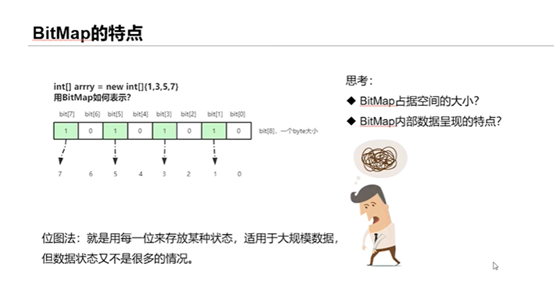
介绍
布隆过滤器(Bloom Filter,下文简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率高的概率型数据结构。它专门用来检测集合中是否存在特定的元素。
设计思想
布隆过滤器是由一个长度为m比特的位数组(bit array)与k个哈希函数(hash function)组成的数据结构。位数组均初始化为0,所有哈希函数都可以分别把输入数据尽量均匀地散列。
原理
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
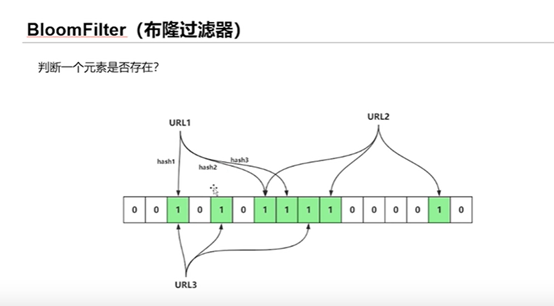
当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
使用场景
- 判断给定数据是否存在:比如判断一个数字是否在于包含大量数字的数字集中(数字集很大,5亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
- 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
布隆过滤器判断存在的不一定存在,但是判断不存在的一定不存在。
特点
1、由于存放的不是完整的数据,所以占用的内存很小,而且新增、查询的速度够快;
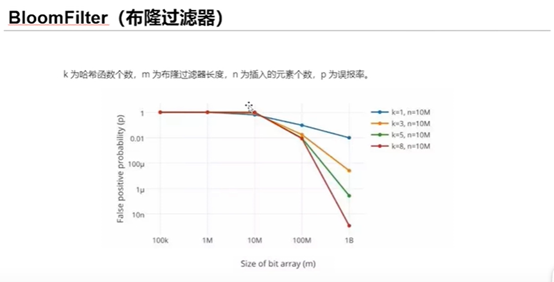
2、多个hash,增加随机性,减少hash碰撞的概率;
3、扩大数组范围,使hash值均匀分布,进一步减少hash碰撞的概率。随着数据的增加,误判率随之增加。
4、返回的结果是概率性的,不是确切性的。只能判断数据是否一定不存在,而无法判断数据是否一定存在。
5、删除很麻烦,可以维护一个记录位数组中1的个数来删除,1的个数为0时,位数组中对应的位置变为0,但是这样失去了其快速判断的意义。
其他