本文官方链接,https://www.cnblogs.com/yanghailin/p/14034984.html,未经允许,勿转载。
Centernet github地址:
https://github.com/xingyizhou/CenterNet
加qq群一起学习讨论交流:1020395892
centernet训练自己的数据集
https://www.cnblogs.com/yanghailin/p/13977665.html
1.论文简介
1.1 前言
目标检测器用水平框来确定一个图像中的目标。最好的目标检测器几乎列举了每个目标的全部的潜在的位置和分类结果。这种做法是奢侈的,低效的而且需要额外的后处理。本文中我们提出了一种不同的方法。我们建模一个对象为一个单个的点——即目标框的中心点。我们的检测器使用关键点估计来找到中心点并且回归出全部其他的目标属性,比如大小,3D位置,方向甚至姿势。
一阶段检测器把名为anchors的复杂排布的可能的框在图像上滑动,并且对小图直接进行分类而不修正框的内容。二阶段检测器对每个潜在的框重新计算了图像特征,然后对这些新特征进行分类,(也就是repooling操作,如:roi pooling以及roi align)。后处理也就是非极大值抑制,然后通过计算框的IOU去除同一对象的多余检测结果。这个后处理结果很难去微分和训练,因此当前大多数的检测器都不是端到端可训练的。
1.2 centernet方法概况
本文中,我们提供了一个更简单并且更高效的可替代的目标检测方法。我们通过一个对象框中心的单个点来表示目标(图2所示)。其他的属性,比如目标尺寸,维度,3D范围,方向,和姿势在中心点的位置上直接通过图像特征来回归(多个属性对应多个channel)。目标检测问题就是一个标准的关键点估计问题。我们简单的把一个输入图像喂到一个全卷积网络当中生成了一个热力图。该热力图的峰值相应的就是目标的中心。图像特征在每个峰值处预测目标的边界框的高和宽。模型训练使用标准的密集监督学习方法。推理过程就是一个网络的前向运算,不需要非极大值抑制后处理。


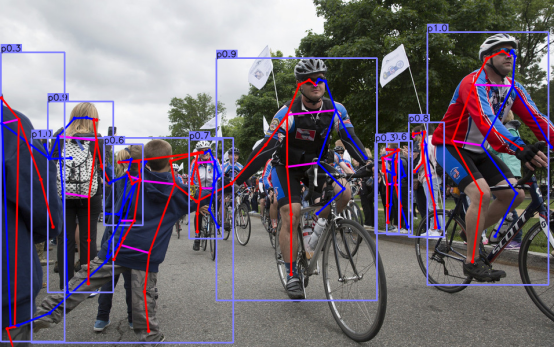
1.3 速度和精度对比图

1.4 关键点和损失
1.4.1关键点
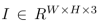
表示一个宽度为W并且高度为H的输入图像。我们的目标是产生一个关键点的heatmap:
其中,R表示输出步长,C是类别个数。一般R=4,在人体关键点估计中包含 C = 17 个人体关节类型,或在目标检测的目标分类中 C = 80个类别。
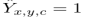
表示对应于一个被检测的关键点
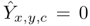
是背景
我们使用几个不同的全卷积编解码网络从一个图像I来预测 Y^ :一个堆叠的hourglass网络,上卷积的残差网络(ResNet)和深层聚合网络(DLA)。
1.4.2关键点数据标签
对于类别c中每一个关键点的真实值:
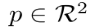
我们计算了一个低分辨率等价的表示:
(注意这里是向下取整)
我们之后把所有的真实的关键点分布在一个heatMap上
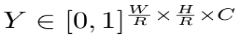
并使用一个高斯卷积核生成一个二维的正态分布:
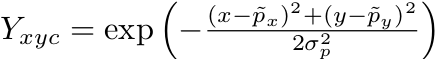

1.4.3 关键点loss
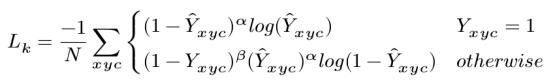
其中α和β是focal loss的超参数。在所有实验中我们采取 α = 2和β = 4
举例: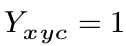
的时候,易分样本Y冒号(网络预测值)接近于1,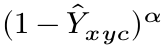
是一个很小的值,loss很小。对于难分类的样本来说,Y冒号(网络预测值)接近于0,说明这个中心点还没有学习到,所以要加大其训练的比重,上面的公式的值就很大。所以对于难样本就加大训练的比重,对于简单样本比重很小。
同样的,otherwise的时候,
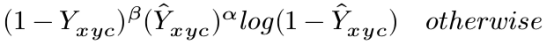
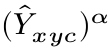
也是控制难样本学习比重大,易样本学习比重小。对于Y=0的时候,对于简单样本,Y冒号接近于0,对于难样本,Y冒号趋于1,学习比重就大。
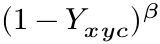
这个系数是作者改进增加的。当是目标中心的时候为1该项目为0,当偏移目标中心的时候,这个值越来越大,代表对于目标中心不惩罚,偏移目标中心越多惩罚的就越多。比如:

