<p><iframe name="ifd" src="https://mnifdv.cn/resource/cnblogs/LearnMysql" frameborder="0" scrolling="auto" width="100%" height="1500"></iframe></p>
Druid
Druid连接池是阿里巴巴开源的数据库连接池项目.
https://github.com/alibaba/druid/wiki/Druid%E8%BF%9E%E6%8E%A5%E6%B1%A0%E4%BB%8B%E7%BB%8D
为啥要用连接池
1.数据库本身也是个TCP服务器,客户端和数据库通信首先需要先连接TCP服务器
然后再根据数据库的协议连接上数据库.
服务器回复 "Response OK" 的消息体就说明连接上了.
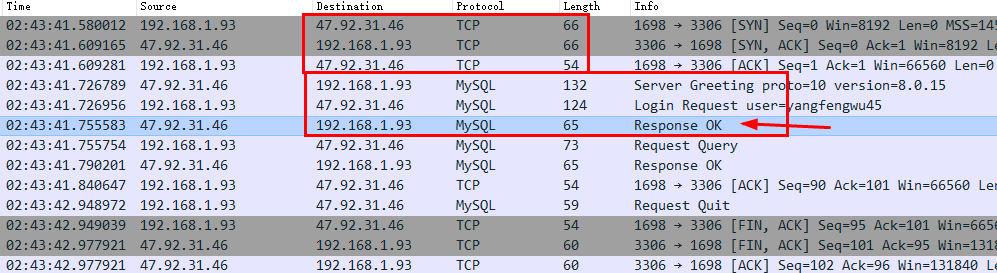
2.现在有两个问题需要解决:很多用户连接通信的问题 ,和需要快速操作数据的问题
实际上连接数据库的客户端的个数是有限的;
如果有200个用户同时都建立链接,那么有一部分用户就连接不上了.
用户可以用命令看一下 show variables like '%max_connections%';

咱每次操作数据库的时候都需要连接的步骤,这个步骤每次都有延迟!!体验一点不好!
3.解决以上问题的最好方式是加一个对外的接口和一个连接池
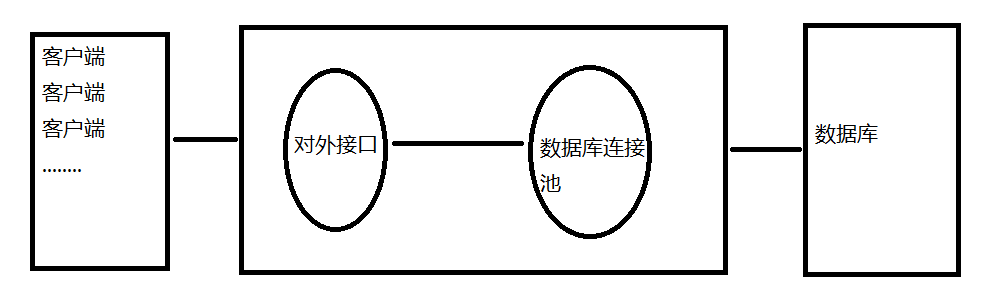
对外接口的作用是拿到数据以后调用数据库连接池,然后由连接池和数据库通信.
数据库连接池其实就是提前预先建立了多个数据库连接对象;
假设建立了20个和数据库的连接.
4.连接池的作用
连接池里面的的客户端都是早已和数据库连接着的,当需要和数据库通信的时候
就从里面取出一个来客户端,然后发数据通信.省去了连接数据库的过程,提高了效率!
如果请求非常多,那么最多也就只有20个连接.不会造成因为连接个数过多而导致数据库性能下降!
注:有些用户会想,这不是也有问题嘛!才20个! 接着往下看!
连接池的作用就是省去了连接数据库的过程,提高了数据通信速度.
防止过多的连接和数据库相连而导致数据库性能下降!
5.接口的作用
在网络通信中,这个接口一般是 http接口,当然也可以是TCP接口,mqtt接口,WebSocket接口等;以下皆说为 接口
接口的作用一部分是为了接受客户过来的数据,另一部分就是缓存用户过来的数据.
然后呢就是不停的到数据库连接池里面去拿连接对象,然后和数据库进行交互!
然后有人会问?解决了20个问题了没??
可以说解决了99%了.
大家要明确一个事情,看似数据被缓存了不假 ,但是网络通信的速度是非常快的,其实上百个乃至上千个用户访问数据
他们不会感受到的.
剩下的1%其实就是应对极端情况,上百万,千万的人...
