如何构建与选择异常检测算法中的features
如果我的feature像图1所示的那样的正态分布图的话,我们可以很高兴地将它送入异常检测系统中去构建算法。
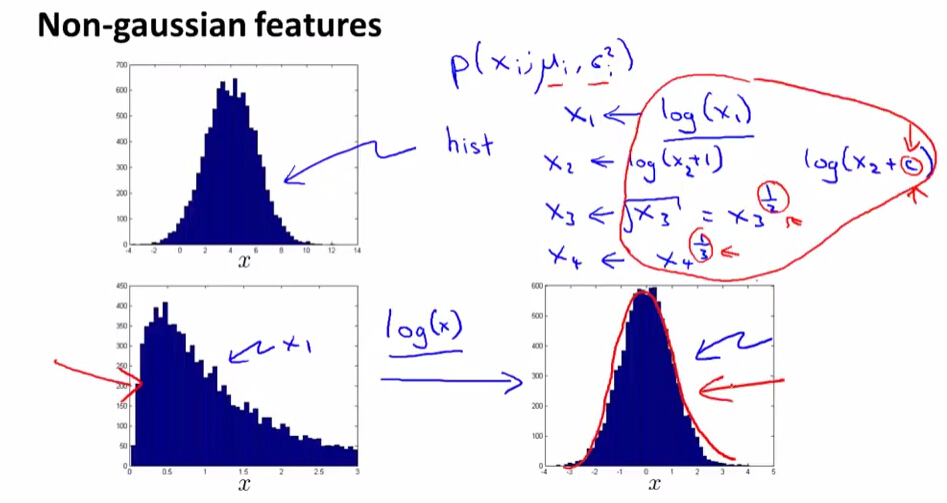
如果我的feature像图2那样不是正态分布的话,虽然我们也可以很好的运行算法,但是我们通常会使用一些转换方法,使数据看下来更像高斯分布,这样算法会工作得更好。
给出上图中下面的这个数据集,可以对其进行一个求对数的转换,这样可以得到一个更像高斯分布的图,这样我们就可以评估出u和σ2了.

在octave里面使用hist来画柱状图,默认是10个柱状,hist(x,50),50个柱条。hist(x.^0.5,50) =>使用x1/2来进行转换,如上图所示。
也可以使用log(x+c),通过调整c来使其更像高斯分布,也可使用x1/2来进行转换等等
所有的这些转换目的是让数据看起来更像高斯分布。
如果画出数据的直方图,发现图形看起来非常不像高斯分布,那么应该进行一些不同的转换,通过这些转换让你的数据看起来更像高斯分布,然后再把数据输入到我们的学习算法中去。
如何得到异常检测算法的特征变量及创建新的feature(误差分析)

通过误差分析,先完整地训练出学习算法,然后在交叉验证集上运行算法,找出那些预测出错的样本,然后看看能否找出一些其它的特征来帮助学习算法,让其在交叉验证时表现更好。
在异常检测系统中,我们希望p(x)的值对于正常样本来说较大,对于异常样本来说是很小的
误差分析的过程:如现在有一个特征x1服从如图所示的正态分布,现在有一个异常样本(绿色所示),它在这个正态分布里面的概率值较大,即我们没有将其分离出来。那么我们看看到底是哪个具体的样本出了问题,通过这个样本来启发我能不能找到一个新的feature来帮助算法来区分出这个不好的样本。即创建一个新的特征x2,有了这个新的特征变量x2我们就能更好地区分出这个异常的样本了。
异常检测算法一些选择features的方法

选择那些可能会取非常非常大的值,或者非常非常小的值的那些features
如在数据中心中我们想监控某台计算机是否出问题了?这时我们可以创建一个新的特征x5=CPU load/network traffic。当机器运行正常时,CPU load与network traffic呈线性的关系。这样当数据中心中的某台机器出了问题时,如被卡住了,这时这台机器的CPU load就会很大,但是network traffic很小,即x5将会非常大,这样我们就可以使用x5来监测机器是否出了问题是否被卡住了。同样也可以创建x6来使用在异常检测算法中。
总结
1>通过对特征进行一些转换来让数据更像正态分布,再将这些特征输入异常检测算法中去
2>误差分析方法来建立新的特征,即找到新的特征将异常样本分开
3>选择那些当出现异常时,值非常非常大或者非常非常小的特征