP 的主要区别在于UDP 不一定提供可靠的数据传输。 事实上,该协议不能保证数据准确无误地到达目的地。 为什么TCP要进行四次挥手呢? 因为是双方彼此都建立了连接,因此双方都要释放自己的连接,A向B发出一个释放连接请求,他要释放链接表明不再向B发送数据了,此时B收到了A发送的释放链接请求之后,给A发送一个确认,A不能再向B发送数据了,它处于FIN-WAIT-2的状态,但是此时B还可以向A进行数据的传送。此时B向A 发送一个断开连接的请求,A收到之后给B发送一个确认。此时B关闭连接。A也关闭连接。 为什么要有TIME-WAIT这个状态呢,这是因为有可能最后一次确认丢失,如果B此时继续向A发送一个我要断开连接的请求等待A发送确认,但此时A已经关闭连接了,那么B永远也关不掉了,所以我们要有TIME-WAIT这个状态。 当然TCP也并不是100%可靠的。
Redis和 mysql
(1)类型上 从类型上来说,mysql是关系型数据库,redis是缓存数据库 (2)作用上 mysql用于持久化的存储数据到硬盘,功能强大,但是速度较慢 redis用于存储使用较为频繁的数据到缓存中,读取速度快 (3)需求上 mysql和redis因为需求的不同,一般都是配合使用。
git 怎么删除一个远程/本地分支
删除远程分支
git push origin --delete dev
删除本地分支
git branch -d dev
查看分支情况
git branch -a
两个数组比较,判断是否有相同元素
要判断JS中的两个数组是否相同,需要先将数组转换为字符串,再作比较。以下两行代码将返回true
<script type="text/javascript"> alert([].toString()== [].toString()); alert([].toString()===[].toString()); </script>
数组去重一般用什么方法,数据量大又用什么方法
/* * 速度最快, 占空间最多(空间换时间) * * 该方法执行的速度比其他任何方法都快, 就是占用的内存大一些。 * 现思路:新建一js对象以及新数组,遍历传入数组时,判断值是否为js对象的键, * 不是的话给对象新增该键并放入新数组。 * 注意点:判断是否为js对象键时,会自动对传入的键执行“toString()”, * 不同的键可能会被误认为一样,例如n[val]-- n[1]、n["1"]; * 解决上述问题还是得调用“indexOf”。*/ function uniq(array){ var temp = {}, r = [], len = array.length, val, type; for (var i = 0; i < len; i++) { val = array[i]; type = typeof val; if (!temp[val]) { temp[val] = [type]; r.push(val); } else if (temp[val].indexOf(type) < 0) { temp[val].push(type); r.push(val); } } return r; } var aa = [1,2,"2",4,9,"a","a",2,3,5,6,5]; console.log(uniq(aa));
const removeDuplicateItems = arr => [...new Set(arr)]; console.log(removeDuplicateItems([42, 'foo', 42, 'foo', true, true])); // => [42, "foo", true]
set和obj
数据量大就用排序方法去重呗
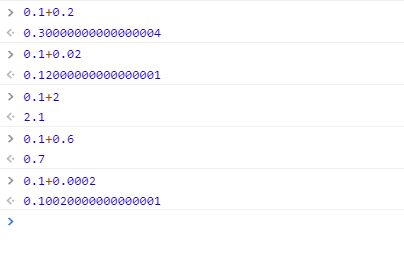
为什么JS中0.1+0.2 != 0.3
由于0.1转换成二进制时是无限循环的,所以在计算机中0.1只能存储成一个近似值。
WebView和原生是如何通信
== 和 ===的区别,什么情况下用相等==
两个对象如何比较
https://www.jianshu.com/p/90ed8b728975
prototype和——proto——区别
JS为什么要区分微任务和宏任务
发布-订阅和观察者模式的区别
for..in 和 object.keys的区别
获取对象的属性的方法

关于标题中方法和语句的基本用法可以参阅如下两篇文章:
(1).JavaScript Object.keys()一章节。
(2).JavaScript for in 语句一章节。
Object.keys方法对数组进行遍历操作,可以看到获取的是数组的索引。
数组的索引都是数字,但是通过此方法获取的都会被转换为字符串。
for in语句:
此语句可以遍历普通对象,也可以遍历数组,但是不建议使用它遍历数组。
三.异同总结如下:
(1).都可以遍历对象与数组。
(2).获取的都是对象或者数组的键(数组的键就是元素索引),获取的值都会被转换为字符串。
(3).获取键的顺序两者是完全相同的。
(4).浏览器支持有所差异,Object.keys方法低版本IE浏览器不支持。
(5).Object.keys方法不会获取原型链上的键,但是for in是可以的。
react的理念是什么(拿函数式编程来做页面渲染)
JS是什么范式语言(面向对象还是函数式编程)
输出下面的执行顺序
setTimeout(function(){ console.log('1') }); new Promise(function(resolve){ console.log('2'); resolve(); }).then(function(){ console.log('3') }); console.log('4');
看一下宏任务和微任务
同步和异步任务分别进入不同的执行"场所",同步的进入主线程,异步的进入Event Table并注册函数。当指定的事情完成时,Event Table会将这个函数移入Event Queue。主线程内的任务执行完毕为空,会去Event Queue读取对应的函数,进入主线程执行。上述过程会不断重复,也就是常说的Event Loop(事件循环)。
而宏任务一般是:包括整体代码script,setTimeout,setInterval。
微任务:Promise,process.nextTick。
记住就行了。
所以正确的执行结果当然是:
2,4,3,1。
因为settimeout是宏任务,虽然先执行的他,但是他被放到了宏任务的eventqueue里面,然后代码继续往下检查看有没有微任务,检测到Promise的then函数把他放入了微任务序列。等到主线进程的所有代码执行结束后。先从微任务queue里拿回掉函数,然后微任务queue空了后再从宏任务的queue拿函数。