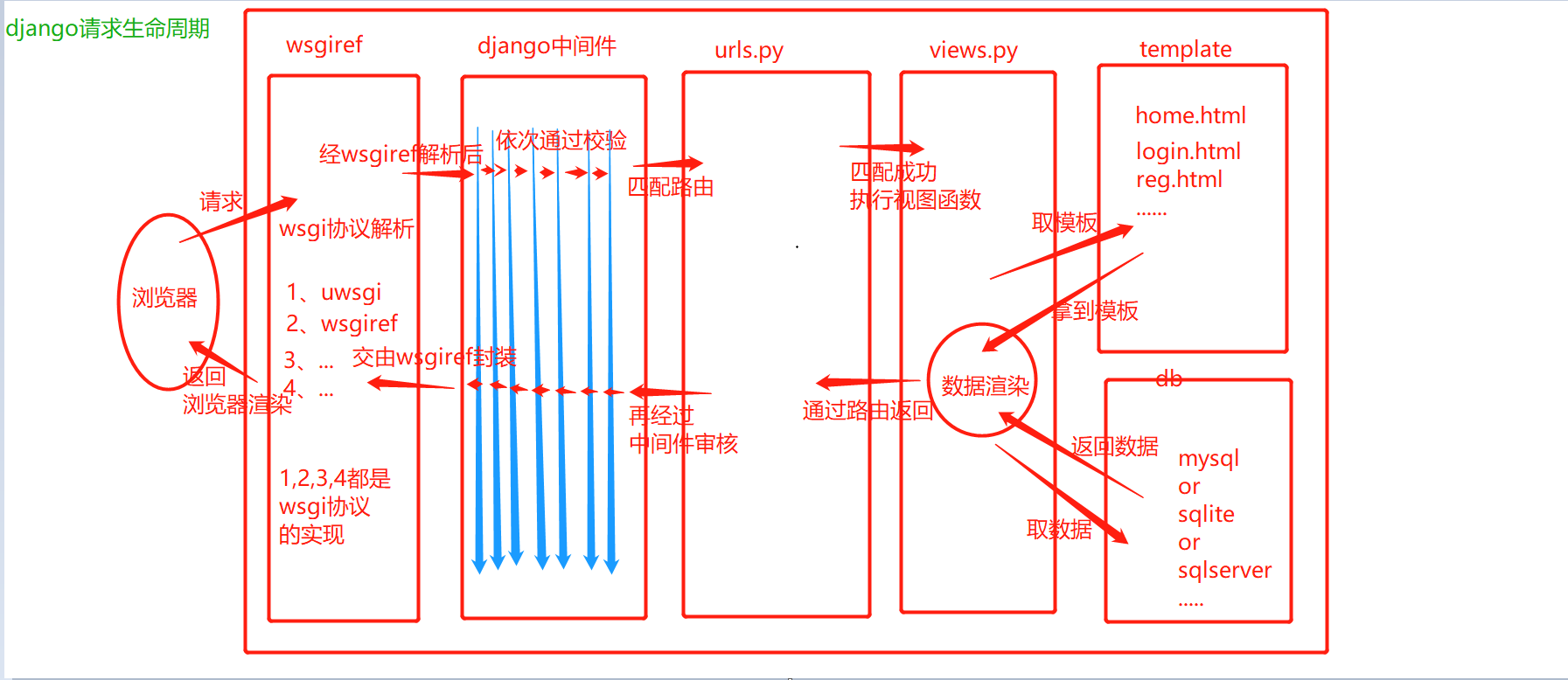
在将之前我们先了解下Django的生命周期
HTTP的特性:
3.响应式请求
4.基于TCP/IP协议的通信
1.无连接
2.无状态
请求头和响应头格式
GET / HTTP/1.1 请求方法 URI协议/版本)
Host: 127.0.0.1:8080 请求头 Connection: keep-alive Cache-Control: max-age=0 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3 Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9
请求正文
Cookie: csrftoken=BVl9QoBxGV27jR4b5UPstnYeouwhPZV5ZoC19VIpL3Tec0pCjrJ1vY24wBqyHNJo; sessionid=llct2t0wzkll4t8yulyzuzc42epuqoms
l 协议/版本 状态码 描述
l 响应头(Response Header)
l 响应正文
WSIGI和cgi 和WSGIREF
前者是WSGI web服务网关协议
后者是 通用网关协议
CGI在web服务器与应用充当交互作用,这样才能处理用户表单生成并返回最终html页面
一般来说含有用户输出的 submit 图片的web 都会涉及某个CGI活动
不过现在生产环境的web页面都不再使用CGI了
原因 有明显限制性 限制服务器同时处理客户端的数量
WSGI 不是服务器 不是与程序交互的API 也不是代码 只是定义了一个接口 一种规范
用于处理日益增多的不同web框架 web服务 减少互操作性
wsgiref:django 基于WSGI协议开发的模块简单服务器
像sockerserver一样调用 内部遵守了WSGI协议的模块
开发模式
前后端分离
微服务 通过ngix 把请求转接到具体服务器
前后端分离后:cookie就使用不了了
前端发送ajax请求 后端拿到数据给你一个接口状态吗101 请跳转 还是干嘛,数据有什么 这有一种规范 今天我要讲
前后端不分离
前端人员把页面的空盒子写好后给我 我把往空缺的地方通过DTL填数据
CBV执行流程源码分析
CBV请求
通过中间件请求路由会执行 as_view()的返回结果(返回结果之前做了一件事 往view名称空间添加view_class这个类,view_initkwargs=参数)
请求来了执行view 最后调用 自己dispathch方法
dispathch 判断请求的方法字符串是否在 请求方法列表里 最后返回执行的结果(get还是post)也就是自己写的


路由如果这么配置:url(r'^test/', views.Test.as_view()), 请求通过中间件后进入路由--->根据路由匹配,一旦成功,会执行后面函数(request)---》本质就是执行了as_view内部的view函数----》内部又调用了self.dispatch---->根据请求方式,执行不同的方法(必然get请求,就会执行咱么写的视图类的get方法) 尝试自己封装一个APIView,重写dispatch方法,在执行父类的dispatch之前,写一些逻辑,请求来了,就会执行这些逻辑
