#正则对象的match匹配
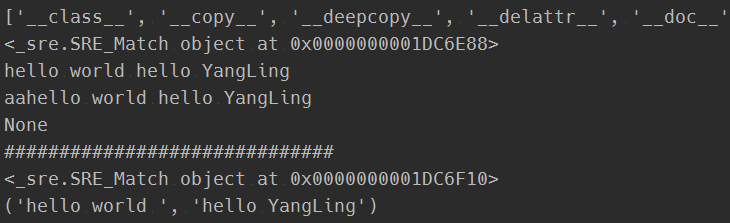
1 #正则对象的match匹配 2 import re 3 reg = re.compile(r'(hello w.*)(hello Y.*)') 4 print(dir(reg)) 5 a = 'hello world hello YangLing' 6 result = reg.match(a) 7 print(result) 8 print(result.group()) 9 10 b = 'aa' + a 11 print(b) 12 result2 = reg.match(b) 13 print(result2) 14 15 16 #正则对象的search方法做一个比较 17 m = 'kdsjfigheigjewijsgiegekdsjgeighse' 18 print('#'*30) 19 result3 = reg.search(b) 20 print(result3) 21 print(result3.groups())
打印结果为:
['__class__', '__copy__', '__deepcopy__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'findall', 'finditer', 'flags', 'groupindex', 'groups', 'match', 'pattern', 'scanner', 'search', 'split', 'sub', 'subn']
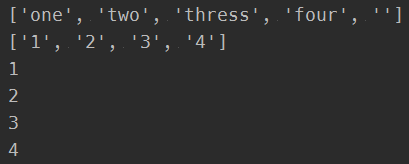
1 import re 2 3 p1 = re.compile(r'd+') 4 a_str = 'one1two2thress3four4' 5 6 #正则对象的split方法,使用正则匹配进行分割字符串 7 #最后以列表的形式返回回去 8 print(p1.split(a_str)) 9 10 #正则对象那个的findall方法,来查找符合对象的字符串 11 #最后是以列表的形式返回回去 12 print(p1.findall(a_str)) 13 14 for i in p1.finditer(a_str): 15 print(i.group())
打印结果为:
1 import re 2 prog = re.compile(r'(?P<tagname>abc)(w*)(?P=tagname)') 3 result = prog.match('abclfjlad234sjldabc') 4 5 #finditer 迭代以后每个对象都是一个matche对象 6 7 print(dir(result)) 8 print(result) 9 10 print(result.groups()) 11 print(result.group(2)) 12 print(result.group(1)) 13 print('#'*30) 14 print(result.group('tagname')) 15 #matche对象的group返回一个元组,下标是以1开头。 16 17 print(result.groupdict())
打印结果为:
['__class__', '__copy__', '__deepcopy__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'end', 'endpos', 'expand', 'group', 'groupdict', 'groups', 'lastgroup', 'lastindex', 'pos', 're', 'regs', 'span', 'start', 'string']
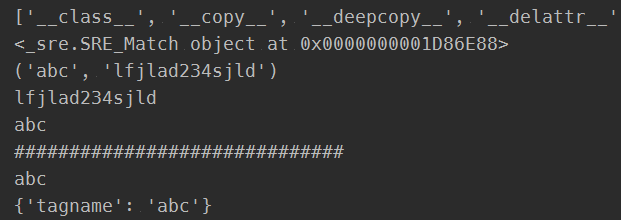
解释:
1,我们可以看到result1已经由字符串转换成了一个正则对象。
2,resule.groups()可以查看出来所有匹配到的数据,每个()是一个元素,最终返回一个tuple
3,group()既可以通过下标(从1开始)的方式访问,也可以通过分组名进行访问。
4,groupdict只能显示有分组名的数据