关键字:string类 字符串 C-风格字符串 C库字符串函数
字符串:存储在内存的连续字节中的一系列字符。
C++处理字符串的方式有两种:
C-风格字符串:由一系列字符组成,以空值字符结尾。
由字符串的定义——存储在连续字节中的一系列字符,我们可以将字符串存储在char数组中,其中每个字符都位于自己的数组元素中。
请对比下面两个字符数组声明:
char dog[8] = {'b', 'e', 'a', 'u', 'x', ' ', 'I', 'I'}; //不是字符串
char cat[8] = {'f', 'a', 't', 'e', 's', 's', 'a', '�'}; //是字符串
上面这两个数组都是char数组,但只有第二个数组是字符串。
空字符对C-风格字符串而言至关重要。例如,C++有很多处理字符串的函数,其中包括cout使用的那些函数。它们都逐个地处理字符串中的字符,直到达到空字符为止。如果使用cout显示上面的cat这样的字符串,则将显示前7个字符,发现空字符后停止。但是,如果使用cout显示上面的dog数组(它不是字符串),cout将打印出数组中的8个字母,并接着将内存中随后的各个字节解释为要打印的字符,直到遇到空字符为止。由于空字符(实际上是被设置为0的字节)在内存中很常见,因此这一过程将很快停止。但尽管如此,还是不应将不是字符串的字符数组当作字符串来处理。
在cat数组示例中,这是一个冗长乏味的将数组初始化为字符串的工作,我们接下来介绍另一种将字符数组初始化为字符串的方法——只需使用一个用引号括起的字符串即可,这种字符串被称为字符串常量:
char bird[11] = "Mr. Cheeps"; //空字符'�'隐式的被包括在字符串常量内 char fish[] = "Bubbles"; //让编译器自己计算char数组长度
用引号括起的字符串隐式地包括结尾的空字符,因此不要显式地包括它。此外,各种C++输入工具通过键盘输入,将字符串读入到char数组中,将自动加上结尾的空字符。
C-风格字符串与常规char数组之间的一个重要区别:字符串有内置的结束字符,而char数组只有以空值字符结尾才是字符串。
一个keypoint是应确保数组足够大,能够存储字符串中所有字符——包括空字符,所以使用字符串常量初始化字符数组时让编译器计算元素数目更为安全。
接下来,我们探讨为什么字符串常量"S"与字符常量'S'为何不能互换:
- 字符常量是字符串编码的简写表示,在ASCII系统上,'S'只是83的另一种写法;
- "S"不是字符常量,它表示的是两个字符(字符S和�)组成的字符串,此外,"S"实际上表示的是字符串所在的内存地址。
上面都是C-风格字符串的常规使用,接下来,我们将探讨一下C库字符串函数。
现在我们想知道字符数组word中的字符串是不是mate,将测试代码写成如下形式:
word == "mate"
数组名word是数组的地址,字符串常量也是"mate"的地址。因此,上面的关系表达式不是判断两个字符串是否相同,而是查看它们是否存储在相同的地址上。
由于C++将C-风格字符串视为地址,因此如果使用关系运算符来比较它们,将无法得到满意的结果。
此时,我们就应该使用C-风格字符串库中的strcmp()函数来比较。该函数接受两个字符串地址作为参数,这意味着参数可以是指针、字符串常量或字符数组名。
下面是示例程序:


1 // compstr1.cpp -- comparing strings using arrays 2 #include <iostream> 3 #include <cstring> // prototype for strcmp() 4 int main() 5 { 6 using namespace std; 7 char word[5] = "?ate"; 8 9 for (char ch = 'a'; strcmp(word, "mate"); ch++) 10 { 11 cout << word << endl; 12 word[0] = ch; 13 } 14 cout << "After loop ends, word is " << word << endl; 15 return 0; 16 }
显然,用字符数组存储字符串,不论是在初始化(要考虑数组大小、以'�'结尾)方面,或是在处理(比较strcmp、计算长度strlen、连接strcat)字符串方面都极其繁琐,下面讲的C++新增的string类极大简化了对字符串的操作。
最后,我们补充一下函数和C-风格字符串的知识点。
假设要将字符串作为参数传递给函数,则表示字符串的方式有三种:
- char数组;
- 用引号括起的字符串常量;
- 被设置为字符串的地址的char指针。
但上述3种选择的类型都是char指针(准确地说是char*),因此可以将其作为字符串处理函数的参数:
char ghost[15] = "galloping";
char *str = "galumphing";
int n1 = strlen(ghost);
int n2 = strlen(str);
int n3 = strlen("gamboling");
我们认为是将字符串作为参数来传递,但实际传递的是字符串第一个字符的地址。这意味着字符串函数原型应将其表示字符串的形参声明为char*类型。
假设要编写一个返回字符串的函数。我们知道函数无法返回一个字符串,但可以返回字符串的地址,这样做的效率更高。