内部处理思路还是上面那个样子,但是呢为了应对这种极端情况就要采取下面的措施
1.优化代码,提高代码的执行效率
2.多开几台服务器
Druid连接池使用
Druid其实是对连接数据库的对象进行管理,所以咱也需要连接数据库的jar包(JDBC).
因为5.X的MySQL数据库和8.X的MySQL数据库的连接jar包不一样了,所以我提供了两份程序.
注:两份程序的Druid的jar包是一样的,只是连接MySQL数据库jar不一样
先看连接8.X的数据库(运行可能报错,请往下面看)
1.导入jar包什么的自己导入,我用的软件是 intellij idea
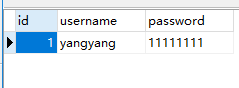
2.数据库
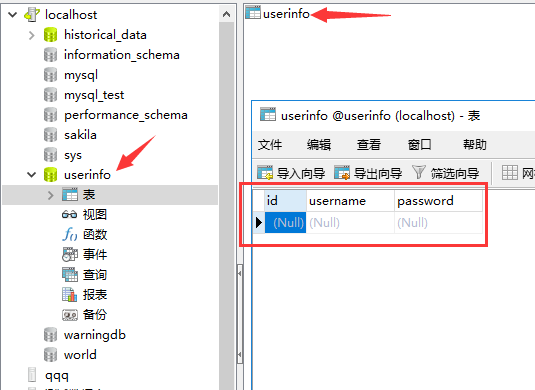
3.我只写了插入一个数据的程序
package com.company; import com.alibaba.druid.pool.DruidDataSource; import java.sql.Connection; import java.sql.PreparedStatement; public class Main { /*声明Druid连接池的对象*/ private static DruidDataSource dataSource; /*8.X版本连接器写法*/ static final String JDBC_DRIVER = "com.mysql.cj.jdbc.Driver"; /*数据库地址*/ static final String DB_URL = "jdbc:mysql://localhost/userinfo?" + "useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT"; public static void main(String[] args) { initDataSource();// 初始化连接池 try{//插入一个数据 String sql = "insert into userinfo (username,password)"+ "values(" +"'"+ "yangyang" +"'"+ "," +"'"+"11111111"+"'"+")"; Connection connection = getConnect();//在连接池里面获取连接对象 PreparedStatement ps = connection.prepareStatement(sql);//预编译下SQL语句 int count = ps.executeUpdate();//提交SQL语句 System.out.println(count);//打印受影响的行数(不为0说明执行了!) }catch (Exception e){ System.out.println(e.toString()); } } // 初始化连接池 private static void initDataSource() { try { dataSource = new DruidDataSource(); // 创建Druid连接池 dataSource.setDriverClassName(JDBC_DRIVER); // 设置连接池的数据库驱动 dataSource.setUrl(DB_URL); // 设置数据库的连接地址 dataSource.setUsername("iot"); // 数据库的用户名 dataSource.setPassword("11223344."); // 数据库的密码 dataSource.setInitialSize(1); // 设置连接池的初始大小 dataSource.setMinIdle(1); // 设置连接池大小的下限 dataSource.setMaxActive(20); // 设置连接池大小的上限 }catch (Exception e){ System.out.println(e.toString()); } } //从连接池里面获取一个连接对象 public static Connection getConnect() throws Exception{ Connection con=null; try { con=dataSource.getConnection(); } catch (Exception e) { throw e; } return con; } }
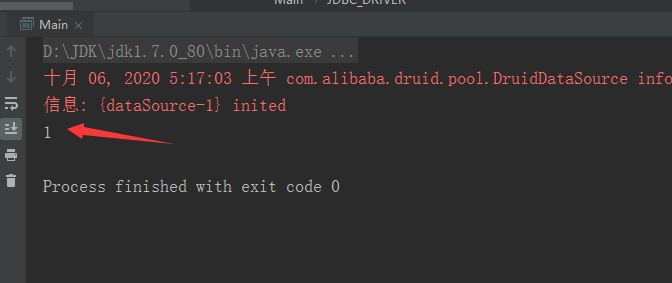
4.运行以后
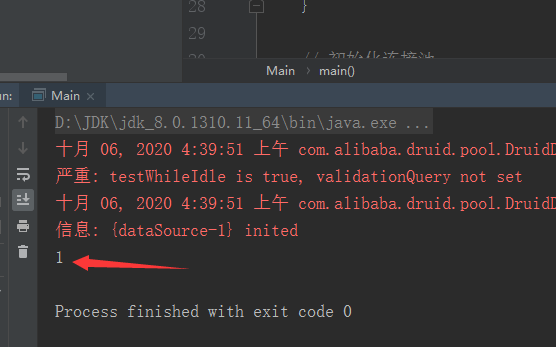
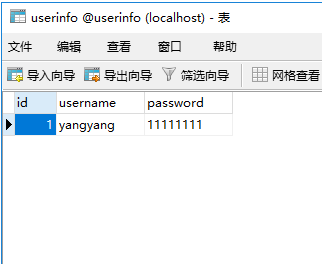
5.提示:8.0的需要JDK1.8版本的,如果你的jar包是1.8以下版本的将会报错
用户可以安装上1.8版本的jar包,
注意只安装上,不用配置环境变量!
