首先 索引长度和区分度是相互矛盾的,
索引长度太短,那么区分度就很低,吧索引长度加长,区分度就高,但是索引也是要占内存的,所以我们需要找到一个平衡点;
那么这个平衡点怎么来定?
比如用户表有个字段 username ,要给他加索引,问题是索引长度多少合适?
其实我们知道 百家姓里面有百多个姓 ,但是大多数人的姓 集中在前十多个;如果我设置索引索引长度为1,对染占内存少,但是区分度低,
区分度低索引的效率越低。太长则占内存;
首先你要知道 mysql的索引都是排好序的。如果区分度高排序越快,区分度越低,排序慢;
举个例子: (张,张三,张三哥),如果索引长度取1的话,那么每一行的索引都是 张 这个字,完全没有区分度,你让他怎么排序?结果这样三行完全是随机排的,因为索引都一样;
如果长度取2,那么排序的时候至少前两个是排对了的,如果取3,区分度达到100%,排序完全正确;
等等,那你说是不是索引越长越好? 答案肯定是错的,比如 (张,李,王) 和 (张三啦啦啦,张三呵呵呵,张三呼呼呼);前者在内存中排序占得空间少,排序也快,后者明显更慢更占内存,在大数据应用中这一点点都是很恐怖的;
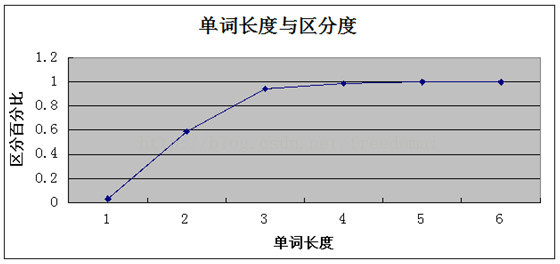
这个地方观察到,当索引长度达到4的时候就已经趋向1了,所以长度设为4是最佳的,在大点增加的索引效果已经很小了,这个地方不是说必须接近1才行;
其实这个值达到0.1就已经可以接受了;总之要找一个平衡点;