下面是一个这样的程序:它定义了一个名为buildstr()的函数,该函数返回一个指针。该函数接受两个参数:一个字符和一个数字。函数使用new创建一个长度与数字参数相等的字符串,然后将每个元素都初始化为该字符。然后,返回指向新字符串的指针。
1 // strgback.cpp -- a function that returns a pointer to char 2 #include <iostream> 3 char * buildstr(char c, int n); // prototype 4 int main() 5 { 6 using namespace std; 7 int times; 8 char ch; 9 10 cout << "Enter a character: "; 11 cin >> ch; 12 cout << "Enter an integer: "; 13 cin >> times; 14 char *ps = buildstr(ch, times); 15 cout << ps << endl; 16 delete [] ps; // free memory 17 ps = buildstr('+', 20); // reuse pointer 18 cout << ps << "-DONE-" << ps << endl; 19 delete [] ps; // free memory 20 return 0; 21 } 22 23 // builds string made of n c characters 24 char * buildstr(char c, int n) 25 { 26 char * pstr = new char[n + 1]; 27 pstr[n] = '�'; // terminate string 28 while (n-- > 0) 29 pstr[n] = c; // fill rest of string 30 return pstr; 31 }
string类:ISO/ANSI C++98标准通过添加string类扩展了C++库,因此可以使用string类的对象来存储字符串。
string作为一个类,将许多字符串的操作进行封装,使得我们能够像处理普通变量那样处理字符串。
下面,我们先比较一下string对象与字符数组:
1 // strtype1.cpp -- using the C++ string class 2 #include <iostream> 3 #include <string> // make string class available 4 int main() 5 { 6 using namespace std; 7 char charr1[20]; // create an empty array 8 char charr2[20] = "jaguar"; // create an initialized array 9 string str1; // create an empty string object 10 string str2 = "panther"; // create an initialized string 11 12 cout << "Enter a kind of feline: "; 13 cin >> charr1; 14 cout << "Enter another kind of feline: "; 15 cin >> str1; // use cin for input 16 cout << "Here are some felines: "; 17 cout << charr1 << " " << charr2 << " " 18 << str1 << " " << str2 // use cout for output 19 << endl; 20 cout << "The third letter in " << charr2 << " is " 21 << charr2[2] << endl; 22 cout << "The third letter in " << str2 << " is " 23 << str2[2] << endl; // use array notation 24 25 return 0; 26 }
从这个例子中,我们可以得出string对象与字符数组之间的相同点:
- 可以使用C-风格字符串来初始化string对象;
- 可以使用cin来将键盘输入存储到string对象中;
- 可以使用cout来显示string对象;
- 可以使用数组表示法来访问存储在string对象中的字符。
而不同点则是:可以将string对象声明为简单变量,而不是数组。
string类的类设计还能让程序自动处理string对象的大小:
例如,ss的声明创建一个长度为0的string对象,但程序将输入读取到ss中,将自动调整ss的长度。 string ss; cin >> ss;
上面都是引导我们迈入string类的大门,下面我们从类的角度来看string类。
首先是string类的构造函数:
string类有9个构造函数,也就是说我们有9种方式初始化string对象。

下面这个程序我们使用了string的7个构造函数,请结合上面的表仔细揣摩:
1 #include <iostream> 2 #include <string> 3 // using string constructors 4 5 int main() 6 { 7 using namespace std; 8 string one("Lottery Winner!"); // ctor #1 9 cout << one << endl; // overloaded << 10 string two(20, '$'); // ctor #2 11 cout << two << endl; 12 string three(one); // ctor #3 13 cout << three << endl; 14 one += " Oops!"; // overloaded += 15 cout << one << endl; 16 two = "Sorry! That was "; 17 three[0] = 'P'; 18 string four; // ctor #4 19 four = two + three; // overloaded +, = 20 cout << four << endl; 21 char alls[] = "All's well that ends well"; 22 string five(alls,20); // ctor #5 23 cout << five << "! "; 24 string six(alls+6, alls + 10); // ctor #6 25 cout << six << ", "; 26 string seven(&five[6], &five[10]); // ctor #6 again 27 cout << seven << "... "; 28 string eight(four, 7, 16); // ctor #7 29 cout << eight << " in motion!" << endl; 30 return 0; 31 }
分析构造函数:
- 将string对象初始化为常规的C-风格字符串,然后使用重载的<<运算符来显示它:
string one("Lottery Winner!"); // ctor #1 cout << one << endl; // overloaded << - 将string对象two初始化为由20个$字符组成的字符串:
string two(20, '$'); // ctor #2
- 复制构造函数将string对象three初始化为string对象one:
string three(one); // ctor #3
- 默认构造函数创建一个以后可以对其进行赋值的空字符串:
string four; // ctor #4 four = two + three; // overloaded +, =
- 将一个C-风格字符串和一个整数作为参数,其中的整数参数表示要复制多少个字符:
char alls[] = "All's well that ends well"; string five(alls,20); // ctor #5
- 第六个构造函数有一个模板参数:
template<class Iter> string(Iter begin, Iter end); //模板参数 string six(alls+6, alls + 10); // ctor #6
- 将一个string对象的部分内容复制到构造的对象中:
string eight(four, 7, 16); // ctor #7
上面这个程序中,我们还进行了运算符重载,以更灵活地使用字符串。
其中,重载+=运算符:它将一个字符串附加到另一个字符串的后面;重载=运算符:将一个字符串赋给另一个字符串;重载<<运算符:用于显示string对象;重载[]运算符:用于访问字符串中的各个字符。
接来下,我们就看看string类是怎么处理字符串的吧!
(1)比较字符串
string类对全部6个关系运算符都进行了重载。如果在机器排列序列中,一个对象位于另一个对象的前面,则前者被视为小于后者。如果机器排列序列为ASCII码,则有数字字符<大写字符<小写字符。对于每个关系运算符,都以三种方式被重载,以便能够将string对象与另一个string对象、C-风格字符串进行比较,并能够将C-风格字符串与string对象进行比较:
string snake1("cobra");
string snake2("cora1");
char snake3[20] = "clearlove7";
if(snake1 < snake2) //operator<(const string &, cosnt string &)
...
if(snake1 == snake2) //operator==(const string &, const char *)
...
if(snake3 != snake2) //operator!=(const char *, const string &)
...
(2)获取字符串的长度
size()和length()成员函数都返回字符串中的字符数:
string snake1("cobra");
string snake2("cora1");
if(snake1.length() == snake2.size())
cout<<"Both strings have the same length.
";
(3)在字符串中搜索给定的子字符串或字符
首先是4个重载的find()方法:
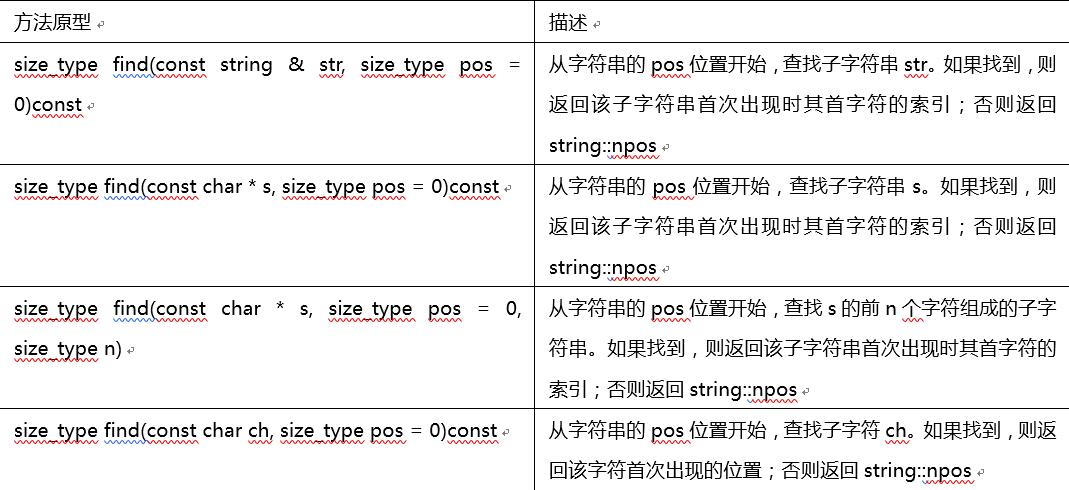
string库还提供了相关的方法:rfind()、find_first_of()、find_last_of()、find_first_not_of()和find_last_not_of(),它们的重载函数特征标都与find()方法相同。
- rfind()方法:查找子字符串或字符最后一次出现的位置。
- find_first_of()方法:在字符串中查找参数中任何一个字符首次出现的位置。如下面的语句将返回r在"cobra"中的位置(即索引3),因为这是"hark"中各个字母在"cobra"首次出现的位置:
int where = snake1.find_first_of("hark"); - find_last_of()方法的功能与此相同,只是它寻找的是最后一次出现的位置。因此下面的语句返回a在"cobra"中的位置:
int where = snake1.find_last_of("hark"); - find_first_not_of()方法在字符串中查找第一个不包含参数中的字符,因此下面的语句返回c在"cobra"中的位置,因为"hark"中没有c:
int where = snake1.find_first_not_of("hark");
还有很多其他的方法,这些方法足以创建一个非图形版本的Hangman拼字游戏。该游戏将一系列的单词存储在一个string对象数组中,然后随机选择一个单词,让人猜测单词的字母。如果猜错6次,玩家就输了。该程序使用find()函数来检查玩家的猜测,使用+=运算符创建一个string对象来记录玩家的错误猜测。为记录玩家猜对的情况,程序创建了一个单词,其长度与被猜的单词相同,但包含的是连字符。玩家猜对字符时,将用该字符替换相应的连字符。下面是该程序的代码:
1 // hangman.cpp -- some string methods 2 #include <iostream> 3 #include <string> 4 #include <cstdlib> 5 #include <ctime> 6 #include <cctype> 7 using std::string; 8 const int NUM = 26; 9 const string wordlist[NUM] = {"apiary", "beetle", "cereal", 10 "danger", "ensign", "florid", "garage", "health", "insult", 11 "jackal", "keeper", "loaner", "manage", "nonce", "onset", 12 "plaid", "quilt", "remote", "stolid", "train", "useful", 13 "valid", "whence", "xenon", "yearn", "zippy"}; 14 15 int main() 16 { 17 using std::cout; 18 using std::cin; 19 using std::tolower; 20 using std::endl; 21 22 std::srand(std::time(0)); 23 char play; 24 cout << "Will you play a word game? <y/n> "; 25 cin >> play; 26 play = tolower(play); 27 while (play == 'y') 28 { 29 string target = wordlist[std::rand() % NUM]; 30 int length = target.length(); 31 string attempt(length, '-'); 32 string badchars; 33 int guesses = 6; 34 cout << "Guess my secret word. It has " << length 35 << " letters, and you guess " 36 << "one letter at a time. You get " << guesses 37 << " wrong guesses. "; 38 cout << "Your word: " << attempt << endl; 39 while (guesses > 0 && attempt != target) 40 { 41 char letter; 42 cout << "Guess a letter: "; 43 cin >> letter; 44 if (badchars.find(letter) != string::npos 45 || attempt.find(letter) != string::npos) 46 { 47 cout << "You already guessed that. Try again. "; 48 continue; 49 } 50 int loc = target.find(letter); 51 if (loc == string::npos) 52 { 53 cout << "Oh, bad guess! "; 54 --guesses; 55 badchars += letter; // add