这篇博客讲解的centernet loss部分讲的比较好,可以看下:
https://zhuanlan.zhihu.com/p/66048276


1.4.6 弥补量化误差
为了弥补由输出步长造成的量化误差,即由于取整导致的小数部分缺失造成的误差。我们对每个关键点额外预测了一个定位的偏移量.
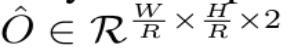
一个目标的所有的类别C共享相同的预测偏移量,偏移量损失用L1 loss表示如下:

1.4.7 目标长宽的回归
表示类别为 Ck的目标k:
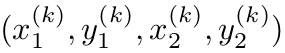
该目标的中心点表示如下:
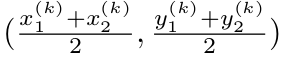
对于每一个目标k回归其尺寸
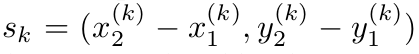
为了限制计算负担,我们为所有目标种类使用单一的尺寸预测
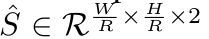
意思就是只预测两个channel一个是W一个是H,而不是一个类别对应两个channel。也使用L1 loss:
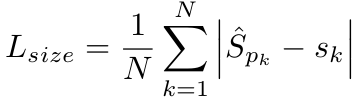
1.4.8 总的loss
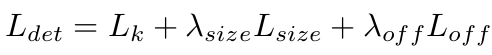
其中,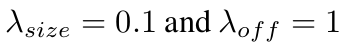
1.5 基于anchor的方法和centernet对比

传统的基于anchor的检测方法,通常选择与标记框IoU大于0.7的作为positive,相反,IoU小于0.3的则标记为negative,如下图a。这样设定好box之后,在训练过程中使positive和negative的box比例为1:3来减少negative box的比例。
而在CenterNet中,每个中心点对应一个目标的位置,不需要进行overlap的判断。那么怎么去减少negative center pointer的比例呢?CenterNet是采用Focal Loss的思想,在实际训练中,中心点的周围其他点(negative center pointer)的损失则是经过衰减后的损失(上文提到的),而目标的长和宽是经过对应当前中心点的w和h回归得到的.
1.6 推理跑前向
在推理阶段,我们对每个类别(一个类别一个channel)先独立地提取heatmap上的峰值点。我们检测所有比周围八临域都大的像素点,论文中使用的是3x3的最大池化,每个类别保留100个。
预测的位置偏移量:
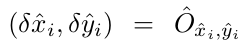
预测的尺寸:
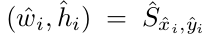
所以,矩形框可以表示如下:
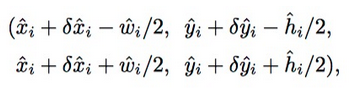
全部的输出直接通过关键点估计来产生,不需要根据IOU来进行非极大值抑制算法或其他后处理算法。峰值关键点的提取作用就是充分的NMS的替代项,而且通过3x3的最大池化操作来被高效的执行。
2.centernet代码---数据处理部分
2.1透视变换1---变换原图到固定尺寸512
初始换关键参数c,s
c = np.array([img.shape[1] / 2., img.shape[0] / 2.], dtype=np.float32)
s = max(img.shape[0], img.shape[1]) * 1.0
随机变换关键参数c,s
s = s * np.random.choice(np.arange(0.6, 1.4, 0.1))
w_border = self._get_border(128, img.shape[1])
h_border = self._get_border(128, img.shape[0])
c[0] = np.random.randint(low=w_border, high=img.shape[1] - w_border)
c[1] = np.random.randint(low=h_border, high=img.shape[0] - h_border)
根据c和s确定三组点,求得透视变换矩阵
trans_input = get_affine_transform(
c, s, 0, [input_w, input_h])
inp = cv2.warpAffine(img, trans_input,
(input_w, input_h),
flags=cv2.INTER_LINEAR)
def get_affine_transform(center,
scale,
rot,
output_size,
shift=np.array([0, 0], dtype=np.float32),
inv=0):
if not isinstance(scale, np.ndarray) and not isinstance(scale, list):
scale = np.array([scale, scale], dtype=np.float32)
scale_tmp = scale
src_w = scale_tmp[0]
dst_w = output_size[0]
dst_h = output_size[1]
rot_rad = np.pi * rot / 180
src_dir = get_dir([0, src_w * -0.5], rot_rad)
dst_dir = np.array([0, dst_w * -0.5], np.float32)
src = np.zeros((3, 2), dtype=np.float32)
dst = np.zeros((3, 2), dtype=np.float32)
src[0, :] = center #中心点
src[1, :] = center + src_dir # #中心点上面y-T
dst[0, :] = [dst_w * 0.5, dst_h * 0.5]
dst[1, :] = np.array([dst_w * 0.5, dst_h * 0.5], np.float32) + dst_dir
src[2:, :] = get_3rd_point(src[0, :], src[1, :]) #中心点上面左边 y-T x-T
dst[2:, :] = get_3rd_point(dst[0, :], dst[1, :])
if inv:
trans = cv2.getAffineTransform(np.float32(dst), np.float32(src))
else:
trans = cv2.getAffineTransform(np.float32(src), np.float32(dst))
return trans
注意这里的c和s,c是在中心点范围内一个随机抖动,s也是会随机忽大忽小,导致在原图上面确定的三个点会随机的超过图像范围,比如会有负数。见图片:



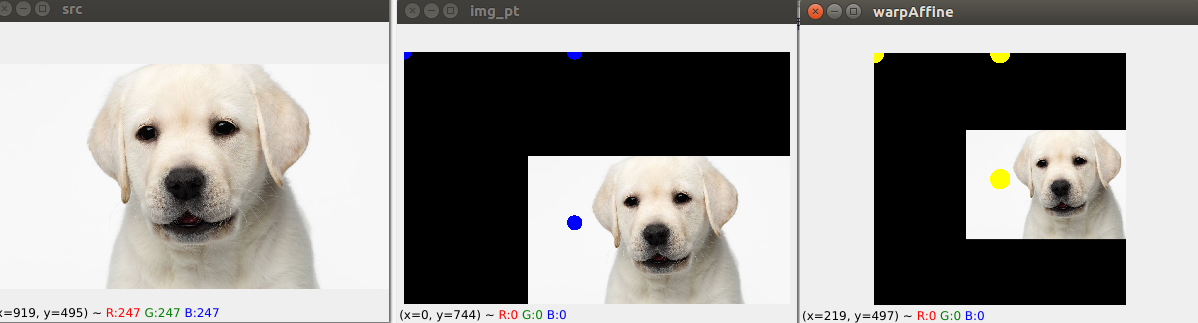

可以看到,黄色点都是固定的三个位置,中心点和上面,左上。蓝色点中心点和s会有随机扰动。但是不管你怎么扰动,都映射到固定的3个点。
第一张图是原图,第二张是我处理过的,根据算出来的pt,如果是负数就补黑边,第三张图是固定的512*512大小,输入网络用的。
2.2透视变换2---变换gt坐标到固定尺寸512/4=128
output_h = input_h // self.opt.down_ratio # 512/4=128
output_w = input_w // self.opt.down_ratio
num_classes = self.num_classes
trans_output = get_affine_transform(c, s, 0, [output_w, output_h])
hm = np.zeros((num_classes, output_h, output_w), dtype=np.float32)
wh = np.zeros((self.max_objs, 2), dtype=np.float32)
reg = np.zeros((self.max_objs, 2), dtype=np.float32)
ind = np.zeros((self.max_objs), dtype=np.int64)
reg_mask = np.zeros((self.max_objs), dtype=np.uint8)
bbox[:2] = affine_transform(bbox[:2], trans_output)
bbox[2:] = affine_transform(bbox[2:], trans_output)
h, w = bbox[3] - bbox[1], bbox[2] - bbox[0]
if h > 0 and w > 0:
radius = gaussian_radius((math.ceil(h), math.ceil(w)))
radius = max(0, int(radius))
radius = self.opt.hm_gauss if self.opt.mse_loss else radius
ct = np.array(
[(bbox[0] + bbox[2]) / 2, (bbox[1] + bbox[3]) / 2], dtype=np.float32)
ct_int = ct.astype(np.int32)
draw_gaussian(hm[cls_id], ct_int, radius)
wh[k] = 1. * w, 1. * h
ind[k] = ct_int[1] * output_w + ct_int[0]
reg[k] = ct - ct_int
reg_mask[k] = 1
ret = {'input': inp, 'hm': hm, 'reg_mask': reg_mask, 'ind': ind, 'wh': wh}
上面就是训练数据制作,hm,wh, reg, ind, mask.
Ground truth 热力图:

假设我们有30类,不包括背景
hm [30,128,128] wh [128,2] reg [128,2] ind[128] reg_mask[128]
128是预设的目标数量。
hm是高斯中心点热力图,一类对应一张图。
wh是目标的长宽。
reg是中心点坐标由于取整带来的偏差。
Ind是中心点相对于原图的位置,相当于把一张图片像素拉成一列,目标中心点坐标在第几个位置。
reg_mask是记录预设的128个目标的到底有无目标的标记,有目标是1。
有几个重要函数:
计算高斯核半径函数:
radius = gaussian_radius((math.ceil(h), math.ceil(w)))
heatmap 上使用高斯核有很多需要注意的细节。CenterNet 官方版本实际上是在 CornerNet 的基础上改动得到的,有很多祖传代码。在使用高斯核前要考虑这样一个问题。下图来自于 CornerNet 论文中的图示,红色的是标注框,但绿色的其实也可以作为最终的检测结果保留下来。那么这个问题可以转化为绿框在红框多大范围以内可以被接受。使用 IOU 来衡量红框和绿框的贴合程度,当两者 IOU>0.7的时候,认为绿框也可以被接受,反之则不被接受。

