Hive拉链表原理
拉链表记录每条信息的生命周期,一旦记录的生命周期结束,就重新开始一条新记录,并且把当前日期作为新记录生效开始日期。
如果当前信息至今有效,在生命周期结束中填入一个极大值(‘9999-99-99’)。
应用场景:
1需要查看某些业务信息的某一个时间点当日的信息
2数据会发生变化,但是大部分是不变的,无法做每日增量。
3数据量有一定规模。无法按照每日全量的方式保存,比如1亿用户*365天,每天一份用户信息,显然不太合适。
拉链表的形成过程:
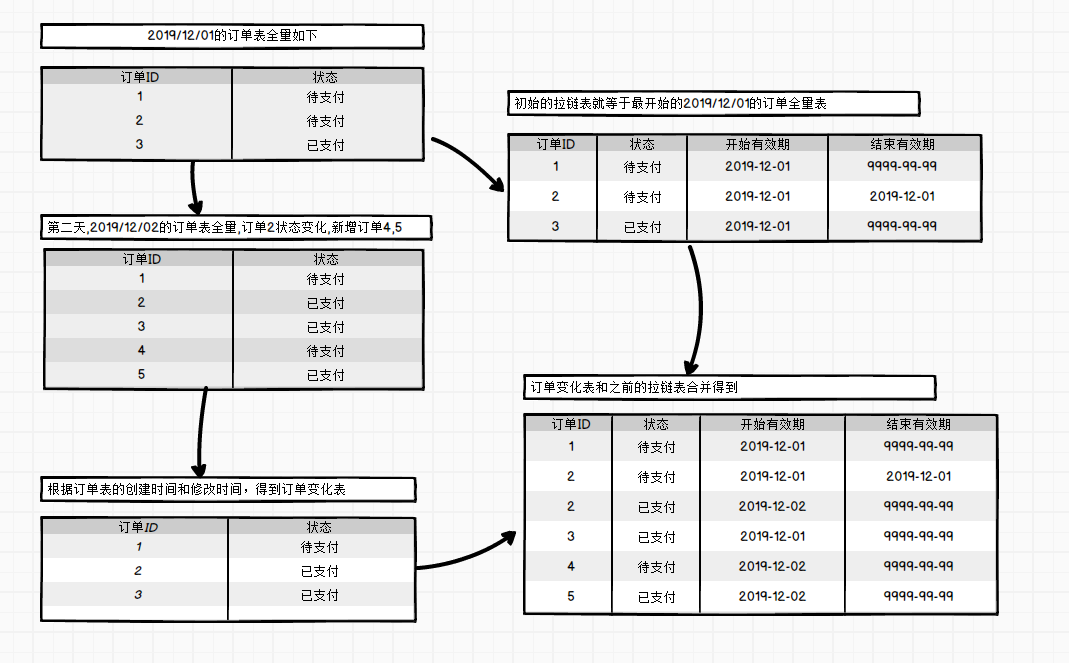
如何使用拉链表:
获取某个时间点的数据。
只要指定开始生效期比它小,结束生效期比它大就可以。
如获取2019/12/01这一天的状态的数据。
select * from order_info where start_date<='2019-12-01' and end_date>='2019-12-01';
拉链表的适用场景
维护历史状态,以及最新状态数据
适用场景:
1.数据量比较大
2.表中的部分字段会被更新
3.需要查看某一个时间点或者时间段的历史快照信息
查看某一个订单在历史某一个时间点的状态
某一个用户在过去某一段时间,下单次数
4.更新的比例和频率不是很大
如果表中信息变化不是很大,每天都保留一份全量,那么每次全量中会保存很多不变的信息,对存储是极大的浪费
优点
1、满足反应数据的历史状态
2、最大程度节省存储
拉链表的实现
拉链表适用于以下几种情况吧
数据量有点大,表中某些字段有变化,但是呢变化的频率也不是很高,业务需求呢又需要统计这种变化状态,每天全量一份呢,有点不太现实,
不仅浪费了存储空间,有时可能业务统计也有点麻烦,这时,拉链表的作用就提现出来了,既节省空间,又满足了需求。
假设以天为维度,以每天的最后一个状态为当天的最终状态。
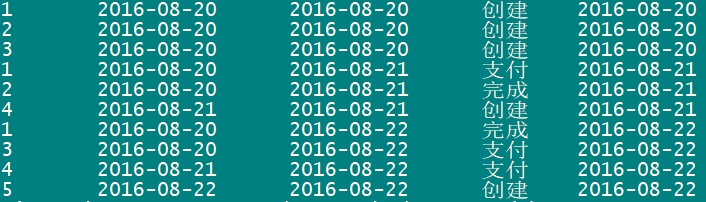
以一张订单表为例,如下是原始数据,每天的订单状态明细
1 2016-08-20 2016-08-20 创建 2 2016-08-20 2016-08-20 创建 3 2016-08-20 2016-08-20 创建 1 2016-08-20 2016-08-21 支付 2 2016-08-20 2016-08-21 完成 4 2016-08-21 2016-08-21 创建 1 2016-08-20 2016-08-22 完成 3 2016-08-20 2016-08-22 支付 4 2016-08-21 2016-08-22 支付 5 2016-08-22 2016-08-22 创建
根据拉链表我们希望得到的是:
1 2016-08-20 2016-08-20 创建 2016-08-20 2016-08-21 1 2016-08-20 2016-08-21 支付 2016-08-21 2016-08-22 1 2016-08-20 2016-08-22 完成 2016-08-22 9999-12-31 2 2016-08-20 2016-08-20 创建 2016-08-20 2016-08-21 2 2016-08-20 2016-08-21 完成 2016-08-21 9999-12-31 3 2016-08-20 2016-08-20 创建 2016-08-20 2016-08-22 3 2016-08-20 2016-08-22 支付 2016-08-22 9999-12-31 4 2016-08-21 2016-08-21 创建 2016-08-21 2016-08-22 4 2016-08-21 2016-08-22 支付 2016-08-22 9999-12-31 5 2016-08-22 2016-08-22 创建 2016-08-22 9999-12-31
