核心知识点:
1.键重命名:rename和renamenx,使用renamenx时newkey必须不存在,重命名后会使用del删除原来的键,如果值比较大也会会造成阻塞。
2.随机返回一个值:randomkey
3.键过期:
a.除了expire、ttl之外,expireat、pexpireat、pexpire,内部都是使用的pexpireat;
b.expire键不存在返回0,设置负的过期时间,会立即删除键;persist和set会清除过期时间。
4.键迁移:
a.move库与库之间迁移数据,不常用
b.tump+restore,dump将键序列化(格式化采用RDB格式),然后restore复原;非原子性、客户端分布完成
c.migrate,dump+restore+del的组合,原子性,数据直接传输,收到之后会返回ok,相对tump+restore提升了效率
5.遍历键:
a.keys,可能带来阻塞,在不提供服务或者键总数比较少的情况下,可以使用;keys提供模式匹配,*、?、[]、X;
b.scan,分批次遍历,不能保证能遍历完所有的键。
6.数据库管理:
a.select可以切换数据,有0-15这16个库;
b.多个数据库被“丢弃”的原因?单线程、库与库之间可能会相互影响、部分客户端不支持;
c.可以在一台机器上开启多个Redis实例
d.flushdb清空当前库,flishall清空所有库
e.使用flushdbflushall会清空数据非常危险,同时可能会造成阻塞
之前介绍了一系列的关于各种数据结构的一些命令,接下来会介绍一些键的管理操作。
下面会从单个键管理、遍历键和数据库管理这三个方面进行介绍。
一、单个键管理
1.键重命名
命令:rename key newkey
127.0.0.1:6379> set name kebi OK 127.0.0.1:6379> rename name name:kb OK 127.0.0.1:6379> get name:kb "kebi"
如果重新命令的这个键名在之前已经存在,那么它的值将会被覆盖:
127.0.0.1:6379> set a b OK 127.0.0.1:6379> set c d OK 127.0.0.1:6379> rename a c OK 127.0.0.1:6379> get c "b"
为了防止强行rename,Redis提供了renamenx命令,确保只有newkey不存在的时候才能被覆盖:
127.0.0.1:6379> set kebi dsb OK 127.0.0.1:6379> set maoxian lsb OK 127.0.0.1:6379> renamenx kebi maoxian (integer) 0 #没有执行成功返回0 127.0.0.1:6379> get maoxian "lsb" 127.0.0.1:6379> get kebi "dsb"
在使用重命名的时候有两点要注意:
(1)由于重命令期间会执行del删除旧的键,如果键对应的值比较大,会存在阻塞Redis的可能性。
(2)如果key和newkey相同,在Redis3.2和之前的版本中,返回的结果可能会不同。
2.随机返回一个键
命令:randomkey
127.0.0.1:6379> dbsize (integer) 33 #当前系统中有33个键 127.0.0.1:6379> randomkey "name:kb" #每次都会随机返回一个键 127.0.0.1:6379> randomkey "set:sunion:1_2" 127.0.0.1:6379> randomkey "user:1"
3.键过期
之前在介绍Redis所有数据结构通用的命令时介绍过expire,它可以自动将带有过期时间的键删除,
除了expire、ttl命令之外,Redis还提供了expireat、pexpire、pexpireat、pttl、persist等命令。
- expire key seconds:键在reconds秒后过期。
- expireat key timestamp:键在秒级时间戳timestamp后过期。
127.0.0.1:6379> set hello world OK 127.0.0.1:6379> expire hello 20 (integer) 1 #设置成功 127.0.0.1:6379> ttl hello (integer) 13 #还是3秒 127.0.0.1:6379> ttl hello (integer) 7 127.0.0.1:6379> ttl hello (integer) -2 #键已经被删除
ttl命令和pttl都可以查询键的剩余过期时间,但是pttl精度更高,可以达到毫秒级别,有3种返回值:
- 大于等于0的整数:键的剩余过期时间(ttl是秒,pttl是毫秒)。
- -1:键没有设置过期时间。
- -2:键不存在。
expireat命令可以设置键的秒级过期时间戳如果需要将键hello在2017-12-19 00:00:00(秒级时间戳为1513612800)过期,可以这样:
127.0.0.1:6379> set hello world OK 127.0.0.1:6379> expireat hello 1513612800 (integer) 1
除此之外,Redis2.6版本以后提供了毫秒级的过期方案:
- pexpire key millseconds:键在milliseconds毫秒后过期。
- pexpireat key milliseconds-timestamp:键在毫秒时间戳timestamp后过期。
但无论是使用过期时间还是时间戳,秒级还是毫秒级,在Redis内部最终使用的都是pexpireat。
在使用Redis相关过期命令时,需要注意以下几点。
(1)如果expire的键不存在,返回的结果是0:
127.0.0.1:6379> expire not_exist_key 10 (integer) 0
(2)如果过期时间为负值,键会立即被删除,犹如使用del命令一样:
127.0.0.1:6379> set age 18 OK 127.0.0.1:6379> expire age -10 (integer) 1 127.0.0.1:6379> get age (nil)
(3)persist命令可以将键的过期时间清除:
127.0.0.1:6379> set sex boy OK 127.0.0.1:6379> expire sex 1000 (integer) 1 127.0.0.1:6379> ttl sex (integer) 996 127.0.0.1:6379> persist sex (integer) 1 127.0.0.1:6379> ttl sex (integer) -1 #代表没有设置过期时间
(4)对于字符串类型键,执行set命令会去掉过期时间,这个问题很容易在开发中被忽视。
如下是Redis源码中,set命令的函数setKey,可以看到最后执行了removeExpire(db,key)函数去掉了过期时间:
void setKey(redisDb *db,robj *key,robj * val) ( if (lookupKeyWrite(db,key) == NULL) { dbAdd(db,key,val); } else { dbOverwrite(db,key,val); } incrRefCount(val); //去掉过期时间 removeExpire(db,key); signalModifiedKey(db,key); }
下面的例子证明set会导致过期时间失效:
127.0.0.1:6379> set hello world OK 127.0.0.1:6379> expire hello 50 (integer) 1 127.0.0.1:6379> ttl hello (integer) 34 127.0.0.1:6379> set hello world OK 127.0.0.1:6379> ttl hello (integer) -1 #代表没有设置过期时间
(5)Redis不支持二级数据结构(例如哈希、列表)内部元素的过期功能,例如不能对列表类型的一个元素设置过期时间。
(6)setex命令作为set+expire的组合,不但是原子执行,同时减少了一次网络通讯的时间。
4.迁移键
迁移的功能非常重要,因为有时候我们只想把部分数据由一个Redis迁移到另一个Redis(例如从生产环境迁移到测试环境),
Redis发展历程中提供了move、dump+restore、migrate三组迁移键的方法,它们的实现方式及使用场景不大相同,下面分别介绍:
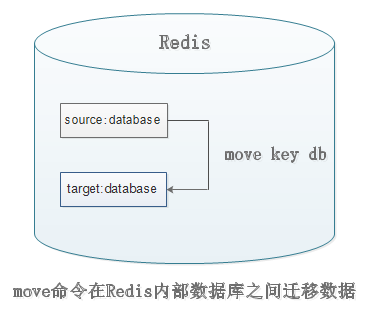
(1)move
命令:move key db
move命令用于在Redis内部进行数据迁移,Redis内部可以有多个数据库,每个数据库在数据上是相互隔离的,
move key db就是把指定的键从源数据库迁移到目标数据库中。不建议在生产环境中使用。
(2)dump+restore
命令:
dump restore
restore key ttl value
dump + restore可以实现在不同的Redis实例之间进行数据迁移功能,整个迁移过程分两步:
第一步,在源Redis上,dump命令会将键值序列化,格式化采用的是RDB格式。
第二步,在目标Redis上,restore命令将上面序列化的值进行复原,其中ttl参数代表过期时间,如果ttl=0代表没有过期时间。
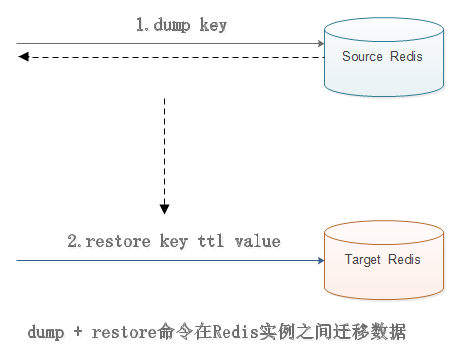
有关dump+restore有两点需要注意:
第一,整个迁移过程并非原子性的,而是通过客户端分步完成的。
第二,迁移过程是开启两个客户端连接,所以dump的结果不是在源Redis和目标Redis之间进行传输。
(3)migrate
命令:migrate host port key|“”destination-db timeout [copy] [replace] [keys key [key ...]]