那么现在问题转化为,如何确定半径 r, 让红框和绿框的 IOU 大于 0.7 。
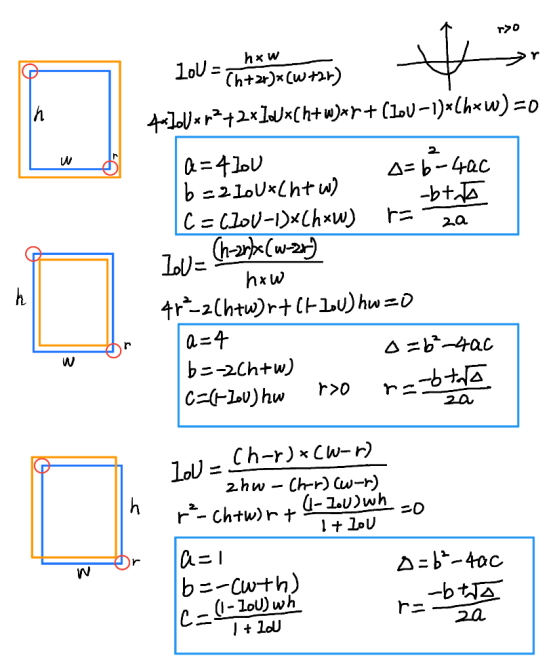
以上是三种情况,其中蓝框代表标注框,橙色代表可能满足要求的框。这个问题最终变为了一个一元二次方程有解的问题,同时由于半径必须为正数,所以 r 的取值就可以通过求根公式获得。
def gaussian_radius(det_size, min_overlap=0.7):
height, width = det_size
a1 = 1
b1 = (height + width)
c1 = width * height * (1 - min_overlap) / (1 + min_overlap)
sq1 = np.sqrt(b1 ** 2 - 4 * a1 * c1)
r1 = (b1 + sq1) / (2 * a1)
a2 = 4
b2 = 2 * (height + width)
c2 = (1 - min_overlap) * width * height
sq2 = np.sqrt(b2 ** 2 - 4 * a2 * c2)
r2 = (b2 + sq2) / (2 * a2)
a3 = 4 * min_overlap
b3 = -2 * min_overlap * (height + width)
c3 = (min_overlap - 1) * width * height
sq3 = np.sqrt(b3 ** 2 - 4 * a3 * c3)
r3 = (b3 + sq3) / (2 * a3)
return min(r1, r2, r3)
可以看到这里的公式和上图计算的结果是一致的。需要说明的是,CornerNet 最开始版本中这里出现了错误,分母不是 2a,而是直接设置为 2 。
CenterNet也延续了这个 bug,CenterNet 作者回应说这个bug 对结果的影响不大。但是,思考一个问题:
Centernet为什么要沿用cornernet的高斯半径计算方式?
cornernet只是为了获得左上和右下两个点,然后约束的三种方式进行高斯半径计算,centernet只是为了获得中心点的高斯半径,和两个点没有关系。查询了CenterNet论文还有官方实现的issue,其实没有明确指出为何要用CornerNet的半径,issue中回复也说是这是沿用了CornerNet的祖传代码。
看看后面用到半径的代码部分:在centerNet中,半径的存在主要是用于计算高斯分布的sigma值,而这个值也是一个经验性判定结果。
sigma=diameter / 6
def gaussian2D(shape, sigma=1):
m, n = [(ss - 1.) / 2. for ss in shape]
y, x = np.ogrid[-m:m+1,-n:n+1]
h = np.exp(-(x * x + y * y) / (2 * sigma * sigma))
h[h < np.finfo(h.dtype).eps * h.max()] = 0
return h
def draw_umich_gaussian(heatmap, center, radius, k=1):
diameter = 2 * radius + 1
gaussian = gaussian2D((diameter, diameter), sigma=diameter / 6)
x, y = int(center[0]), int(center[1])
height, width = heatmap.shape[0:2]
left, right = min(x, radius), min(width - x, radius + 1)
top, bottom = min(y, radius), min(height - y, radius + 1)
masked_heatmap = heatmap[y - top:y + bottom, x - left:x + right]
masked_gaussian = gaussian[radius - top:radius + bottom, radius - left:radius + right]
if min(masked_gaussian.shape) > 0 and min(masked_heatmap.shape) > 0: # TODO debug