to string 56 } 57 else 58 { 59 cout << "Good guess! "; 60 attempt[loc]=letter; 61 // check if letter appears again 62 loc = target.find(letter, loc + 1); 63 while (loc != string::npos) 64 { 65 attempt[loc]=letter; 66 loc = target.find(letter, loc + 1); 67 } 68 } 69 cout << "Your word: " << attempt << endl; 70 if (attempt != target) 71 { 72 if (badchars.length() > 0) 73 cout << "Bad choices: " << badchars << endl; 74 cout << guesses << " bad guesses left "; 75 } 76 } 77 if (guesses > 0) 78 cout << "That's right! "; 79 else 80 cout << "Sorry, the word is " << target << ". "; 81 82 cout << "Will you play another? <y/n> "; 83 cin >> play; 84 play = tolower(play); 85 } 86 87 cout << "Bye "; 88 89 return 0; 90 }
该程序使用find()来检查玩家以前是否猜过某个字符。如果是,则它要么位于badchars字符串(猜错)中,要么位于attempt字符串(猜对)中:
if (badchars.find(letter) != string::npos || attempt.find(letter) != string::npos)
npos变量是string类的静态成员,它的值是string对象能存储的最大字符数。由于索引从0开始,所以它比最大的索引值大1,因此可以使用它来表示没有查找到字符或字符串。
该程序的核心是从检查玩家选择的字符是否位于被猜测的单词中开始的:
int loc = target.find(letter);
如果loc是一个有效的值,则可以将该字母放置在答案字符串的相应位置:
attempt[loc] = letter;
然而,由于字母在被猜测的单词中可能出现多次,所以程序必须一直进行检查。该程序使用了find()的第二个可选参数,该参数可以指定从字符串什么位置开始搜索。因为字母是在位置loc找到的,所以下一次搜索应从loc+1开始。while循环使搜索一直进行下去,直到找不到该字符为止。如果loc位于字符串尾,则表明find()没有找到该字符。
loc = target.find(letter, loc + 1);
while (loc != string::npos){
attempt[loc]=letter;
loc = target.find(letter, loc + 1);
}
(4)其他功能
string库还提供了很多其他的工具,包括完成下列功能的函数:
- 删除字符串的部分或全部内容;
- 用一个字符串的部分或全部内容替换另一个字符串的部分或全部内容;
- 将数据插入到字符串中或删除字符串中的数据;
- 将一个字符串的部分或全部内容与另一个字符串的部分或全部内容进行比较;
- 从字符串中提取子字符串;
- 将一个字符串中的内容复制到另一个字符串中;
- 交换两个字符串的内容。
这些函数中的大多数都被重载,以便能够同时处理C-风格字符串和string对象。我们将在附录中介绍string库中的函数。
首先来看自动调整大小的功能。在下面这段程序中,每当程序将一个字母附加到字符串末尾时将发生什么呢?不能仅仅将已有的字符串加大,因为相邻的内存可能被占用了。因此,可能需要分配一个新的内存块,并将原来的内容复制到新的内存单元中。如果执行大量这样的操作,效率将非常低,因此很多C++实现分配一个比实际字符串大的内存块,为字符串提供了增大空间。然而,如果字符串不断扩大,超过了内存块的大小,程序将分配一个大小为原来两倍的新内存块,以提供足够的增大空间,避免不断地分配新的内存块。方法capacity()返回当前分配给字符串的内存块大小,而reserve()方法让我们能够请求内存块的最小长度。
1 // str2.cpp -- capacity() and reserve() 2 #include <iostream> 3 #include <string> 4 int main() 5 { 6 using namespace std; 7 string empty; 8 string small = "bit"; 9 string larger = "Elephants are a girl's best friend"; 10 cout << "Sizes: "; 11 cout << " empty: " << empty.size() << endl; 12 cout << " small: " << small.size() << endl; 13 cout << " larger: " << larger.size() << endl; 14 cout << "Capacities: "; 15 cout << " empty: " << empty.capacity() << endl; 16 cout << " small: " << small.capacity() << endl; 17 cout << " larger: " << larger.capacity() << endl; 18 empty.reserve(50); 19 cout << "Capacity after empty.reserve(50): " 20 << empty.capacity() << endl; 21 return 0; 22 }
【字符串输入输出】
上面我们学习了C-风格字符串和string类两种处理字符串的手段,但仅仅是手段,不知道它们如何是如何将字符串正确输入到程序中都只是纸上谈兵。所以,下面我们将学习字符串的输入输出处理(先C-风格字符串,再string类),这也是这一讲的尾声了。
【C-风格字符串的输入输出】
使用cin输入:
【知识点提要】
cin使用空白(空格、制表符和换行符)来确定字符串的结束位置,这意味着cin在获取字符数组输入时只读取一个单词。读取该单词后,cin将该字符串放到数组中,并自动在结尾添加空字符。
- 要输入的字符串不能含有空格,即每次只能读取一个单词;
- 不能避免“输入的字符串比目标字符数组长”这种情况发生。
每次读取一行字符串输入:
【知识点提要】
istream中的类(如cin)提供了一些面向行的类成员函数:getline()和get()。这两个函数都读取一行输入,知道到达换行符。然而,随后getline()将丢弃换行符,而get()将换行符保留在输入序列中。
【getline()】
getline()函数读取整行,它通过使用回车键输入的换行符来确定输入结尾,并将换行符替换为空字符。
调用方法:cin.getline()
该函数有两个参数,第一个参数是用来存储输入行的数组的名称,第二个参数是要读取的字符数(如果这个参数为5,则函数最多读取4个字符,余下的空间用于存储自动在结尾处添加的空字符)。getline()成员函数在读取指定数目的字符或遇到换行符时停止读取。
提示:getline()成员函数还可接受第三个可选参数,这将在后面的输入输出专栏中提及。
【get()】
该函数有几种变体(也称函数重载)。
其中一种变体的工作方式与getline()类似——接受的参数相同,解释参数的方式也相同,并且都读取到行尾。但get并不再读取并丢弃换行符,而是将其留在输入队列中。这将导致一个问题。
假设我们连续两次调用get():
cin.get(name, Arsize); cin.get(dessert, Arsize); //a problem
由于第一次调用后,换行符将留在输入队列中,因此第二次调用时看到的第一个字符便是换行符。因此get()认为已到达行尾,而没有发现任何可读取的内容。如果不借助于帮助,get()将不能跨过该换行符。
幸运的是,get()有另一种变体。使用不带参数的cin.get()调用可读取下一个字符(即使是换行符),因此可以用它来处理换行符,为读取下一行输入做好准备:
cin.get(name, Arsize); //读第一行 cin.get(); //读取换行符 cin.get(dessert, Arsize); //读第二行
另一种使用get()的方式是将两个类成员函数拼接起来:
cin.get(name, Arsize).get(); //连结成员函数
之所以可以这样做,是由于cin.get(name, Arsize)返回一个cin对象,该对象随后将被用来调用get()函数。同样,下面的语句将把输入中连续的两行分别读入到数组name1和name2中,其效果与两次调用cin.getline()相同:
cin.getline(name1, Arsize).getline(name2, Arsize);
上面两种get()函数中,如果使用的是cin.get(name, Arsize),则编译器知道是要将一个字符串放入数组中,因而将使用适当的成员函数;如果使用的是cin.get(),则编译器知道是要读取一个字符。
【小结】
为什么要使用get(),而不只使用getline()呢?
因为get()使输入更仔细。例如,假设用get()将一行读入数组中,如何知道停止读取的原因是由于已经读取了整行,而不是由于数组已填满呢?我们可以查看下一个输入字符,如果是换行符,说明已读取了整行;否则说明该行中还有其他输入。
总之,getline()使用起来简单一些,但get()使得检查错误更简单些。可以使用其中任何一个来读取一行输入,只要知道它们的行为稍有不同。
【空行和其他问题】
当get()读取空行后,将设置失效位——接下来的输入将被阻断,但可以用下面的命令来恢复输入:
cin.clear();
此外,输入字符串比分配的空间长时,那么getline()和get()将把余下的字符留在输入队列中,而getline()还会设置失效位。
混合输入数字和字符串:
混合输入数字和面向行的字符串会导致问题:
// numstr.cpp -- following number input with line input
#include <iostream>
int main()
{
using namespace std;
cout << "What year was your house built?
";
int year;
cin >> year;
// cin.get();
cout << "What is its street address?