Restful
Restful规范
restful无非就是把想要的数据通过逻辑判断 返回一个Json 没有什么特别的,在正式看源码之前先大致了解一下RestFult规范
1.必须是https 协议
2.有规定url xxx域名/api
-https://api.example.com
-https://example.org/api/
3.版本规范
-可以放在路径中
-可以放在请求头中
4.所有的资源都是名词
5.请求方式均在method里
6.筛选有过滤调节
7.有状态吗
8.错误信息
9.返回结果有信息
10.返回结果提供链接
django 中restful 安装
1.pip3 install djangorestframework
2.注册app
INSTALLED_APPS= [
'rest_framework'
]
3.继承
from rest_framework import APIView
class Books(APIView): def get(self,request): return HttpResponse({"reg":"ok"})
源码分析
继承了APIView 之后: -1 所有的请求都没有csrf的认证了 -2 在APIView中as_view本质还是调用了父类的as_view(View的as_view) -3 as_view中调用dispatch -----》这个dispatch是APIView的dispatch -APIVIew的dispatch方法: -1 对原生request对象做了一层包装(面向对象的封装),以后再用的request对象都新的request对象 -2 在APIView中self.initial(request, *args, **kwargs),里面有频率控制,权限控制和认证相关 -3 根据请求方法执行咱们写的视图类中的相应方法 --视图类中方法的request对象,已经变成了封装后的request -Request类: -1 原生的request是self._request -2 取以post形式提交的数据,从request.data中取(urlencoded,formdata,json格式) -3 query_params 就是原生request的GET的数据 -4 上传的文件是从FILES中取 -5 (重点)其他的属性,直接request.属性名(因为重写了__getattr__方法)
psotman的安装和使用
模拟向接口发送请求,测试接口
api的测试工具
初探restful
一般来说restful会把自己的要的数据在url请求中表示 域名:端口/资源_1/API。
拿的话通过ajax 发送GET请求 添加:post 删除:DELETE 修改:PUT (完整资源) PATCH(属性)
序列化组件
在后端返回数据给前端中,需要将查询出来的对象转为字符串的字典(jaon) 再返回给前端
但是这样手动的去取出来通过循环拼成一个个字典扩展性较差,功能不够多样,那django就自带了一个自动帮我们序列化的组件
我们无需自己去实现功能
概要:request.post是一个不可修改的QueryDict 版本放在请求头里怎么取出?通过meta?