最后两个字段:begin_date表示该条记录的生命周期开始时间,end_date表示该条记录的生命周期结束时间;
end_date = ‘9999-12-31’表示该条记录目前处于有效状态;
如果查询当前所有有效的记录,则select * from order_his where dw_end_date = ‘9999-12-31′;
如果查询2016-08-21的历史快照,则select * from order_his where begin_date <= ‘2016-08-21′ and end_date >= ‘2016-08-21’;
本例以hive为例,只考虑到实现,与性能和业务无关。
CREATE TABLE orders ( orderid INT, createtime STRING, modifiedtime STRING, status STRING ) row format delimited fields terminated by ' '; CREATE TABLE ods_orders ( orderid INT, createtime STRING, modifiedtime STRING, status STRING ) PARTITIONED BY (day STRING) row format delimited fields terminated by ' '; CREATE TABLE dw_orders_history ( orderid INT, createtime STRING, modifiedtime STRING, status STRING, dw_start_date STRING, dw_end_date STRING ) row format delimited fields terminated by ' ' ;
首先全量更新,我们先到2016-08-20为止的数据。
初始化,先把2016-08-20的数据初始化进去。
INSERT overwrite TABLE ods_orders PARTITION (day = '2016-08-20') SELECT orderid,createtime,modifiedtime,status FROM orders WHERE createtime < '2016-08-21' and modifiedtime <'2016-08-21';
![]()
刷到dw_orders_history中。
INSERT overwrite TABLE dw_orders_history SELECT orderid,createtime,modifiedtime,status, createtime AS dw_start_date, '9999-12-31' AS dw_end_date FROM ods_orders WHERE day = '2016-08-20';

