上篇博客已经说过,会将代码进行优化,并通过TreeMap进行排序实现,现在简单说明一下代码的思路。
项目以上传到github:https://github.com/yandashan/MapReduce_Count2.git
这次的代码是根据课程的id进行排序的,map的流程和普通的WordCount流程差不多,只是实现了在分割数据时对数据的读取和分割功能,然后在reduce上下了一些文章。
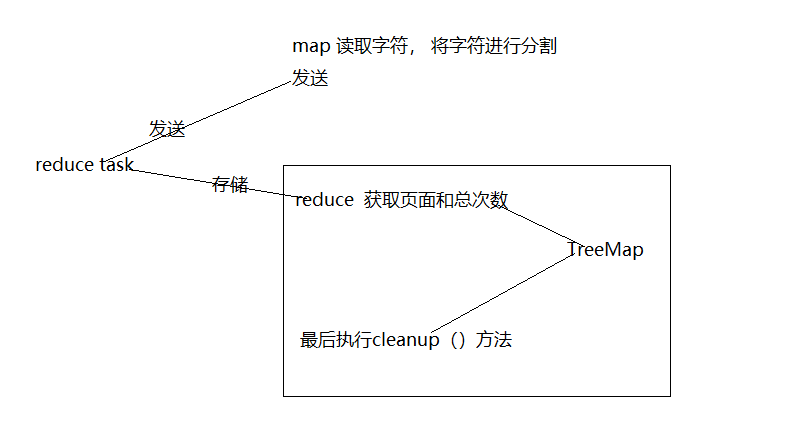
我们知道,在MapReduce执行过程中会执行一个一个Task的方法,用于数据传输过程中的缓存,我们的想法,就是在接收到map传输过来的数据之后,不是立刻输出,而是把它放在一个TreeMap中,实现自动的排序,然后等待Reduce Task将所有map发送过来的数据全部收集完毕后,再执行cleanup方法(cleanup方法使在所有的reduce方法执行完毕之后才开始执行的),我们也就是在cleanup中设置方法,按照一定的要求将数据进行发出。大体流程如下图:
关键代码:
MyReduce:

将value的值进行取出,累加求和,并且封装到PageCount对象中,暂时存储到TreeMap。
cleanup:

在执行job方法时进行动态的设置,然后在job方法中进行设置。
![]()
结果如下图所示;

关于在运行过程中,通过传递不同参数获取输出前几位的值,我们有以下几种方法进行选择。
第一种方法:
按照上面的代码进行操作。
第二种方法:
在运行过程中,向主函数中传递一个值
![]()
右击主函数,选择Run As-》Run Configurations... 在这里输入你要输出的个数。

以上两种方法都是通过代码设置进行的,但是在实际的项目中,我们为了尽量少的更改代码,不能将值写死,所以,我们采用配置文件的方法进行设置。
第三种方法:
创建一个属性配置文件topn.properties,输入 top.n = 10 ,即动态设置top.n的值,在job主方法中写如下代码:
![]()
第四种方法:
通过加载XML文件进行解析。
XML文件中写如下代码:
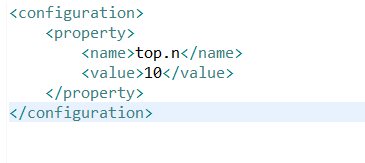
然后加载XML文件:
