关于员工信息查询的画了一个简单的流程图
查询流程图
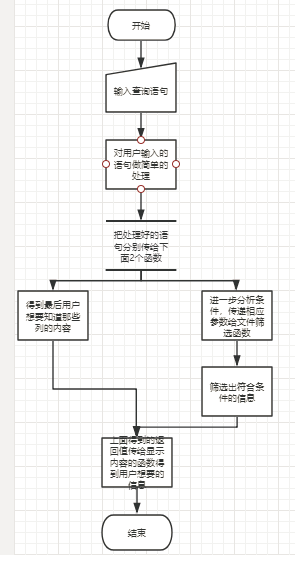
实现的思路:
查询
1、我们得到要查询的语句先把这个语句做简单的处理得到我们想要的数据
condition = input(">>>:").lower().replace(' ', '') # 不区分大小写 "selectname,agewhereage>20" ret = condition.split('where') # ['selectage,name', 'age>2']
上面可以简单的得到我们从用户输入的地方想要的2个信息
- 用户想要显示那些信息(比如员工的年龄,名字等)
- 用户对员工查询的条件(姓名,查找大于多少岁的等)
2、把从用户得到的2个数据分别传入一个为处理用户想要显示那些列的函数中一个传入从员工信息筛选的函数中得到符合条件的员工信息。
处理得到想要查询的内容列表
def get_show_lst(col_condition): """ 解析传进来的参数得到我们要显示的列名 :param col_condition: 用户输入后解析的条件 :return:列表组成的字典 """ # 'select age,name' col_info_lst = col_condition.split('select') # ['', 'age,name'] col_info = [col_info_item for col_info_item in col_info_lst if col_info_item.strip()] # ['age,name'] if "*" in col_info: # 查询所有信息 return column_dic.keys() # dict_keys(['id', 'name', 'age', 'phone', 'job']) else: ret = col_info[0].split(',') # ['age', 'name'] for i in ret: if i not in column_dic.keys(): # 判断要显示的列的有没有 print('您输入的查询条件不正确') sys.exit(0) return ret # ['age', 'name']
筛选到符合条件的信息
def filter_handler(operate, con): """ 把文件中符合条件的筛选出来作为一个列表当成元素加入到一个列表中 :param operate: 用户进行的操作 > | < | = | like :param con:用户输入的where条件 :return:被筛选出来的行按条件转换成列表加入到一个列表中的元素 """ # '>','age>2' selected_lst = [] col, val = con.split(operate) # age 2 judge = 'int(line_lst[column_dic[col]]) %s int(val)'% operate if operate=='<' or operate=='>' else 'line_lst[column_dic[col]]' f = open('users', encoding='utf8') for line in f: line_lst = line.strip().split(',') # ['1','alex','28','18765789854','python'] if not line_lst[2].isdigit(): # 有可能员工信息的年龄为空 continue if eval(judge): selected_lst.append(line_lst) f.close() return selected_lst def get_selected_line(con): """ 获取符合该条件的每一行,并将符合条件的每一行作为一个列表项存储在selected_lst中 :param con: :return: 存储符合条件的行列表 """ # 'age>2' if '>' in con: selected_lst = filter_handler('>',con) elif '<' in con: selected_lst = filter_handler('<', con) elif '=' in con: selected_lst = filter_handler('==', con.replace('=','==')) elif 'like' in con: selected_lst = filter_handler('in', con) return selected_lst
3、把得到的处理后的参数传给显示最后结果的函数
def show(selected_lst, show_lst): """ 把符合要求的内容显示出来 :param selected_lst: [['1','alex','28','18765789854','python'],[],] :param show_lst: ['age', 'name'] :return: """ if not selected_lst: print('您要查询信息不存在') for i in selected_lst: # [['1','alex','28','18765789854','python'],[],] for j in show_lst: # ['age', 'name'] print(i[column_dic[j]],end=' ') # 把同一个人的信息显示在同一行 print() # 第二个人换一行输出
删除
这个删除主要是利用员工的id删除其它的删除不行。删除语句为:delete where id = 1。
通过处理输入的删除语句把处理得到的数据传入函数del_filter_handler里面删除想要删除的信息。
def file_del(condition): """ 删除语句:delete where id = 1 是根据员工的id来删除数据的 :return: """ try: del_id = condition.split('where')[1].replace(' ', '') # 'id=1' ret = del_filter_handler(del_id) # 'id=1' return 删除成功 if ret: print('删除成功') else: print('要删除的员工id不存在') except Exception: print('只能根据员工的ID删除员工')
上面的根据flag的值知道我们要删除的员工id有没有或者是否删除成功
修改
先把更新语句传入到file_update()函数里面在这里面我们得到要更新的员工id号,再把要更新的更新语句传入get_update_info()函数里面
def file_update(condition): """ 修改语句:'update name=badkano,age=30 where id=3' :return: """ update_con = get_update_info(condition.split('where')[0]) # 'update name=badkano,age=30' return:[{name:badkano},{age:30}] update_id = condition.split('where')[1].split('=')[1] # '3' update_ret = update_info(update_con, update_id) if update_ret: print('更新完毕') else: print('没有此员工')
get_update_info()函数处理得到信息得到一个 处理好的字典
def get_update_info(info): # # 'update name=badkano,age=30' """ :param info: 分解后得到的用户输入的信息:'update name=badkano,age=30' :return: 返回一个列表中含有修改的键值对字典 [{name:badkano},{age:30}] """ hander_lst = [] hander_info = info.split('update')[1].split(',') # ['name=badkano','age=30'] for i in hander_info: hander_lst.append({i.split('=')[0]: i.split('=')[1]}) return hander_lst # [{name:badkano},{age:30}]
把上面得到的字典和员工的id传入update_info()函数里面这个函数就是用来更新员工信息的函数这个函数有一个返回值告诉我们是否有这个员工和员工信息更新成功与否