2016-08-21的数据增量刷到ods_orders。注意,如果 hive 表是分区表的话,insert overwrite 操作只会重写当前分区的数据,不会重写其他分区数据。
INSERT overwrite TABLE ods_orders PARTITION (day = '2016-08-21') SELECT orderid,createtime,modifiedtime,status FROM orders WHERE (createtime = '2016-08-21' and modifiedtime = '2016-08-21') OR modifiedtime = '2016-08-21';

先放到增量表中,然后进行关联到一张临时表中,在插入到新表中
DROP TABLE IF EXISTS dw_orders_his_tmp; CREATE TABLE dw_orders_his_tmp AS SELECT orderid, createtime, modifiedtime, status, dw_start_date, dw_end_date FROM ( SELECT a.orderid, a.createtime, a.modifiedtime, a.status, a.dw_start_date, CASE WHEN b.orderid IS NOT NULL AND a.dw_end_date > '2016-08-21' THEN '2016-08-21' ELSE a.dw_end_date END AS dw_end_date FROM dw_orders_history a left outer join (SELECT * FROM ods_orders WHERE day = '2016-08-21') b ON (a.orderid = b.orderid) UNION ALL SELECT orderid, createtime, modifiedtime, status, modifiedtime AS dw_start_date, '9999-12-31' AS dw_end_date FROM ods_orders WHERE day = '2016-08-21' ) x ORDER BY orderid,dw_start_date; INSERT overwrite TABLE dw_orders_history SELECT * FROM dw_orders_his_tmp;

重复上面2步把2016-08-22号的数据更新进去,最后结果如下
ods_orders表数据:
拉链表dw_orders_history的数据:

全部sql


CREATE TABLE orders ( orderid INT, createtime STRING, modifiedtime STRING, status STRING ) row format delimited fields terminated by ' '; CREATE TABLE ods_orders ( orderid INT, createtime STRING, modifiedtime STRING, status STRING ) PARTITIONED BY (day STRING) row format delimited fields terminated by ' '; CREATE TABLE dw_orders_history ( orderid INT, createtime STRING, modifiedtime STRING, status STRING, dw_start_date STRING, dw_end_date STRING ) row format delimited fields terminated by ' ' ; INSERT overwrite TABLE ods_orders PARTITION (day = '2016-08-20') SELECT orderid,createtime,modifiedtime,status FROM orders WHERE createtime < '2016-08-21' and modifiedtime <'2016-08-21'; ##刷到dw中 INSERT overwrite TABLE dw_orders_history SELECT orderid,createtime,modifiedtime,status, createtime AS dw_start_date, '9999-12-31' AS dw_end_date FROM ods_orders WHERE day = '2016-08-20'; INSERT overwrite TABLE ods_orders PARTITION (day = '2016-08-21') SELECT orderid,createtime,modifiedtime,status FROM orders WHERE (createtime = '2016-08-21' and modifiedtime = '2016-08-21') OR modifiedtime = '2016-08-21'; ##先放到增量表中,然后进行关联到一张临时表中,在插入到新表中 DROP TABLE IF EXISTS dw_orders_his_tmp; CREATE TABLE dw_orders_his_tmp AS SELECT orderid, createtime, modifiedtime, status, dw_start_date, dw_end_date FROM ( SELECT a.orderid, a.createtime, a.modifiedtime, a.status, a.dw_start_date, CASE WHEN b.orderid IS NOT NULL AND a.dw_end_date > '2016-08-21' THEN '2016-08-21' ELSE a.dw_end_date END AS dw_end_date FROM dw_orders_history a left outer join (SELECT * FROM ods_orders WHERE day = '2016-08-21') b ON (a.orderid = b.orderid) UNION ALL SELECT orderid, createtime, modifiedtime, status, modifiedtime AS dw_start_date, '9999-12-31' AS dw_end_date FROM ods_orders WHERE day = '2016-08-21' ) x ORDER BY orderid,dw_start_date; INSERT overwrite TABLE dw_orders_history SELECT * FROM dw_orders_his_tmp; #8月22 增量更新 INSERT overwrite TABLE ods_orders PARTITION (day = '2016-08-22') SELECT orderid,createtime,modifiedtime,status FROM orders WHERE (createtime = '2016-08-22' and modifiedtime = '2016-08-22') OR modifiedtime = '2016-08-22'; DROP TABLE IF EXISTS dw_orders_his_tmp; CREATE TABLE dw_orders_his_tmp AS SELECT orderid, createtime, modifiedtime, status, dw_start_date, dw_end_date FROM ( SELECT a.orderid, a.createtime, a.modifiedtime, a.status, a.dw_start_date, CASE WHEN b.orderid IS NOT NULL AND a.dw_end_date > '2016-08-22' THEN '2016-08-22' ELSE a.dw_end_date END AS dw_end_date FROM dw_orders_history a left outer join (SELECT * FROM ods_orders WHERE day = '2016-08-22') b ON (a.orderid = b.orderid) UNION ALL SELECT orderid, createtime, modifiedtime, status, modifiedtime AS dw_start_date, '9999-12-31' AS dw_end_date FROM ods_orders WHERE day = '2016-08-22' ) x ORDER BY orderid,dw_start_date; INSERT overwrite TABLE dw_orders_history SELECT * FROM dw_orders_his_tmp;
参考博客:Hive拉链表原理