先来欣赏一段有趣的漫画对话哦


————— 第二天 —————





——————————————————






什么事进程和线程
有一定基础的小伙伴们肯定都知道进程和线程。
进程是什么呢?
直白地讲,进程就是应用程序的启动实例。比如我们运行一个游戏,打开一个软件,就是开启了一个进程。
进程拥有代码和打开的文件资源、数据资源、独立的内存空间。
线程又是什么呢?
线程从属于进程,是程序的实际执行者。一个进程至少包含一个主线程,也可以有更多的子线程。
线程拥有自己的栈空间。

有了进程为什么还需要线程
因为进程不能同一时间只能做一个事情
什么是线程
线程是操作系统调度的最小单位
线程是进程正真的执行者,是一些指令的集合(进程资源的拥有者)
同一个进程下的读多个线程共享内存空间,数据直接访问(数据共享)
为了保证数据安全,必须使用线程锁
GIL全局解释器锁
在python全局解释器下,保证同一时间只有一个线程运行
防止多个线程都修改数据
线程锁(互斥锁)
GIL锁只能保证同一时间只能有一个线程对某个资源操作,但当上一个线程还未执行完毕时可能就会释放GIL,其他线程就可以操作了
线程锁本质把线程中的数据加了一把互斥锁
mysql中共享锁 & 互斥锁
mysql共享锁:共享锁,所有线程都能读,而不能写
mysql排它锁:排它,任何线程读取这个这个数据的权利都没有
加上线程锁之后所有其他线程,读都不能读这个数据
有了GIL全局解释器锁为什么还需要线程锁
因为cpu是分时使用的
死锁定义
两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去


进程和线程的痛点
线程之间是如何进行协作的呢?
最经典的例子就是生产者/消费者模式:
若干个生产者线程向队列中写入数据,若干个消费者线程从队列中消费数据。
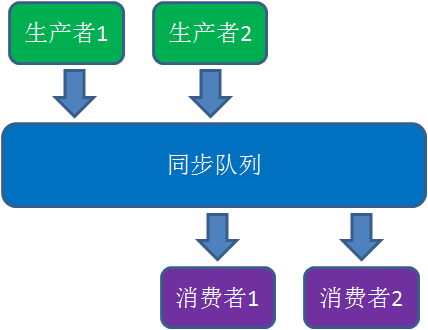
应用程序像工厂,进程像车间,线程像工人
一个进程中的线程可以在不同cpu上执行,一个线程不能同时在两个cpu上执行
python中有一个全局解释器锁(GIL global interpreter lock),他就像一把锁所在进程上,保证同一时刻,一个进程中无论有多少线程,只能保证有一个线程出来
随着cpu核数的增加,python中可以创建多个进程,一个进程中有一个全局解释器,这样一个cpu跑一个进程,一个进程同一时刻只能出一个线程,达到并行的目的
线程和进程的区别 :
线程是可以共享内存的,而进程不可以共享内存,一个进程就像一个应用程序,例如qq和淘宝,这属于两个进程,在QQ中发信息肯定不会发到淘宝中,但是在qq中存在很多的线程,他们可以共享内存,他们都属于一个进程,
假如eclipse在运行时占中400M的内存空间,那么这个进程下的线程的共享空间为这个主进程所占用的内存空间,就是eclipse的线程的内存共享就为400M
线程没有办法单独执行,线程必须在进程中
多进程之间的通信:
多进程之间无法直接通信,它必须借助一个第三方的桥梁
1 队列 from multiprocessing import Process, Queue def f(q,n): q.put([ n, 'hello']) if __name__ == '__main__': q = Queue() for i in range(5): p = Process(target=f, args=(q,i)) p.start() print q.get()
线程的安全问题,假如现在有十个线程,同时修改一个变量,让这个变量+1,那么会出现一个问题,假如A线程正在修改变量,现在变量为m=2,A线程操作m,目的是让A+1,然而A修改到一半的时候,线程B又进来了,线程B此时取的m的值也是2,A修改完了m=3,B修改完了m还是等于3 ,非常不安全
解决办法,就是加一把锁,形象的例子:
假如现在有10个人要上厕所,钥匙在我手里,这个时候A进来,他把门关上了,别人就进不去,只有等A完事后其他人才能进来,这个门就是控制线程的那把锁
代码实现就通过一个lock来实现,lock 只允许一个线程访问
lock=threading.Lock()
lock.acquire()
lock.release()
代码如下
val=0 #全局变量 def run(self,): #lock.acquire() time.sleep(1) global val lock.acquire() val+=1 print '%s' %val lock.release() //这个地方执行完了必须relese,让后面的线程继续执行,否则后面无法执行 lock=threading.Lock() for i in range(100): t=threading.Thread(target=run,args=(i,)) t.start()
假如一个厕所门里有两个坑,允许两个人同时上厕所,即允许两个线程同时修改变量,那么用samp
samp = threading.BoundedSemaphore(3)
samp.acquire()
samp.release()
当参数为1时,实际上就等于lock
val=0 #全局变量 def run(self,): #lock.acquire() time.sleep(1) global val samp.acquire() val+=1 print '%s' %val samp.release() lock=threading.Lock() samp = threading.BoundedSemaphore(3) for i in range(100): t=threading.Thread(target=run,args=(i,)) t.start()
全局变量和局部变量
全局变量是在方法之外定义的变量,方法内部不能修改全局变量
例如 val=0 #全局变量
def run(self,n)
val+=1
程序会报错,方法内不能直接就该全局变量
在假如 val=0 #全局变量
def run(self,n)
val=1
print val
输出结果会是1,这是为什么呢,应为此时函数内部的val与全局变量val并不是一个,函数内部的 val是局部变量,函数外部的val为全局变量
假如 执行c=run(‘haha’)
print val
会输出 0
1
假如要在函数内重新定义局部变量
必须在函数中重新声明全局变量
val=0 #全局变量 def run(self,n) global val val=1 print val
join() 执行到join时,例如执行到join(3)然后就在这个地方等待三秒,
from threading import Thread import time class MyThread(Thread): def run(self): time .sleep(5) print '我是线程' def bar(): print 'bar' t1=MyThread(target=bar ) t1.start() t1.join(3) print ‘over'
采用面向类的生产者消费者模型
#_*_ coding:utf-8 _*_ from threading import Thread from Queue import Queue import time class Producer(Thread): def __init__(self,name,queue): self.__name=name self.__queue=queue super(Producer,self).__init__() #重写了父类的方法 def run(self): while True: if self.__queue.full(): time.sleep(1) else : self.__queue.put('baozi') time.sleep(1) print '%s生产了一个包子'%(self.__name)
class consumer(Thread): def __init__(self,name,queue): self.__name=name self.__queue=queue super(consumer,self).__init__() def run(self): while True: if self.__queue.empty(): time.sleep(1) else : self.__queue.get() time.sleep(1) print '%s 消费一个包子'%(self.__name,) que =Queue(maxsize=100) baozi_make1=Producer('mahzongyi',que) baozi_make1.start() baozi_make2=Producer('mahzongyi1',que) baozi_make2.start() baozi_make3=Producer('mahzongyi2',que) baozi_make3.start() for item in range(20): name = 'lazup%d'%(item) temp=consumer(name,que) temp.start()
上面的代码正确地实现了生产者/消费者模式,但是却并不是一个高性能的实现。为什么性能不高呢?原因如下:
1.涉及到同步锁。
2.涉及到线程阻塞状态和可运行状态之间的切换。
3.涉及到线程上下文的切换。
以上涉及到的任何一点,都是非常耗费性能的操作。