np.maximum(masked_heatmap, masked_gaussian * k, out=masked_heatmap)
return heatmap
举例,当R=3时候:
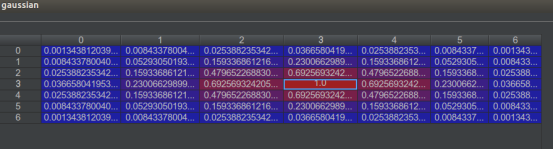
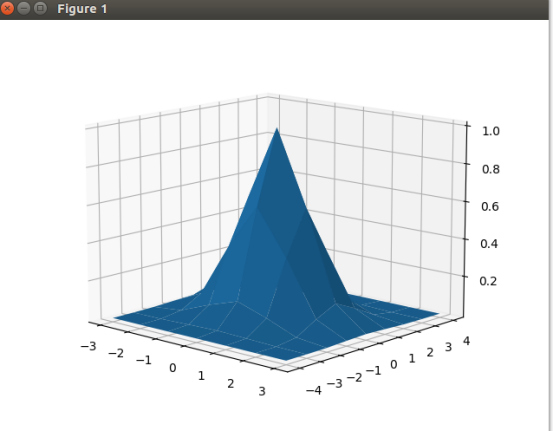
画高斯图脚本:
import numpy as np
y,x = np.ogrid[-4:5,-3:4]
sigma = 1
h=np.exp(-(x*x+y*y)/(2*sigma*sigma))
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
ax = Axes3D(fig)
ax.plot_surface(x,y,h)
plt.show()
之前很多人在知乎上issue里讨论这个半径计算的时候,有提到这样的问题,就是如果将CenterNet对应的2a改正确了,反而效果会差。
我觉得这个问题可能和这里的sigma=diameter / 6有一定的关系,作者当时用祖传代码(2a那部分有错)进行调参,然后确定了sigma。这时这个sigma就和祖传代码是对应的,如果修改了祖传代码,同样也需要改一下sigma或者调一下参数。
我在github上面也提问了:
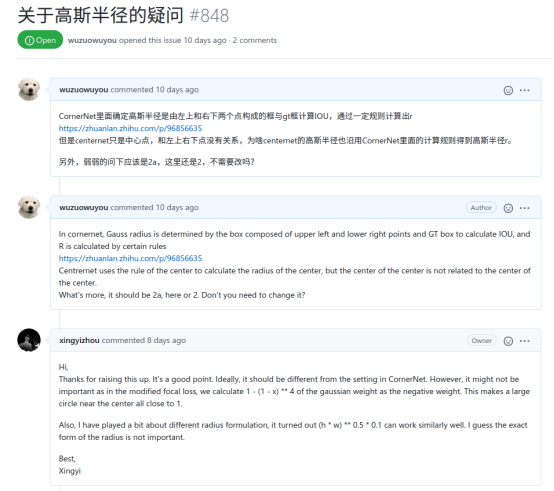
Hi,Thanks for raising this up. It's a good point. Ideally, it should be different from the setting in CornerNet. However, it might not be important as in the modified focal loss, we calculate 1 - (1 - x) ** 4 of the gaussian weight as the negative weight. This makes a large circle near the center all close to 1.
Also, I have played a bit about different radius formulation, it turned out (h * w) ** 0.5 * 0.1 can work similarly well. I guess the exact form of the radius is not important.
Best,
Xingyi
3.centernet代码---骨干网络dla-34
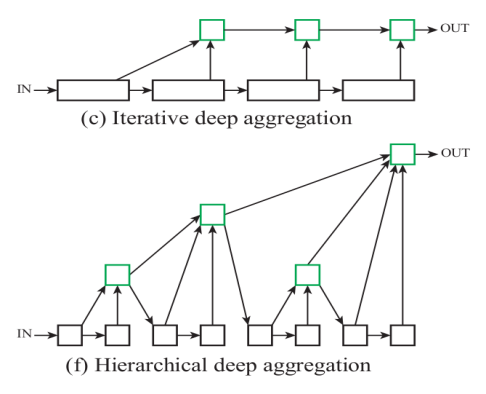
Deep Layer Aggregation提出两种抽象的网络架构:Stage之间使用iterative deep aggregation【IDA】,Stage内使用Hierarchical deep aggregation【HDA】,称为迭代聚合以及层次聚合。
IDA主要进行跨分辨率和尺度的融合,而HDA主要融合各个模组和通道的特征图(原文为feature)。IDA根据基础网络结构,逐级提炼分辨率和聚合尺度(类似于残差模块)。HDA整合其自身的树状连接结构,并将各个层级聚合为不同等级的表征(空间尺度的融合,类似于FPN)。本文的策略可以通过混合使用IDA与HDA来共同提升效果。
语义融合与空间融合的区别:
语义融合:
融合的是不同层级间的通道内信息;
通道大多在通道数上不同,空间尺度上相同,不需要尺度对齐;
主要保留微观信息。
空间融合:
融合的是不同层级间的特征图信息;
通道数是相同的,空间尺度上等比缩放,需要尺度对齐,也就是文中所说的均一化和标准化,主要保留宏观信息;
什么是聚合,与融合有什么不同?
融合分成语义融合和空间融合,语义(物体信息)融合能够推断“是什么”,空间融合能够推断“在哪里”。而聚合就是语义融合和空间融合的组合。
IDA和HDA分别有什么优点?
IDA是一种迭代式聚合,从图(c)可以看到前面浅层信息不断地与后面的深层信息聚合,这样子,前面的浅层信息能够不断地提炼,能够丰富的语义信息。但IDA呈序列性,难以组合不同块的信息。HDA是一种树状结构块的分层聚合,以更好地学习跨越不同深度的网络特征层次的丰富(空间)信息。所以IDA和HDA的结构既能学习到语义信息也能学习到空间信息。

