背景
在读了《深入理解Java虚拟机》之后,在网上搜了关于java内存相关的很多资料以便于理解书中的知识点,但是在搜索查资料的过程中,发现了很多的人会把java内存区域,也就是运行时数据区和Java内存模型,也就是JMM弄到一起去。Java内存模型是定义了程序各个线程和主内存之间的一种抽象的关系,比如像下图,这个是《深入理解java虚拟机》一书中的图。
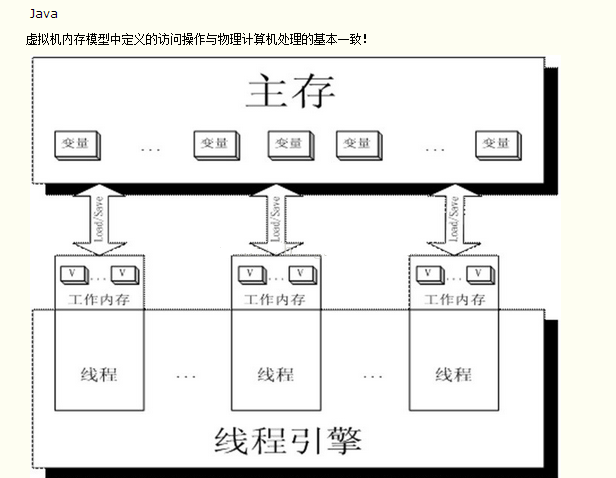
在Java程序中,当在JVM在创建一个线程的时候,JVM会主动的为这个线程创建一个工作空间,每个线程的工作空间又都是独立开来的。因为共享数据是放在主内存的,所以主内存对于各个线程来说却是共享的。那么这样的话,问题就来了,一旦在某些情况下,有多个线程同时对主内存中的同一个资源进行操作,那么就有可能导致资源的状态不一致。当一个线程在和主内存交互的时候,首先是要把数据拷贝到自己的工作内存中来处理的,所以线程处理的数据,其实是一个副本,当线程处理完之后,线程再把这个副本刷新到主内存中,其实这个过程一种伴随着8个步骤:
第一步,read:从主内存读取数据。
第二步,load:将第一步读取到的数据写入到工作内存中。
第三部,use,从工作内存中读取数据来使用。
第四步,assing,把第三步中计算好的数据,从赋值到工作内存中。
第五步,store,把第四步中的数据写入到主内存。
第六步,把第五步写入的数据赋值给主内存中的变量。
另外还有两个,lock:就是给变量加锁,标识这个变量线程独占。
unlock:解锁,解锁后的变量其他的线程可以使用。
通过上述的步骤,所以我们在一个线程修改完数据,另外一个线程无法立即可见,这就是导致了JMM内存不一致的问题,解决思路有两个:
第一种:加锁。就是避免对变量产生竞争。
第二种:MESI缓存一致性协议:也就是我们常见到的volatile关键字来修改变量,使用了volatile关键字的变量,具备两层含义:一个就是保证了不同线程对这个变量的操作的可见性,也就是说当线程T1修改了某个变量的值,那么新值对于另一个线程T2来客是可以立即可见的。因为使用volatile关键字会强制将修改的值立即写入主存,并且使用volatile关键字的话,当线程T进行修改时,会导致线程T2的工作内存中缓存变量的缓存行无效,由于线程T2的工作内存中缓存变量的缓存行无效,所以线程T2再次读取变量的值时会去主存读取。二个就是进行指令重排序。
volatile内部实现
我们在《深入理解java虚拟机》书中有提到“观察加入volatile关键字和没有加入volatile关键字时所生成的汇编代码发现,加入volatile关键字时,会多出一个lock前缀指令”,lock前缀指令实际上是一个内存屏障,对于内存屏障,他提供了三个功能
1:它可以确保指令中排序的时候,不会把它后面的指令放到内存屏障之前的位置。也不会把他前面的指令排到内存屏障后面的位置。
2:强制将对缓存的修改操作立即写入主存。
3:如果是写操作,它会导致其他CPU中对应的缓存行无效。
Java内存区域
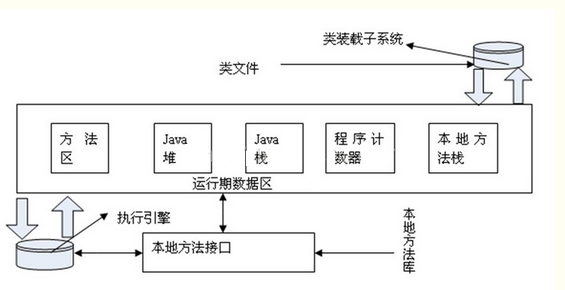
1、程序计数器:
CPU的计算时间是以分片的方式给到每个线程的,换句话说,所谓的并行其本质就是串行。比如线程A执行到了一部分,CPU将控制权给了线程B,那么线程A重新得到CPU的资源时,如何恢复工作呢?这个程序计数器就来帮助线程A找到其中间状态,从而恢复到正确的执行位置。程序计数器所占内存是线程 私有的,同时也是 Java 虚拟机规范中没有规定任何 OutOfMemoryError 情况的区域。
2、JAVA虚拟机栈:
它也是线程 私有的,它所占有的内存空间也就是我们平时所说的“ 栈(stack)内存”。并且和线程的生命周期相同。 虚拟机栈描述的是 Java 方法执行的内存模型:每个方法被执 行的时候都会 同时创建一个栈帧( Stack Frame ①)用于存储局部变量表(基本数据类型,对象的引用和returnAddress类型)、操作栈、动态 链接、方法出口等信息。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在 虚拟机栈中从入栈到出栈的过程。在java虚拟机规范中,对这个区域规定了两种异常状况:a.如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError 异常。b.如果虚拟机栈可以动态扩展(当前大部分的Java 虚拟机都可动态扩展,只不过Java 虚拟机规范中也允许固定长度的虚拟机栈),当扩展时无法申请到足够的内存时会抛出OutOfMemoryError 异常。
3、JAVA堆:
JAVA堆一般是JVM管理的内存中最大的一块,JAVA堆在主内存中,是被所有线程 共享的一块内存区域,其随着JVM的创建而创建,堆内存的唯一目的是存放对象实例。同时JAVA堆也是GC管理的主要区域。如果从内存回收的角度看,由于现在收集器基本都是采用的分代收集算法,所以Java 堆中还可以细分为:新生代和老年代;再细致一点的有Eden 空间、From Survivor 空间、To Survivor 空间等。如果从内存分配的角度看,线程共享的Java 堆中可能划分出多个线程私有的分配缓冲区(Thread Local Allocation Buffer,TLAB)。不过,无论如何划分,都与存放内容无关,无论哪个区域,存储的都仍然是对象实例,进一步划分的目的是为了更好地回收内存,或者更快地分配内存。如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError 异常。、
4、本地方法栈:
本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别不过是虚拟机栈为虚拟机执行Java 方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的Native 方法服务。虚拟机规范中对本地方法栈中的方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它。甚至有的虚拟机(譬如Sun HotSpot 虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError 和OutOfMemoryError异常。
5、方法区:
方法区也是各线程共享的一个内存区域。主要 用于存 储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
6、常量池:
文件中除了有类的版本、字段、方法、接口等描述等信息外,还有一项信息是常量表(constant_pool table),用于存放编译期已可知的常量,这部分内容将在类加载后进入方法区(永久代)存放(JDK1.7开始,常量池已经被移到了堆内存中)。但是Java语言并不要求常量一定只有编译期预置入Class的常量表的内容才能进入方法区常量池,运行期间也可将新内容放入常量池(最典型的String.intern()方法)。