不要使用django.core import serializers
teg=serializers.serialize("json",article_list) #什么格式,被序列话对象
结果[{"model": "app02.site", "pk": 1, "fields": {"title": "30u5c81u8d85u8d8a", "theme": "static/theme/85d3bc014a90f60394f557af3412b31bb151ed67.jpg"}}] 扩展差
在rest_framework中 也有个render方法会根据是否是浏览器返回一个特殊网页,如果是非浏览器那么返回一个json字符串
在实例化序列化类时,如果many=True
instanc是实例化对象,data是传过来的字典
序列化组件

#1.继承了Serializer的类
from rest_framework.serializers import Serializer
from rest_framework import serializers
class Books(Serializer): #进行序列化的类
title=serializers.CharField() price=serializers.IntegerField()
class X(APIView): def get(self,request): response={"reg":"101","msg":"成功"} book_list=models.Book.objects.all() bookser=asda.Books(instance=book_list,many=True) response["data"]=bookser.data print(response) return Response(response)
但是这里序列化的字段变量必须和模型(orm)字段同名否则会异常
前端拿到一个name5 其实不是我数据库的name5 我们在序列化的时候转换了一下提高了数据库安全性,且提供给前端一个名字,我们去对应我们的数据库
序列化的时候需要自己定义保存方法
class MySerializer(Serializer):
title=serializers.CharField()
price=serializers.CharField()
def create(self, validated_data):
print(validated_data)
models.Book.objects.create(**validated_data)
pass
from django.http import JsonResponse
class BookSerializer(APIView):
def post(self,request):
obj=MySerializer(data=request.data)
if obj.is_valid():
obj.create(obj.validated_data)
else :
return HttpResponse("Bad")
return HttpResponse("OK")
给前端访问的起个别名 指代数据库一个数据
from rest_framework.response import Response
#title5=serializers.CharField(source="title") #给前端用title5 前端用title5访问的时候其实也是title
#还能跨表查 比如图书的作者是个外键的话 那么你序列化拿到的是作者id 那么如果想要名字呢?
author=serializers.CharField(source="author.name")
如果一对多 是个列表的话?
可以把查询出来的query_set 序列化最终把字典返回
方法必须是 get_字段 第一个obj 是类对象
author_info=serializers.SerializerMethodField(read_only=True) def get_author_info(self,obj): reg=Authors(instance=obj.author.all(),many=True) return reg.data
read_only:资源可访问无法修改
write_only:无法读取
无需规定序列化字段-ModelSerializers的用法
在里面的类里定义元 里面有哪些字段
exclude 则为 和filelds 取反的字段
class Books(ModelSerializer): class Meta: model=models.Book fields="__all__" #所有的字段 如果只要个别的话 ["name","price"] depth=1 #如果是外键的话进一层,拿到那个对象所有的属性
想重写其他字段(比如不想使用name作为键)可以在同级的class 下重写
注意:fields 如果是__all__ 那么就不能再重写一个 ,否则会多一个校验
反序列化
1.试图类里定义post方法
2.实例化 序列化类 参数 data=request.data
3.数据清洗 is_valid() 执行后 数据ok的放在validated_data
4.在试图函数写create方法
5.调用create方法保存
6.返回
如果是ModelSerializers 直接save
反序列化的校验
is_valid(raise_exception=True) 如果捕获到异常 就直接返回return Http不会走接下来的代码
先校验原字段是否有错误 如果错误的话会加到bookser.errors
如果is_valid(raise_exception=True) 则直接把错误返回
validate_name 额外校验错误字段
validate 全局钩子 全局检验
def validate_name(self,value): print(value) raise exceptions.ValidationError('不能以sb开头') # if value.startswith('sb'): # raise ValidationError('不能以sb开头') # return value def validate(self,attrs): print(attrs) # if attrs.get('price')!=attrs.get('xx'): # raise exceptions.ValidationError('name和price相等,不正常') return attrs
认证组件
前后端分离之后,无法像之前那样把我们的session直接设置到返回的render里面返回给客户端
但是我们可以在用户登陆成功之后,为他生成一个token 然后给他返回这个值,并且下次请求来之后我们通过我们的认证组件来判断是否是认证成功的用户
使用:
1.定义类 在类里重写anthenticate authenticate_header(可以不是先方法)
2 在anthenticate下写认证方法
3.如果认证成功我们可以返回一个 (user, token).