参数说明:
- host:目标Redis的IP地址
- port:目标Redis的端口
- key|“”:在Redis3.0.6版本之前,migrate只支持迁移一个键,之后的版本支持迁移多个键,如果需要迁移多个键,此处为“”
- destination-db:目标Redis的数据库索引
- timeout:迁移的超时时间(单位为毫秒)
- [copy]:如果添加此选项,迁移后并不删除源键
- [replace]:如果添加此选项,migrate不管目标Redis是否存在该键都会正常迁移进行数据覆盖
- [keys key [key ...]]:迁移多个键。
migrate命令也是用于在Redis实例间进行数据迁移的,实际上migrate命令就是将dump、restore、del三个命令进行组合,从而简化了操作流程。
migrate命令具有原子性,而且从Redis3.0.6版本以后已经支持迁移多个键功能,有效地提高了迁移效率。
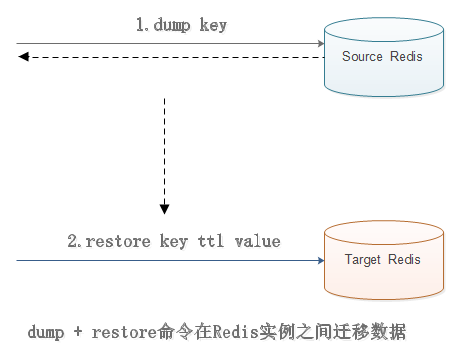
实现过程和dump+restore基本类似,但是有三点不大相同:
第一,整个过程是原子执行,不需要在多个Redis实例上开启客户端的,只需要在源Redis上执行migreate命令即可。
第二,migrate命令数据传输直接在源Redis和目标Redis上完成的。
第三,目标Redis完成restore后会发送OK给源Redis,源Redis接收后会根据migrate对应的选项来决定是否在源Redis上删除对应的键。
| 命令 | 作用域 | 原子性 | 支持多个键 |
| move | Redis实例内部 | 是 | 否 |
| dump+restore | Redis实例之间 | 否 | 否 |
| migrate | Redis实例之间 | 是 | 是 |
二、遍历键
1.全量遍历键
命令:keys pattern
之前介过绍过keys *这个命令,实际上keys命令是是支持pattern(模式)匹配的。之前我们是这样用的:
127.0.0.1:6379> keys * 1) "key" 2) "user:ranking:1" 3) "list:2" 4) "setkey3" 5) "kebi" 6) "maoxian" 7) "listkey" 8) "str:2" 9) "sex" 10) "set:sunion:2_1" 11) "hello" 12) "user:2" 13) "user:1" 14) "list:1" 15) "user:ranking:2" 16) "name:kb" 17) "setkey2" 18) "user1:1" 19) "str:1" 20) "str" 21) "list:test1"
上面为了遍历所有的键,pattern直接使用星号,这是因为pattern使用的是glob风格的通配符:
- *代表匹配任意个字符。
- ?代表匹配一个字符。
- [ ]代表匹配部分字符,例如[1,3]匹配1和3,[1-4]匹配1-4之间的任意数字。
- x用来做转义,例如要匹配星号、问号需要进行转义。
例如,要匹配三个字符的键:
127.0.0.1:6379> keys ??? 1) "key" 2) "sex" 3) "str"
要匹配以u和l开头的键:
127.0.0.1:6379> keys [u,l]* 1) "user:ranking:1" 2) "list:2" 3) "listkey" 4) "user:2" 5) "user:1" 6) "list:1" 7) "user:ranking:2" 8) "user1:1" 9) "list:test1"
当需要遍历所有键时(例如检测过期或者闲置时间、寻找大对象等),keys是一个很有帮助的命令。
但是如果考虑到Redis的单线程架构就不妙了,如果Redis包含了大量的键,执行keys命令很可能会带来Redis阻塞,