什么事协程
协程,英文Coroutines,是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
协程微线程,纤程,本质是一个单线程
协程能在单线程处理高并发
线程遇到I/O操作会等待、阻塞,协程遇到I/O会自动切换(剩下的只有CPU操作)
线程的状态保存在CPU的寄存器和栈里而协程拥有自己的空间,所以无需上下文切换的开销,所以快、
为甚么协程能够遇到I/O自动切换
协程有一个gevent模块(封装了greenlet模块),遇到I/O自动切换
协程缺点
无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上
线程阻塞(Blocking)操作(如IO时)会阻塞掉整个程序

最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。
这样带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源。
既然协程这么好,它到底是怎么来使用的呢?
我们来看一看python当中对协程的实现案例,同样以生产者消费者模式为例:

这段代码十分简单,即使没用过python的小伙伴应该也能基本看懂。
代码中创建了一个叫做consumer的协程,并且在主线程中生产数据,协程中消费数据。
其中 yield 是python当中的语法。当协程执行到yield关键字时,会暂停在那一行,等到主线程调用send方法发送了数据,协程才会接到数据继续执行。
但是,yield让协程暂停,和线程的阻塞是有本质区别的。协程的暂停完全由程序控制,线程的阻塞状态是由操作系统内核来进行切换。
因此,协程的开销远远小于线程的开销。


协程的应用
有哪些编程语言应用到了协程呢?我们举几个栗子:
Lua语言
Lua从5.0版本开始使用协程,通过扩展库coroutine来实现。
Python语言
正如刚才所写的代码示例,python可以通过 yield/send 的方式实现协程。在python 3.5以后,async/await 成为了更好的替代方案。
Go语言
Go语言对协程的实现非常强大而简洁,可以轻松创建成百上千个协程并发执行。
Java语言
如上文所说,Java语言并没有对协程的原生支持,但是某些开源框架模拟出了协程的功能,有兴趣的小伙伴可以看一看Kilim框架的源码:
https://github.com/kilim/kilim

详细介绍请阅读我的分类Python基础下的《Python三程三器的那些事》