4.不成功可以抛出异常 raise AuthenticationFailed('您没有登录')
5.在APIview 定义一个字典
authentication_classes = [刚才的类, ]
from rest_framework.authentication import BaseAuthentication #导入继承的类
from rest_framework.exceptions import AuthenticationFailed #不通过认证需要抛出的异常类型
class TokenAuth():
def authenticate(self, request):
raise AuthenticationFailed('认证失败')
def authenticate_header(self,request):
pass
class Course(APIView):
authentication_classes = [TokenAuth, ]
def get(self, request):
return HttpResponse('get')
def post(self, request):
return HttpResponse('post')
全局使用
总而言之,源码会默认从类试图开始找认证组件 没有找到从setting里面取 还是找不到找默认的
我们可以在
REST_FRAMEWORK={
"DEFAULT_AUTHENTICATION_CLASSES":["app01.MyAuths.MyAuth",]}
权限组件
1.自定义类 继承BasePermission
2.重写has_permission 方法
3.检查权限决定返回True和False False 返回错误信息
4.在ApiView的类里面定义permission_classes
class MyAuth(BaseAuthentication): def authenticate(self,request): #写一些认证的逻辑 # print('我是认证类中的方法,只要配置了,一定会走我') token=request.GET.get('token') token_obj=models.Token.objects.filter(token=token).first() if token_obj: #有值表示登录了 #token_obj.user 当前登录的user对象 return token_obj.user,token_obj else: #没有值,表示没有登录,抛异常 raise AuthenticationFailed('您没有登录')
不想要一个个添加验证类 设置全局
REST_FRAMEWORK={
"DEFAULT_PERMISSION_CLASSES":["app01.MyAuths.MyPermision",]
}
不想验证禁用 比如登陆函数还得去验证是否登陆-金庸
在试图函数上 定义permission_classes = []
class MyPermision(BasePermission): permission_classes=["Lei "] message = '不是超级用户,查看不了' def has_permission(self,request,view): if request.user.user_type==1: return True else: return False
视图-什么get,post,都得自己实现?low爆了
方式一 继承mixins来封装试图函数
获取和添加的
CreateModelMixin #添加数据的
ListModelMixin #查询全部数据
RetrieveModelMixin#查询单个数据
DestroyModelMixin #删除数据
UpdateModelMixin #更新数据
GenericAPIView #APIVIEW 不能是普通的APIView
# from rest_framework.mixins import CreateModelMixin,ListModelMixin,RetrieveModelMixin,DestroyModelMixin,UpdateModelMixin # from rest_framework.generics import GenericAPIView
class PublishView(CreateModelMixin,ListModelMixin,GenericAPIView): queryset = models.Publish.objects.all() serializer_class = PublishSerializers #这里值得是序列化组件类 def post(self,request, *args, **kwargs): return self.create(request, *args, **kwargs) #增加 def get(self,request, *args, **kwargs): return self.list(request, *args, **kwargs) #查询
class PublishDetailView(RetrieveModelMixin,DestroyModelMixin,UpdateModelMixin,GenericAPIView): queryset = models.Publish.objects.all() serializer_class = PublishSerializers def get(self,request, *args, **kwargs): return self.retrieve(request, *args, **kwargs) def put(self,request, *args, **kwargs): return self.update(request, *args, **kwargs) def delete(self,request, *args, **kwargs): return self.destroy(request, *args, **kwargs)
url("^books/(?P<pk>d+)?",views.Course.as_view()), #需要指定具体图书的一般走这条 获取所有和添加 url("^books/",views.Course.as_view()), # #不需要指定具体图书的一般走这条 获取具体 添加删除修改
第二种 不需要在继承视图类了
from rest_framework.generics import CreateAPIView,ListCreateAPIView,DestroyAPIView,RetrieveUpdateDestroyAPIView
from rest_framework.generics import CreateAPIView,ListCreateAPIView,DestroyAPIView,RetrieveUpdateDestroyAPIView class PublishView(ListCreateAPIView): queryset = models.Publish.objects.all() serializer_class = PublishSerializers class PublishDetailView(RetrieveUpdateDestroyAPIView): queryset = models.Publish.objects.all() serializer_class = PublishSerializers
第三种 5个接口写在一个类中
问题怎么区别是 有两个get ?
