Recurrent Neural Network, 适用于序列建模。举一个粒子:

很容易就知道短线上应该填 John。 如何建立一个模型来让机器学习这件事情呢? 如果用全连接网络, 那么输入就是短线前面的所有单词(首先将每一个单词向量化, 然后将所有单词concatenate在一起,形成一个向量, 作为网络的输入。 这样做的问题是参数量过大。 如果用卷积网络来做, 将所有的词向量拼接成一个矩阵, 作为网络的输入,这样做效果也不错, 但是相比于RNN, CNN在发现序列之间的关系可能要难一点。 现在就来揭开RNN神秘的面纱。
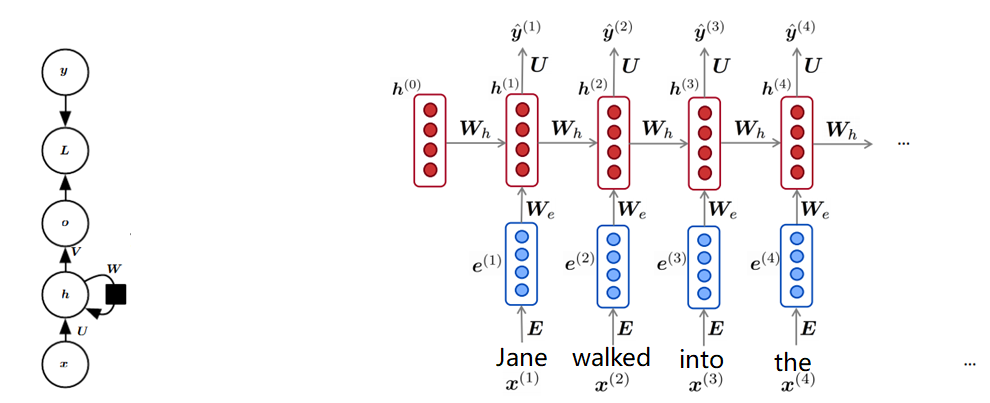
左边是RNN环图, 右边是RNN的展开图。RNN的计算公式如下:

可以看到RNN是个串行的结构, t时刻的计算依赖于t-1时刻的计算。需要注意的是, 不同的时刻之间共享所有权值, 包括Wh, We, U, b1, b2. 你要问我为什么不同的时刻之间共享权值 ?
理由一:如果不共享权值, RNN的参数量会很大。序列长度越长, 参数量越多。共享权值起到了正则化的作用。
理由二:共享权值可以看成是一种先验知识。科学家认为, 在处理每一个时刻的输入时, 用相同的权值就可以了。
理由三:共享权值使得RNN可以灵活的处理任意长度的输入序列。以不变应万变。
RNN的损失函数:
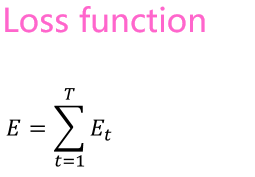
为什么RNN存在梯度消失的问题 ?首先来推导RNN的反向传播公式。



没有看懂? 没关系, 多看几遍, 在纸上推导几遍就懂了, 这个地方不难, 只要具备大学本科线性代数知识即可。
下面是一个简单一点的例子, 说明RNN的梯度问题。
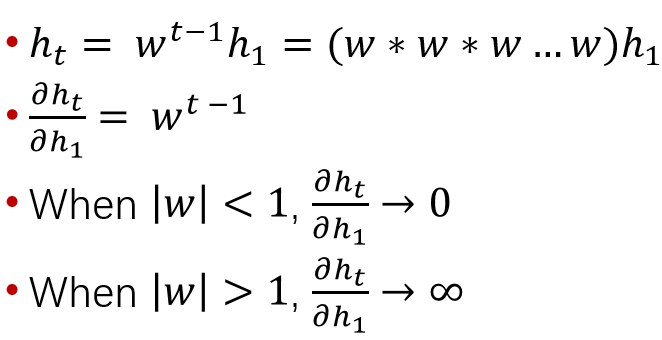
注意, 以上全是标量。因为RNN共享权值, 会出现w的高次幂。
梯度消失会引起什么问题?
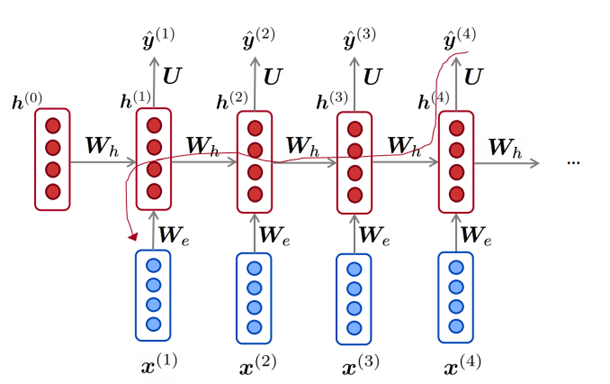
如图中画出的带箭头的红线所示, x(4)与x(1)之间的依赖关系通过
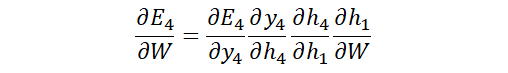
来调整。很明显, 间隔的比较远的时候, 他们之间的依赖关系就比较难以调整。