优点(1)融合分辨率和尺寸(2)避免最浅层的部分会对最终结果产生最深远影响。
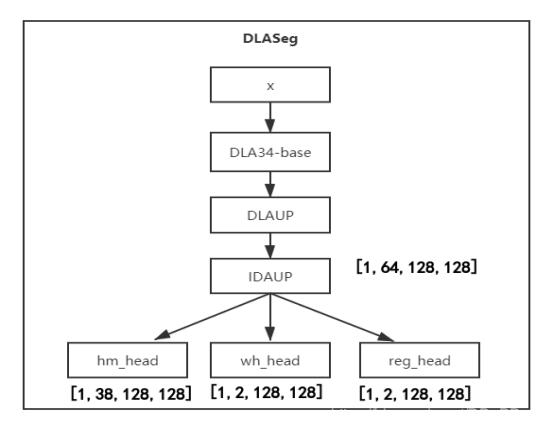
Centernet网络概图:
(hm): Sequential(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(256, 38, kernel_size=(1, 1), stride=(1, 1))
)
(wh): Sequential(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(256, 2, kernel_size=(1, 1), stride=(1, 1))
)
(reg): Sequential(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(256, 2, kernel_size=(1, 1), stride=(1, 1))
)
heatmap: 38代表类别数,一个类别对应一个通道
wh:2代表回归的中心对应的长和宽
reg: 2代表中心点坐标x,y对应的偏移量
作者提供的基网络还有hourglass,resnet,还有加了可变形卷积的dcn。有兴趣的可以自行研究。
4.centernet代码---损失函数
4.1heatmap loss
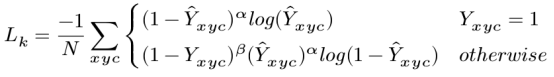
output['hm'] = _sigmoid(output['hm'])
hm_loss += self.crit(output['hm'], batch['hm'])
这里output[‘hm’]形状是[1,38,128,128]
batch[‘hm’]形状是[1,38,128,128]
def _neg_loss(pred, gt):
pos_inds = gt.eq(1).float()
neg_inds = gt.lt(1).float()
neg_weights = torch.pow(1 - gt, 4)
loss = 0
pos_loss = torch.log(pred) * torch.pow(1 - pred, 2) * pos_inds
neg_loss = torch.log(1 - pred) * torch.pow(pred, 2) * neg_weights * neg_inds
num_pos = pos_inds.float().sum()
pos_loss = pos_loss.sum()
neg_loss = neg_loss.sum()
if num_pos == 0:
loss = loss - neg_loss
else:
loss = loss - (pos_loss + neg_loss) / num_pos
return loss
neg_weights是很重要的系数,1-gt的4次方,表明在中心点的时候不需要惩罚,但是随着偏离中心点越多,这个系数就越大,惩罚就越大。
4.2wh loss
wh_loss += self.crit_reg(
output['wh'], batch['reg_mask'],
batch['ind'], batch['wh'])
这里,output[‘wh’]形状是[1,2,128,128]
batch[‘reg_mask’]形状是[1,128]
batch[‘ind’]形状是[1,128]
batch[‘wh’]形状是[1,128,2]
由于output[‘wh’]与batch[‘wh’]形状不一样,需要根据ind到output[‘wh’]里面提取ind所记录的位置上面的值。
class RegL1Loss(nn.Module):
def __init__(self):
super(RegL1Loss, self).__init__()
def forward(self, output, mask, ind, target):
pred = _transpose_and_gather_feat(output, ind) # [1,2,128,128] [1,128]
# pred[1,128,2] target[1,128,2]
mask = mask.unsqueeze(2).expand_as(pred).float()
loss = F.l1_loss(pred * mask, target * mask, size_average=False)
loss = loss / (mask.sum() + 1e-4)
return loss
def _gather_feat(feat, ind, mask=None):# #[1,128*128,2] [1,128]
dim = feat.size(2) #2
ind = ind.unsqueeze(2).expand(ind.size(0), ind.size(1), dim) # [1,128,1] [1,128,2]
feat = feat.gather(1, ind) #[1,128,2] -->> [1,128*128,2] [1,128,2]
return feat
def _transpose_and_gather_feat(feat, ind): # [1,2,128,128] [1,128]
feat = feat.permute(0, 2, 3, 1).contiguous() #[1,128,128,2]
feat = feat.view(feat.size(0), -1, feat.size(3)) #[1,128*128,2]
feat = _gather_feat(feat, ind)
return feat
4.3reg loss
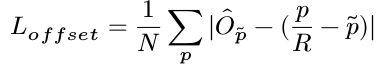