注意只安装上,不用配置环境变量!
注意只安装上,不用配置环境变量!
然后设置下软件使用的jdk (根据自己的软件百度下设置JDK)
其实就是选择下JDK的安装路径(根据自己的软件百度)
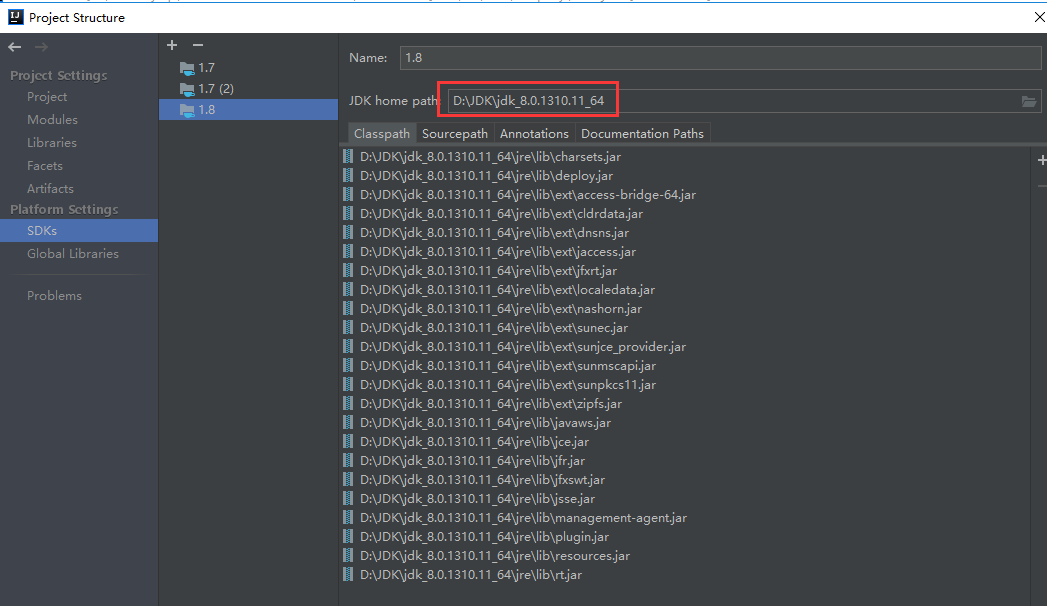
选择要使用的JDK版本
现在看连接5.X的数据库
1.把jar包换了

2.JDK选择的 1.7
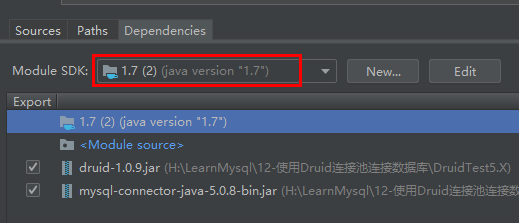

3.驱动器名字改为了
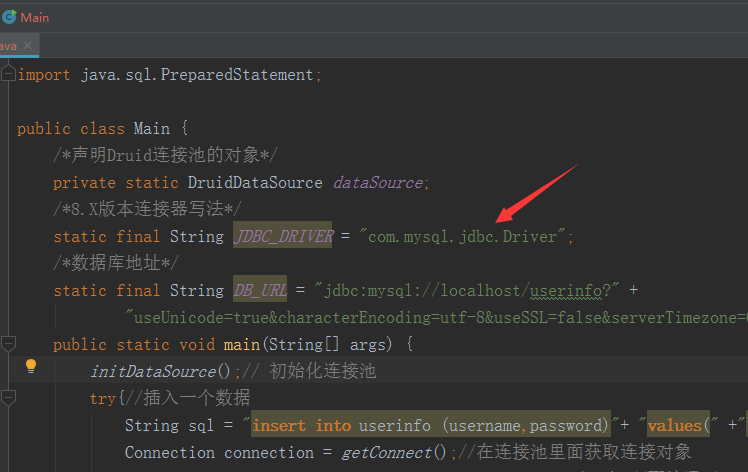
4.运行测试