所以一般不嫁你在生产环境下使用keys命令,但是有时候确实有遍历键的需求该怎么办,可以在以下三种情况下使用:
- 在一个不对外提供服务的Redis从节点上执行,这样不会阻碍到客户端的请求,但是会影响到主从复制。
- 如果确认键值总数比较少,可以执行该命令。
- 使用下面要介绍的scan命令渐进式的遍历所有键,可以有效防止阻塞。
2.渐进式遍历
Redis从2.8版本后,提供了一个新的命令scan,它能有效的解决keys命令存在的问题。
和keys命令执行时会遍历所有键不同,scan采用渐进式遍历的方式来解决keys的命令可能带来的阻塞问题,每次scan命令的时间复杂度是O(1)。
但是要真正实现keys的功能,需要执行多次scan。Redis存储键值对实际使用的是hashtable的数据结构,其基本模型如下:
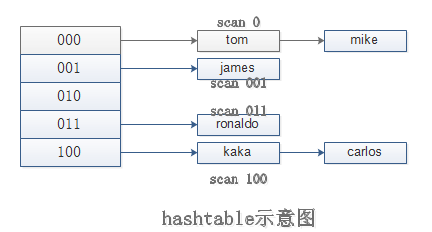
那么每次执行scan,可以想象成只扫描一个字典中的一部分,直到将字典中所有键遍历完毕。
scan的使用方法如下:
scan cursor [match pattern] [count number]
参数解释:
- cursor是必须参数,实际上cousor是一个游标,第一次遍历从0开始,每次scan遍历完都会返回当前游标的值,直到游标值为0,表示遍历结束。
- match pattern是可选参数,它的作用是做模式的匹配,这点和keys的模式匹配很像。
- count number是可选参数,它的作用是表明每次要遍历的键的个数,默认值为10。
现在内存中有16个键:
127.0.0.1:6379> keys * 1) "key" 2) "list:2" 3) "setkey3" 4) "kebi" 5) "maoxian" 6) "listkey" 7) "str:2" 8) "sex" 9) "set:sunion:2_1" 10) "hello" 11) "list:1" 12) "name:kb" 13) "setkey2" 14) "str:1" 15) "str" 16) "list:test1"
使用scan做遍历,记住必须从0开始:
127.0.0.1:6379> scan 0 1) "49" 2) 1) "sex" 2) "key" 3) "hello" 4) "list:1" 5) "kebi" 6) "str:1" 7) "list:2" 8) "listkey" 9) "str" 10) "maoxian"
默认返回10个键,第一行表示需要开始的cursor的位置,接着访问:
127.0.0.1:6379> scan 49 1) "0" 2) 1) "setkey3" 2) "name:kb" 3) "str:2" 4) "setkey2" 5) "set:sunion:2_1" 6) "list:test1"
返回0,代表已经遍历完成。
除了scan之外,Redis提供了面向哈希类型、集合类型、有序集合的扫描遍历命令,
解决诸如hgetall、smembers、zrange可能产生的阻塞问题,对应的命令分别是hscan、sscan、zscan,它们的用法和scan基本类似。
但是scan并不是万能的,如果在scan的过程中如果有键的变化(增加、删除、修改),
那么遍历效果可能会碰到如下问题:新增的键可能没有遍历到,遍历出了重复的键的情况,也就是说scan并不能保证完整的遍历出所有的键。
三、数据库管理
Redis提供了几个面向Redis数据库的操作,它们分别是dbsize、select、flushdb/flushall命令。
1.切换数据库
命令:select dbIndex
许多关系型数据库,例如MySQL支持在一个实例下有多个数据库存在的,但是与关系型数据库用字符来区分不同的数据库名不同,
Redis只是用数字作为多个数据库的实现,Redis默认配置中是有16个数据库,