from django.views import View from rest_framework.viewsets import ModelViewSet class PublishView(ModelViewSet): queryset=models.Publish.objects.all() serializer_class=PublishSerializers
在url 里面控制着执行哪个函数
通过两个url 区分哪个
url(r'^publish/$', views.PublishView.as_view({'get': 'list', 'post': 'create'})), url(r'^publish/(?P<pk>d+)/$',views.PublishView.as_view({'get': 'retrieve', 'put': 'update', 'delete': 'destroy'})),
当然也可以重写,指定一下就可以了
from rest_framework.viewsets import ViewSetMixin from rest_framework.views import APIView # ViewSetMixin 重写了as_view方法 class Test(ViewSetMixin,APIView): def aaa(self,request): return Response()
url(r'^publish/$', views.PublishView.as_view({'get': 'list', 'post': 'create'})), url(r'^publish/(?P<pk>d+)/$',views.PublishView.as_view({'get': 'retrieve', 'put': 'update', 'delete': 'destroy'})),
频率组件
用来做频率校验 比如一个user 每分钟访问url 多少次
#1.第一步 写组件类 重写get_cache_key, 取别名 class Plkzq(SimpleRateThrottle): scope = "xzq" def get_cache_key(self, request, view): '''这里写什么就以什么做访问依据''' return request.META.get("REMOTE_ADDR") #2.在View的列表里定义 throttle_classes = [频率组件, ] class V(APIView): throttle_classes = [Plkzq, ] def get(self,request): return Response("") #3.然后去setting 配置频率scope #{"别名":“频率”} REST_FRAMEWORK={"DEFAULT_THROTTLE_RATES":{'xzq':'3/m'}}1
自定义频率组件
class MyThrottle(BaseThrottle): VISIT_RECORD = {} def __init__(self): self.history=None def allow_request(self,request,view): #自定义控制每分钟访问多少次,运行访问返回true,不允许访问返回false # (1)取出访问者ip{ip1:[第二次访问时间,第一次访问时间],ip2:[]} # (2)判断当前ip不在访问字典里,如果不在添加进去,并且直接返回True,表示第一次访问,在字典里,继续往下走 # (3)循环判断当前ip的列表,有值,并且当前时间减去列表的最后一个时间大于60s,把这种数据pop掉,这样列表中只有60s以内的访问时间, # (4)判断,当列表小于3,说明一分钟以内访问不足三次,把当前时间插入到列表第一个位置,返回True,顺利通过 # (5)当大于等于3,说明一分钟内访问超过三次,返回False验证失败 # (1)取出访问者ip # print(request.META) #取出访问者ip ip = request.META.get('REMOTE_ADDR') import time #拿到当前时间 ctime = time.time() # (2)判断当前ip不在访问字典里,添加进去,并且直接返回True,表示第一次访问 if ip not in self.VISIT_RECORD: self.VISIT_RECORD[ip] = [ctime, ] return True #是个当前访问者ip对应的时间列表 [第一次访问的时间,] self.history = self.VISIT_RECORD.get(ip) # (3)循环判断当前ip的列表,有值,并且当前时间减去列表的最后一个时间大于60s,把这种数据pop掉,这样列表中只有60s以内的访问时间, while self.history and ctime - self.history[-1] > 60: self.history.pop() # (4)判断,当列表小于3,说明一分钟以内访问不足三次,把当前时间插入到列表第一个位置,返回True,顺利通过 # (5)当大于等于3,说明一分钟内访问超过三次,返回False验证失败 if len(self.history) < 3: self.history.insert(0, ctime) return True else: return False def wait(self): import time ctime = time.time() return 60 - (ctime - self.history[-1])
真*源码解析!
