是根据页面节点进行定位筛选(多级选择器)。


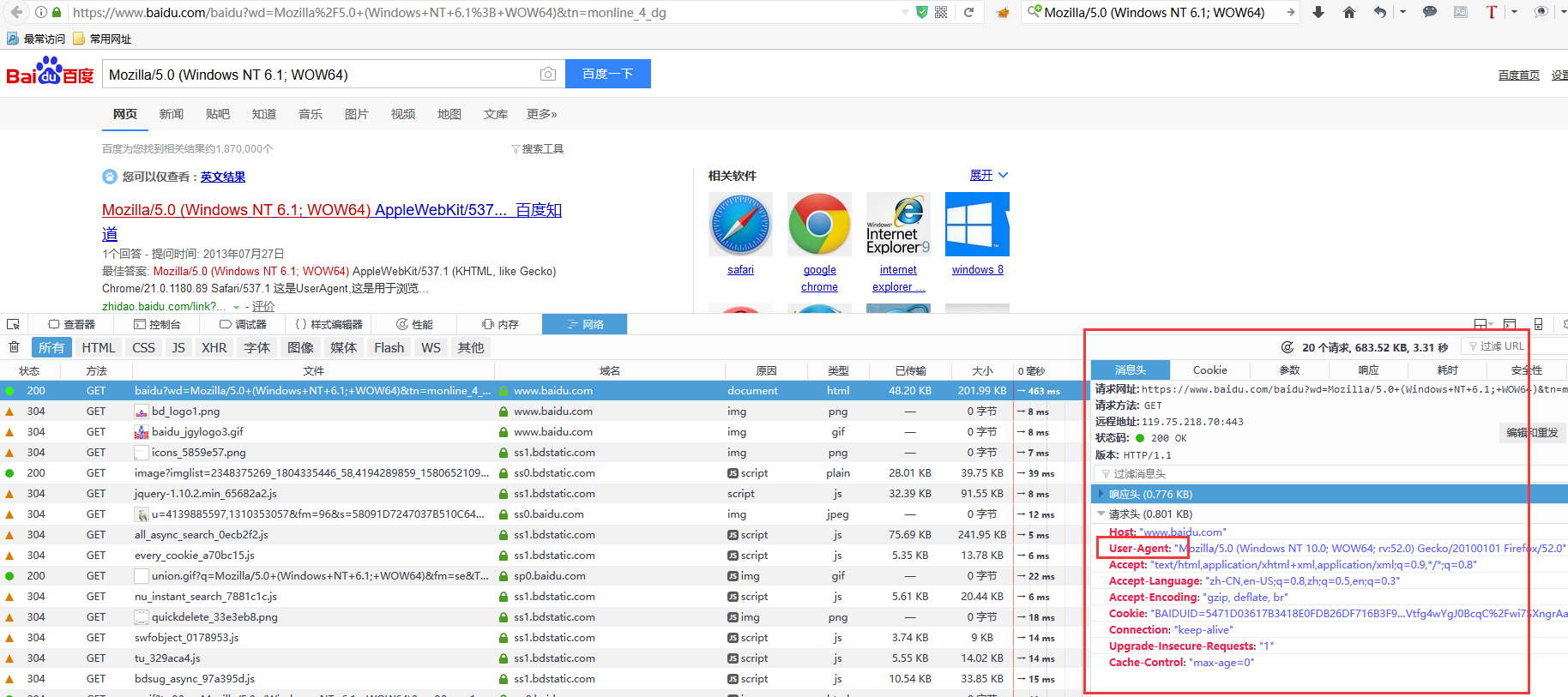
import java.io.IOException; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class TestPreview { public static void main(String[] args) throws IOException { method1(); } private static void method1() throws IOException { //userAgent:例如火狐下打开百度,f12,网络-所有-点击任意一个-右侧出来的请求头的UserAgent Document document = Jsoup .connect("http://www.cnblogs.com/yanan7890/") .timeout(10000) .ignoreContentType(true) .userAgent("Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0") .get(); //System.out.println(document);//获取整篇文档内容 Elements es = document.select("#centercontent > div.day > div.postTitle >a"); Element e = es.get(0);//获取满足条件的所有元素中的第一个标签元素 // 处理标签内容为空时,返回"" String text = e.text(); String html = e.toString(); System.out.println(text);//获取该标签元素的html内容 System.out.println(html);//获取该标签元素 } }