";
char address[80];
cin.getline(address, 80);
cout << "Year built: " << year << endl;
cout << "Address: " << address << endl;
cout << "Done!
";
// cin.get();
return 0;
}
我们根本没有输入地址的机会。问题在于,当cin读取年份,将回车键生成的换行符留在了输入队列中。后面的cin.getline()看到换行符后,将认为是一个空行,并将一个空字符串赋给address数组。
解决方法是,在读取地址之前先读取并丢弃换行符——使用没有参数的get()或使用接受一个char参数的get():
cin>>year; cin.get(); //或 cin.get(ch);
也可以利用表达式cin>>year返回cin对象,将调用拼接起来:
(cin>>year).get(); //或 (cin>>year).get(ch);
【string类的输入输出】
使用cin>>将输入存储到string对象中(使用cout<<来显示string对象),句法与处理C-风格字符串相同(读取一个单词);但每次读取一行(而不是一个单词)时,使用的句法不同。
1 // strtype4.cpp -- line input 2 #include <iostream> 3 #include <string> // make string class available 4 #include <cstring> // C-style string library 5 int main() 6 { 7 using namespace std; 8 char charr[20]; 9 string str; 10 11 cout << "Length of string in charr before input: " 12 << strlen(charr) << endl; 13 cout << "Length of string in str before input: " 14 << str.size() << endl; 15 cout << "Enter a line of text: "; 16 cin.getline(charr, 20); // indicate maximum length 17 cout << "You entered: " << charr << endl; 18 cout << "Enter another line of text: "; 19 getline(cin, str); // cin now an argument; no length specifier 20 cout << "You entered: " << str << endl; 21 cout << "Length of string in charr after input: " 22 << strlen(charr) << endl; 23 cout << "Length of string in str after input: " 24 << str.size() << endl; 25 26 return 0; 27 }
在上述程序中:
- 将一行输入读取到数组中的代码:
cin.getline(charr, 20); //读取一行,丢弃' '
- 将一行输入读取到string对象中的代码:
getline(cin, str); //读取一行,丢弃' '
读取到数组中的代码(句点表示法)表明——函数getline()是istream类的一个成员函数;而读取到string对象中的代码(没有使用句点表示法)表明——getline()不是类方法,它将cin作为参数,指出到哪里去查找输入。另外,也没有指出字符串长度的参数,因为string对象将根据字符串的长度自动调整自己的大小。即,读取C-风格字符串的函数是istream类的方法,而string版本是独立的函数(因为早期istream类中只有处理基本数据类型的成员函数)。这就是对于C-风格字符串输入,cin是调用对象;而对于string对象输入,cin是一个函数参数的原因。
上面提及的规则也适用于>>形式,我们用函数形式来编写代码:
cin.operator>>(fname); //ostream类方法 operator>>(cin, lname); //常规函数
下面我们将更深入地探讨一下string输入函数。虽然前面提及的string输入函数都能自动调整目标string的大小,使之与输入匹配,但也存在一些限制。第一个限制因素是string对象的最大允许长度,由常量string::npos指定(这通常是最大的unsigned int值),因此对于普通的交互式输入,这不会带来实际的限制;但如果我们试图将整个文件的内容读取到单个string对象中,这可能称为限制因素。第二个限制因素是程序可以使用的内存量。
string版本的getline()函数从输入中读取字符,并将其存储到目标string中,直到发生下列三种情况之一:
- 到文件尾,在这种情况下,输入流的eofbit将被设置,这意味着方法fail()和eof()都将返回true;
- 遇到分界字符(默认为 ),在这种情况下,将把分界字符从输入流中删除,但不存储它;
- 读取的字符数达到最大允许值(string::npos和可供分配的内存字节数中较小的一个),在这种情况下,将设置输入流的failbit,这意味着方法fail()将返回true。
输入流对象有一个统计系统,用于跟踪流的错误状态。在这个系统中,检测到文件尾后将设置eofbit寄存器,检测到输入错误时将设置failbit寄存器,出现无法识别的故障(如硬盘故障)时将设置badbit寄存器,一切顺利时将设置goodbit寄存器。
【附录——模板类string】
学完C++后将补充!!!