reg loss与wh loss一样采用的是L1 loss
4.4centernet loss

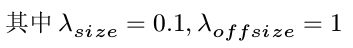
5.centernet代码--前向推理
5.1数据预处理
推理的时候c和s是固定的,不添加随机操作。
new_height, new_width= image.shape[0:2]
inp_height, inp_width = 512,512
c = np.array([new_width / 2., new_height / 2.], dtype=np.float32)
s = max(height, width) * 1.0
trans_input = get_affine_transform(c, s, 0, [inp_width, inp_height])
inp_image = cv2.warpAffine(
image, trans_input, (inp_width, inp_height),
flags=cv2.INTER_LINEAR)
inp_image = ((inp_image / 255. - opt.mean) / opt.std).astype(np.float32)
images = inp_image.transpose(2, 0, 1).reshape(1, 3, inp_height, inp_width)
images = torch.from_numpy(images)
meta = {'c': c, 's': s,
'out_height': inp_height // 4,
'out_width': inp_width // 4}
return images, meta
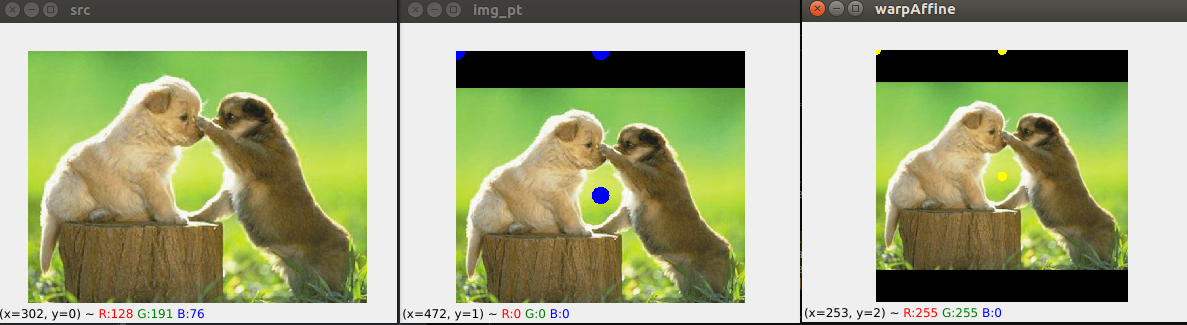
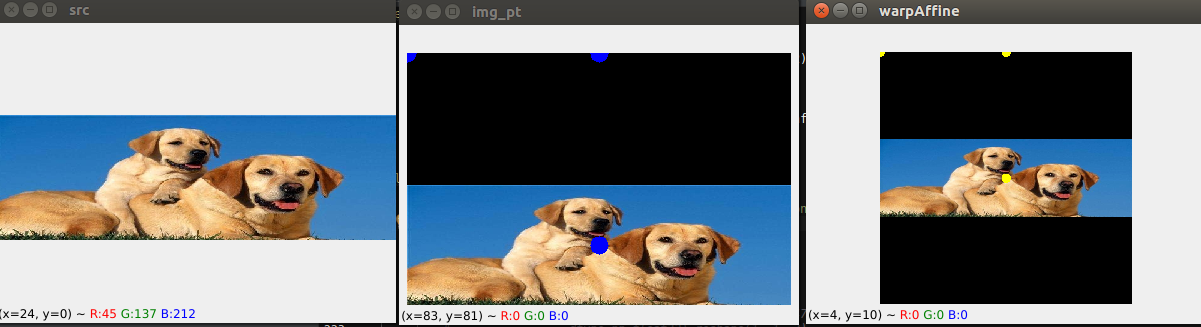