select 0操作将切换到第一个数据库,默认也是进入第一个数据库,select 15操作切换到最后一个数据库,
但是0号数据库和15号数据库之间的数据没有任何关联,甚至可以存在相同的键:
127.0.0.1:6379> get hello "world" #默认0号库 127.0.0.1:6379> select 15 #切换到15号库 OK 127.0.0.1:6379[15]> get hello #不存在hello键 (nil) 127.0.0.1:6379[15]> set hello WORLD OK 127.0.0.1:6379[15]> get hello #不同库之间可以存在相同的键 "WORLD"
关于库之间的切换可以看下图:
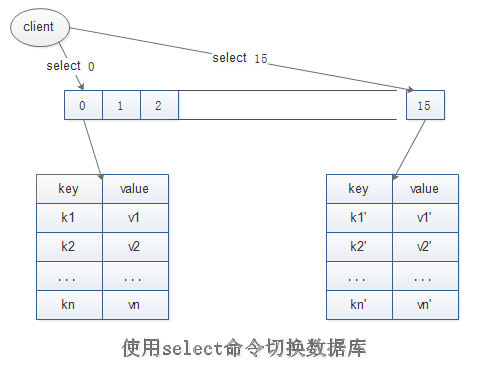
是否可以使用测试数据库和正式数据一样,把正式数据放在0号数据库,测试数据放在1号数据库了?彼此之间会有影响吗?
Redis3.0中已经逐渐弱化了这个功能,例如Redis的分布式实现Redis Cluster只允许使用0号数据库,只不过为了兼容老版本,该功能还没有完全废除。
下面分析以下为什么要废弃Redis的这项功能:
(1)Redis是单线程。如果使用多个数据库,那个这些数据库仍然是使用一个CPU,彼此之间还是会收到影响。
(2)对数据库的使用方式,会让调试和运维不同业务的数据库变得困难。如果一个数据库有慢查询存在,就会影响其他的数据库。
(3)部分Redis客户端根本不支持这种方式
如果要使用多个数据库功能,完全可以在一台机器上部署多个Redis实例,彼此使用端口来做区分,
因为一般的服务器都有多个CPU,这样多个数据库之间就不会收到影响,还能充分利用资源。
2.flushdb/flushall
flushdb/flushall命令用于清除数据库,两者的区别在于,flishdb只会清除当前数据库,而flushall会清除所有数据库。
现有三个库:
127.0.0.1:6379[2]> select 0 OK 127.0.0.1:6379> dbsize #0号库有16个键 (integer) 16 127.0.0.1:6379> select 2 OK 127.0.0.1:6379[2]> dbsize #2号库有3个键 (integer) 3 127.0.0.1:6379[2]> select 15 OK 127.0.0.1:6379[15]> dbsize #15号库有1个键 (integer) 1
在2号库上使用flushdb命令:
127.0.0.1:6379[15]> select 2 OK 127.0.0.1:6379[2]> flushdb OK 127.0.0.1:6379[2]> dbsize (integer) 0 #2号库已经清空 127.0.0.1:6379[2]> select 0 OK 127.0.0.1:6379> dbsize (integer) 16 #0号库依然存在
在0号库上执行flushall命令:
127.0.0.1:6379> select 0 OK 127.0.0.1:6379> flushall OK 127.0.0.1:6379> dbsize #0号库空 (integer) 0 127.0.0.1:6379> select 15 OK 127.0.0.1:6379[15]> dbsize #15号空 (integer) 0 127.0.0.1:6379[15]> select 2 OK 127.0.0.1:6379[2]> dbsize #2号空 (integer) 0
flushdb/flishall虽然可以很方便的清理数据,但是也会有两个问题:
(1)如果当前库键值数量非常多,很有可能会造成Redis阻塞;
(2)flushdb/flushall会将所有数据全部清除,这是非常危险的,后面会讲如何规避和如何恢复数据。