摘要: 在密码学中,加盐是指在散列之前将散列内容(例如:密码)的任意固定位置插入特定的字符串。这个在散列中加入字符串的方式称为“加盐”。其作用是让加盐后的散列结果和没有加盐的结果不相同,在不同的应用情景中,这个处理可以增加额外的安全性。
1. 加盐能解决什么问题?
加盐能解决HBASE读写热点问题,例如:单调递增rowkey数据的持续写入,使得负载集中在某一个RegionServer上引起的热点问题。
2. 盐表的实现原理
加盐原理图解:
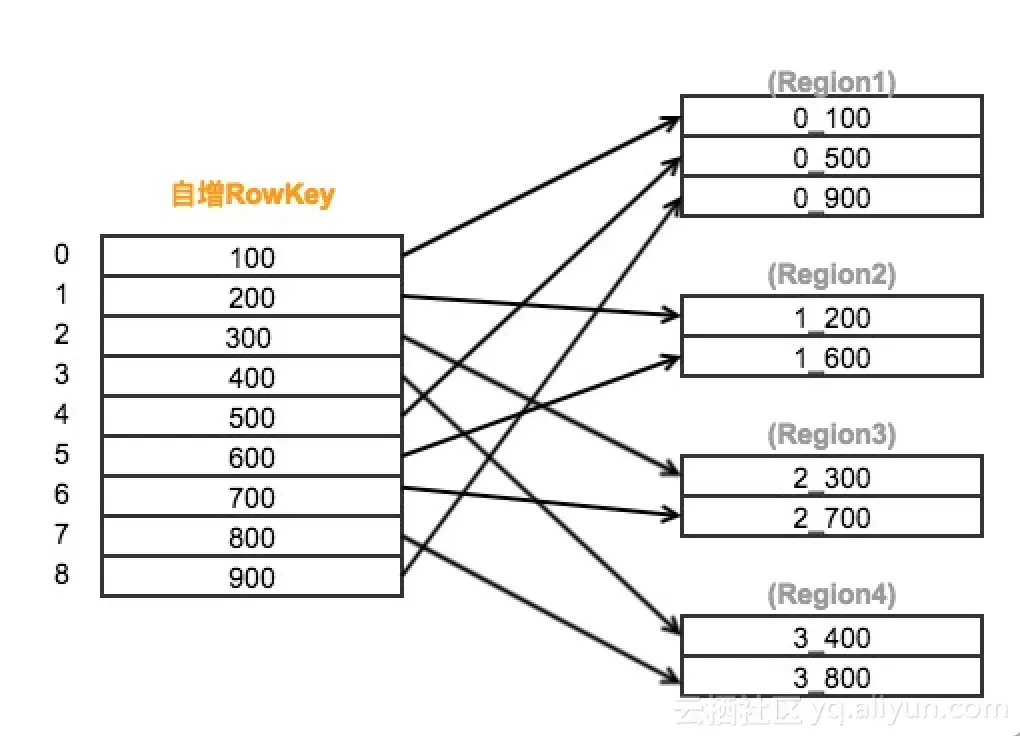
Phoenix Salted Table的实现原理是在将一个散列取余后的byte值插入到 rowkey的第一个字节里,并通过定义每个region的start key 和 end key 将数据分割到不同的region,以此来防止自增序列引入的热点问题,从而达到平衡HBase集群的读写性能的目的。
加盐的过程就是在原来key的基础上增长一个byte做为前缀,salted byte的计算方式大致如下:
new_row_key = ((byte) (hash(key) % BUCKETS_NUMBER) + original_key
Phoenix Salted Table是phoenix为了防止hbase表rowkey设计为自增序列而引发热点region读和热点region写而采取的一种表设计手段。通过在创建表的时候指定SALT_BUCKETS来实现pre-split(预分割)。如下表示创建表的时候将表预分割到20个region里面。
CREATE TABLE SALT_TEST (a_key VARCHAR PRIMARY KEY, a_col VARCHAR) SALT_BUCKETS = 20;
#表指定分区数 CREATE TABLE test_salt ( hrid varchar not null primary key, parentid bigint, departmentid varchar )SALT_BUCKETS=40; #索引指定分区数 (索引不指定预分区数时,其默认分区数与表保持一致) CREATE INDEX idx_test_salt_departmentid ON TESTN(departmentid) SALT_BUCKETS=20;
又比如:
CREATE TABLE IF NOT EXISTS Product ( id VARCHAR not null, time VARCHAR not null, price FLOAT, sale INTEGER, inventory INTEGER, CONSTRAINT pk PRIMARY KEY (id, time) ) COMPRESSION = 'GZ', SALT_BUCKETS = 6;
默认情况下,对salted table创建二级索引,二级索引表会随同源表切进行Salted切分,SALT_BUCKETS与源表保持一致。当然,在创建二级索引表的时候也可以自定义SALT_BUCKETS的数量,phoenix没有强制它的数量必须跟源表保持一致。
由于加了盐的数据最前面多了一位,这样默认情况下,从不同 region server 取出来的数据无法按原来的 row key 排序,如果需要保证排序,需要改一个配置。
3. 一个表“加多少盐合适”?
- 当可用block cache的大小小于表数据大小时,较优的slated bucket是和region server数量相同,这样可以得到更好的读写性能。
- 当表的数量很大时,基本上会忽略blcok cache的优化收益,大部分数据仍然需要走磁盘IO。比如对于10个region server集群的大表,可以考虑设计64~128个slat buckets。
4. 特别注意
可以看到,在每条rowkey前面加了一个Byte,这里显示为了16进制。也正是因为添加了一个Byte,所以SALT_BUCKETS的值范围在必须再1 ~ 256之间。而添加的这个Byte是根据什么来分的我就不得而知了,所以最好不要使用HBase的API插入数据。
因此,在使用SALT_BUCKETS的时候需要注意以下几点:
4.1 创建salted table后,应该使用Phoenix SQL来读写数据,而不要混合使用Phoenix SQL和HBase API
4.2 如果通过Phoenix创建了一个salted table,那么只有通过Phoenix SQL插入数据才能使得被插入的原始rowkey前面被自动加上一个byte,通过HBase shell插入数据无法prefix原始的rowkey
比如使用Hbase的BulkLoad API向SALT_BULKET的表中插入数据中插入数据,会出现ROW_KEY的第一个字节在Phoenix中查看少一位的情况,并且在Phoenix中使用ROW_KEY查询会出现查询不到结果的情况。
4.3 创建加盐表时不能再指定split key。
4.4 太大的slated buckets会减小range查询的灵活性,甚至降低查询性能。
4.5 加盐属性不等同于split key, 一个bucket能够对应多个region。
参考博客:Phoenix 加盐与优化