在推理的时候三个点按照固定的规则取点,不做随机扰动,可以看到,中心点,和s,右边图是仿射变换变换之后的固定512大小的。
效果图看来好像是把图像拉到中间。
5.2模型推理
output = model(images)
hm = output['hm'].sigmoid_() #[1,38,128,128]
wh = output['wh'] #[1,2,128,128]
reg = output['reg'] #[1,2,128,128]
5.3解码
def _nms(heat, kernel=3):
pad = (kernel - 1) // 2
hmax = nn.functional.max_pool2d(
heat, (kernel, kernel), stride=1, padding=pad)
keep = (hmax == heat).float()
return heat * keep
heat = _nms(heat)
scores, inds, clses, ys, xs = _topk(heat, K=K) # all is [1,100]
if reg is not None:
reg = _transpose_and_gather_feat(reg, inds)
reg = reg.view(batch, K, 2)
xs = xs.view(batch, K, 1) + reg[:, :, 0:1]
ys = ys.view(batch, K, 1) + reg[:, :, 1:2]
wh = _transpose_and_gather_feat(wh, inds)
wh = wh.view(batch, K, 2)
clses = clses.view(batch, K, 1).float()
scores = scores.view(batch, K, 1)
bboxes = torch.cat([xs - wh[..., 0:1] / 2,
ys - wh[..., 1:2] / 2,
xs + wh[..., 0:1] / 2,
ys + wh[..., 1:2] / 2], dim=2)
detections = torch.cat([bboxes, scores, clses], dim=2)
5.4坐标映射到原图
def transform_preds_my(coords,trans):
target_coords = np.zeros(coords.shape)
# trans = get_affine_transform(center, scale, 0, output_size, inv=1)
for p in range(coords.shape[0]):
target_coords[p, 0:2] = affine_transform(coords[p, 0:2], trans)
return target_coords
def ctdet_post_process_my(dets, c, s, h, w, conf_thresh):
#dets [x1,y1,x2,y2,score,cls]
trans = get_affine_transform(c[0], s[0], 0, (w, h), inv=1)
a = dets[0][[dets[0][:, 4] >= conf_thresh]]#去除分数低的
a[:, :2] = transform_preds_my(
a[:, 0:2],trans)
a[:, 2:4] = transform_preds_my(
a[:, 2:4],trans)
return a ##a[x1,y1,x2,y2,score,cls]
6.实验部分
自己的三个数据集训练测试结果。注意:本次实验训练都是用的尺寸512,dla-34(nodcn)的centernet。也训练过dla-34(dcn)的,但是收敛loss没有nodcn的低。
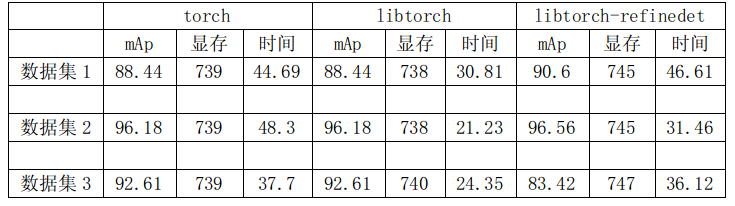
可以看出:
(1)pytorch和libtorch的mAp和显存是一致的,时间libtorch会少。
(2)centernet的精度比refinedet稍微低2个点以内。但是在数据集3会高。数据集3中第6类refinedet的map为0,centernet为52.
(3)libtorch版本的centernet和refinedet的显存差不多,整体运行时间centernet会比refinedet运行时间少10ms以上。
7.一些问题
7.1推理的时候坐标变换的问题
如图,是推理的时候也同样三个点做透视变换。把输入图固定为512.
然后模型推理输出是128的heatmap热力图,然后再把坐标直接映射到原图了?按照上面的,应该是映射到带黑色的中间的这张图?
我一开始就是这么认为的,应该就是把坐标映射到中间这张图了,然而现象就是映射到原图。
def pre_process(opt, image, scale=1.0, meta=None):
height, width = image.shape[0:2]
new_height = int(height * scale)
new_width = int(width * scale)
if 1:# if self.opt.fix_res:
inp_height, inp_width = opt.input_h,opt.input_w
c = np.array([new_width / 2., new_height / 2.], dtype=np.float32)
s = max(height, width) * 1.0
trans_input = get_affine_transform(c, s, 0, [inp_width, inp_height])
inp_image = cv2.warpAffine(
image, trans_input, (inp_width, inp_height),
flags=cv2.INTER_LINEAR)
inp_image = ((inp_image / 255. - opt.mean) / opt.std).astype(np.float32)
images = inp_image.transpose(2, 0, 1).reshape(1, 3, inp_height, inp_width)
images = torch.from_numpy(images)
meta = {'c': c, 's': s,
'out_height': inp_height // opt.down_ratio,
'out_width': inp_width // opt.down_ratio}
return images, meta
这里根据c和s确定三个点算法透视变换矩阵把原始图片透视到512大小。并把c和s传出供后续反透视变换。
模型推理出的坐标都是相对于heatmap热力图128大小的。
def ctdet_post_process_my(dets, c, s, h, w, conf_thresh):
trans = get_affine_transform(c[0], s[0], 0, (w, h), inv=1)
a = dets[0][[dets[0][:, 4] >= conf_thresh]]
a[:, :2] = transform_preds_my(
a[:, 0:2],trans)
a[:, 2:4] = transform_preds_my(
a[:, 2:4],trans)
return a
可以看到这里,c和s传进来,但是这里的w,h是128,inv为1了,是说需要把src和dst的坐标互换。 把128大小的图像映射到以c和s为坐标系的图像。
根据现象强行解释一波:
中间图就是c和s的图像,但是这个c和s有负数,负数的基准还是原图,相对于原图的。所以这里其实就是映射到原图的坐标。
7.2中心点重合问题
CenterNet中的冲突是目标框的中心点重合(基于输出特征层计算的中心点),作者从COCO数据集的统计信息来看,这种重合框的比例非常少,不到0.1%,基本上不会对训练稳定产生太大影响,因此没有针对这个进行解决。
对于不同类别的中心点重合目前代码里面参数self.opt.cat_spec_wh打开就可以,对于同类别中心点重合没法解决。
cat_spec_wh = np.zeros((self.max_objs, num_classes * 2), dtype=np.float32)
cat_spec_wh[k, cls_id * 2: cls_id * 2 + 2] = wh[k]
小弟不才,同时谢谢友情赞助!