def update_info(update_con, update_id): """ :param update_con: [{name:badkano},{age:30}] :param update_id: id :return: True or False """ flag = False with open('users', 'r', encoding='utf8') as oldf, open('users', 'w', encoding='utf8') as newf: for line in oldf: if line.strip().split(',')[0] == update_id: # 找到想要修改的 line_lst = line.strip().split(',') # [0, alex, 28, 18765789854, python] for i in update_con: for j in i: line_lst[column_dic[j]] = i[j] line = ','.join(line_lst) flag = True newf.write(line) os.remove('users') os.rename('users', 'users') return flag
增加
这个增加会在文件的最后面。先查看文件中有没有信息,有信息就查看文件里面最后一个员工的id是多少我们加进去的员工信息的id就是最后一个id+1。
在处理增加的员工的语句,提取出有用的信息,在加到文件中。
def file_create(condition): """ 增加语句: create name,age,phone,job value alex,22,16765879652,linux 如果没有name则显示不能增加,其他值没有为空 :return: """ # {'name':'alex', 'age':'22'} dic = {} lst = [None, None, None, None, None] # 顶一个员工信息的列表全部为空,是为了方便后面把要添加的员工信息添加到相应的位置 handle_con = condition.split('value') # 分解上面添加员工信息的语句 handle_con[0] = handle_con[0].split('create')[1] # 相当于把得到 ['name,age,phone,job','alex,22,16765879652,linux'] handle_key = handle_con[0].split(',') # ['name','age','phone','job'] handle_value = handle_con[1].split(',') # ['alex','22','16765879652','linux'} index = 0 for i in handle_key: dic[i] = handle_value[index] index += 1 # dic = {'name':'alex','age':'22','phone':'16765879652','job':'linux'} files = os.path.getsize('users') # 判断文件是不是空的 with open('users', 'r', encoding='utf8') as oldf, open('newusers', 'w', encoding='utf8') as newf: if files: # 当文件不是空的时候获取添加员工信息的id号 for line in oldf: id_num = line.strip().split(',')[0] # 得到最后一行的id lst[0] = str(int(id_num)+1) newf.write(line) else: lst[0] = '0' for key in dic: lst[column_dic[key]] = dic[key] # 把员工的信息放到相应的位置 lst_ret = ','.join(lst) # 转换为字典 newf.write(lst_ret + ' ') # 把信息加到文件最后一行 os.remove('users') os.rename('newusers', 'users') print('您成功增加了一条信息为:', dic)
上面就是
最后的代码为:
import sys import os column_dic = {'id': 0, 'name': 1, 'age': 2, 'phone': 3, 'job': 4} # 文件中每一列的名字和数字的对应关系 # select age,name where age>2 def search_filter_handler(operate, con): """ 把文件中符合条件的筛选出来作为一个列表当成元素加入到一个列表中 :param operate: 用户进行的操作 > | < | = | like :param con:用户输入的where条件 :return:被筛选出来的行按条件转换成列表加入到一个列表中的元素 """ # '>','age>2' selected_lst = [] col, val = con.split(operate) # age 2 judge = 'int(line_lst[column_dic[col]]) %s int(val)' % operate if operate == '<' or operate == '>' else 'line_lst[column_dic[col]]' f = open('users', encoding='utf8') for line in f: line_lst = line.strip().split(',') # ['1','alex','28','18765789854','python'] if eval(judge): selected_lst.append(line_lst) f.close() return selected_lst def del_filter_handler(del_id): # 'id=1' """ 根据ID删除员工信息 :return: """ flag = False user_id = del_id.split('=')[1] # '1' with open('users', 'r', encoding='utf8') as oldf, open('users', 'w', encoding='utf8') as newf: for line in oldf: if user_id == line.split(',')[0]: flag = True continue newf.write(line) os.remove('users') os.rename('users', 'users') return flag def get_selected_line(con): """ 获取符合该条件的每一行,并将符合条件的每一行作为一个列表项存储在selected_lst中 :param con: :return: 存储符合条件的行列表 """ # 'age>2' if '>' in con: selected_lst = search_filter_handler('>', con) elif '<' in con: selected_lst = search_filter_handler('<', con) elif '=' in con: selected_lst = search_filter_handler('==', con.replace('=', '==')) elif 'like' in con: selected_lst = search_filter_handler('in', con) return selected_lst def get_show_lst(col_condition): """ 解析传进来的参数得到我们要显示的列名 :param col_condition: 用户输入后解析的条件 :return:列表组成的字典 """ # 'select age,name' col_info_lst = col_condition.split('select') # ['', 'age,name'] col_info = [col_info_item for col_info_item in col_info_lst if col_info_item.strip()] # ['age,name'] if "*" in col_info: # 查询所有信息 return column_dic.keys() # dict_keys(['id', 'name', 'age', 'phone', 'job']) else: ret = col_info[0].split(',') # ['age', 'name'] for i in ret: if i not in column_dic.keys(): # 判断要显示的列的有没有 sys.exit('您输入的查询条件不正确') # return