#我们继承了 APIview 之后做了哪些事? 请求来了之后 执行dispatch: 调用自身的 initialize_request 把结果给 request #initialize_request : 实例化Request 把结果返回 request拿到了 实例化对象 Request实例化的时候把原request 进行封装 #调用initial 1.进行认证组件 2.权限组件校验 3.频率组件校验 #返回试图
#1,认证组件源码解析 request.user # if not hasattr(self, '_user'): with wrap_attributeerrors(): self._authenticate() 2.最后执行request.user 方法 循环在自己的authenticators 【“class”】 3.执行认证方法 类:authenticate(self) 默认返回一个(self.force_user, self.force_token) 则为通过校验 4.最后把user和token 拆成self.user 和self.auth 我们可以重写这里的方法 如果不通过 可以抛出异常
#1.身份模块 2.进入check_permissions() 调用permission.has_permission(request, self) 如果返回了False就执行permission_denied 3.我们进has_permission 默认返回True
4.我们可以重写 has_permission方法
# 3.频率控制器check_throttles 同上 循环self.get_throttles() 得到类对象 throttle.allow_request() 如果返回false 执行throttled 3.如果在self.key没有那么返回True 4.取出世界列表封到self.history self.now=时间戳 5.删除事件戳大于规定时间之外的时间戳 6.
分页器
http://127.0.0.1:8000/books/?page=1&size=4
from rest_framework.pagination import PageNumberPagination class S(PageNumberPagination): page_size = 3 #控制着每一页的数量 #默认在setting配置 page_query_param = 'page' # 定制传参 page_size_query_param = 'size' #size控制每一页数量的名字 # 最大一页的数据 max_page_size = 5 #size多少 每一页个数就是多少 但是最高不能超过5
class Books(APIView): def get(self,request): page=S() #实例化 publish_list=Publish.objects.all() page_content=page.paginate_queryset(publish_list,request,self) #把对象丢进去 根据 自动帮我们拿到需要的对象 reg=aaa.PublishSerializer(instance=page_content,many=True) #序列化 return page.get_paginated_response(reg.data) #也是response 不过 自带了 count next previous参数
url:
REST_FRAMEWORK = { 'PAGE_SIZE':2 #表示每页显示两条 }
偏移分页(在第n个位置,向后查看n条数据)
page=LimitOffsetPagination() page.limit_query_param="limit" #以limit作为url参数进行分割 page.offset_query_param="offset" #定位数 作为url参数 page.default_limit = 2 #默认定位后要两个 page.max_limit=3 #值为多少 每一页最大取多少 publish_list=Publish.objects.all() page_content=page.paginate_queryset(publish_list,request,self) reg=aaa.PublishSerializer(instance=page_content,many=True) return page.get_paginated_response(reg.data)
url:
REST_FRAMEWORK = {
'PAGE_SIZE':2 #表示每页显示两条
}
加密分页 没有具体页
只有上一页下一页
方法和第二种一样 只是类为类 为 CursorPagination page.ordering="id" #根据id进行排序 page.cursor_query_param="cursor" #游标参数 page.page_size = 3 #最大显示多少也
URL控制器
defaultRouter和simpleRouter 的区别
半自动路由
拿到具体请求 到类下执行函数,必须继承modelViewSet
urlpatterns = [ url(r'^publish/$', views.PublishView.as_view({'get':'list','post':'create'})), url(r'^publish/(?P<pk>d+)/$', views.PublishView.as_view({'get':'retrieve','put':'update','delete':'destroy'})), ]
from rest_framework.viewsets import ModelViewSet class PublishView(ViewSetMixin): queryset=models.Publish.objects.all() serializer_class=PublishSerializers
全自动路由