ret # ['age', 'name'] def get_update_info(info): # # 'update name=badkano,age=30' """ :param info: 分解后得到的用户输入的信息:'update name=badkano,age=30' :return: 返回一个列表中含有修改的键值对字典 [{name:badkano},{age:30}] """ hander_lst = [] hander_info = info.split('update')[1].split(',') # ['name=badkano','age=30'] for i in hander_info: hander_lst.append({i.split('=')[0]: i.split('=')[1]}) return hander_lst # [{name:badkano},{age:30}] def update_info(update_con, update_id): """ :param update_con: [{name:badkano},{age:30}] :param update_id: id :return: True or False """ flag = False with open('users', 'r', encoding='utf8') as oldf, open('users', 'w', encoding='utf8') as newf: for line in oldf: if line.strip().split(',')[0] == update_id: # 找到想要修改的 line_lst = line.strip().split(',') # [0, alex, 28, 18765789854, python] for i in update_con: for j in i: line_lst[column_dic[j]] = i[j] line = ','.join(line_lst) flag = True newf.write(line) os.remove('users') os.rename('users', 'users') return flag def show(selected_lst, show_lst): """ 把符合要求的内容显示出来 :param selected_lst: [['1','alex','28','18765789854','python'],[],] :param show_lst: ['age', 'name'] :return: """ if not selected_lst: print('您要查询信息不存在') for i in selected_lst: # [['1','alex','28','18765789854','python'],[],] for j in show_lst: # ['age', 'name'] print(i[column_dic[j]], end=' ') # 把同一个人的信息显示在同一行 print() # 第二个人换一行输出 def file_search(condition): """ 查询语句:select name,age where age>20 :return: """ ret = condition.split('where') # ['selectage,name', 'age>2'] show_lst = get_show_lst(ret[0]) # 'selectage,name' return: ['age', 'name'] selected_lst = get_selected_line(ret[1]) # 'age>2' return: [['1','alex','28','18765789854','python'],[],] show(selected_lst, show_lst) # 在屏幕上打印查出来的结果 def file_del(condition): """ 删除语句:delete where id = 1 ; 是根据员工的id来删除数据的 :return: """ del_id = condition.split('where')[1].replace(' ', '') # 'id=1' ret = del_filter_handler(del_id) # 'id=1' return 删除成功 if ret: print('删除成功') else: print('要删除的员工id不存在') def file_update(condition): """ 修改语句:'update name=badkano,age=30 where id=3' :return: """ update_con = get_update_info(condition.split('where')[0]) # 'update name=badkano,age=30' return:[{name:badkano},{age:30}] update_id = condition.split('where')[1].split('=')[1] # '3' update_ret = update_info(update_con, update_id) if update_ret: print('更新完毕') else: print('没有此员工') def file_create(condition): """ 增加语句: create name,age,phone,job value alex,22,16765879652,linux 如果没有name则显示不能增加,其他值没有为空 :return: """ # {'name':'alex', 'age':'22'} dic = {} lst = [None, None, None, None, None] handle_con = condition.split('value') handle_con[0] = handle_con[0].split('create')[1] handle_key = handle_con[0].split(',') # ['name','age','phone','job'] handle_value = handle_con[1].split(',') # ['alex','22','16765879652','linux'} index = 0 for i in handle_key: dic[i] = handle_value[index] index += 1 # {'name':'alex','age':'22','phone':'16765879652','job':'linux'} files = os.path.getsize('users') with open('users', 'r', encoding='utf8') as oldf, open('newusers', 'w', encoding='utf8') as newf: if files: for line in oldf: id_num = line.strip().split(',')[0] # 得到最后一行的id lst[0] = str(int(id_num)+1) newf.write(line) else: lst[0] = '0' for key in dic: lst[column_dic[key]] = dic[key] lst_ret = ','.join(lst) newf.write(lst_ret + ' ') os.remove('users') os.rename('newusers', 'users') print('您成功增加了一条信息为:', dic) if __name__ == "__main__": while True: condition = input("condition'q'退>>>:").lower().replace(' ', '') # 不区分大小写 "selectname,agewhereage>20" if 'select' in condition and 'where' in condition: file_search(condition) elif 'update' in condition and 'where' in condition: file_update(condition) elif 'create' in condition and 'value' in condition: file_create(condition) elif 'delete' in condition and 'where' in condition: file_del(condition) elif condition == 'q': break else: print('输入不合法')
上面的代码有可能有一些bug,但是基本实现了增删改查的功能。