from rest_framework.routers import DefaultRouter route=DefaultRouter() route.register("publish",views.Publish) #第一个是url名字 url(r'',include(router.urls)) #分发到 路由类下的urls 去匹配
from rest_framework.viewsets import ModelViewSet class PublishView(ModelViewSet): queryset=models.Publish.objects.all() serializer_class=PublishSerializers
解析器
全局
解析具体的 content-type 只允许规定的提交的编码方式
1.setting配置
REST_FRAMEWORK = {
'DEFAULT_PARSER_CLASSES':[
'rest_framework.parsers.JSONParser'
'rest_framework.parsers.FormParser'
'rest_framework.parsers.MultiPartParser'
]
}
2.只有解析器能解析出来的放在qequest.data里面
局部
1.从解析器里导入解析器
2.类下 列表使用 关键字 par
响应器
访问jason的
http://127.0.0.1:8000/test/?format=json
http://127.0.0.1:8000/test.json
访问默认的
- http://127.0.0.1:8000/test/?format=api
- http://127.0.0.1:8000/test.api
- http://127.0.0.1:8000/test/
表格方式:AdminRenderer
访问URL:
- http://127.0.0.1:8000/test/?format=admin
- http://127.0.0.1:8000/test.admin
- http://127.0.0.1:8000/test/
form表单方式:HTMLFormRenderer
访问URL:
- http://127.0.0.1:8000/test/?format=form
- http://127.0.0.1:8000/test.form
- http://127.0.0.1:8000/test/
局部使用
允许的相应器 renderer_classes = [HTMLFormRenderer,BrowsableAPIRenderer]
会自动根据 路径后缀选择具体相应其
全局使用
REST_FRAMEWORK = { 'DEFAULT_RENDERER_CLASSES':['rest_framework.renderers.JSONRenderer'] }
版本控制
在setting中配置:
'DEFAULT_VERSIONING_CLASS':'rest_framework.versioning.URLPathVersioning', 'DEFAULT_VERSION': 'v1', # 默认版本(从request对象里取不到,显示的默认值) 'ALLOWED_VERSIONS': ['v1', 'v2'], # 允许的版本 'VERSION_PARAM': 'version' # URL中获取值的key
url(r'^(?P<version>[v1|v2]+)/test/', views.Test.as_view()),
最后试图可以通过request.version取出版本
跨域问题
在服务器接受用户请求的时候 ,我们把这些请求处理之后返回给浏览器 浏览器就阻拦这个响应。原因出在浏览器与服务器有个约定-同源策略
那么就报错了
解决:
1.定义类,继承
2.往response加东西
3.加中间件
class my_middlewaremixin(MiddlewareMixin): def process_response(self,request,response): response["Access-Control-Allow-Origin"]="*" #允许所有的网站跨域 return response
注册中间件
还不够这只是处理简单请求
如果你要处理非简单请求 ,比如发送delect 或者请求头有 json 那么浏览器就会有个预检 options,先发送
我发这个请求 你看允不允许啊 ,允许的话 再发送
怎么设置允许通过?
response['Access-Control-Allow-Headers'] = "Content-Type" #其他的编码方式比如 json # 允许你发送DELETE,PUT response['Access-Control-Allow-Methods'] = "DELETE,PUT"
缓存技术
-全站缓存
1.在两端加上中间件
MIDDLEWARE_CLASSES = ( ‘django.middleware.cache.UpdateCacheMiddleware’, #村值的时候 'django.middleware.common.CommonMiddleware', ‘django.middleware.cache.FetchFromCacheMiddleware’, #取值的时候
)
2.设置setting
CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.dummy.DummyCache', # 缓存后台使用的引擎 'TIMEOUT': 300, # 缓存超时时间(默认300秒,None表示永不过期,0表示立即过期) 'OPTIONS':{ 'MAX_ENTRIES': 300, # 最大缓存记录的数量(默认300) 'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3) }, } }
-单页面缓存
from django.views.decorators.cache import cache_page @cache_page(1*60) def index(self,request)
-局部缓存
{% cache 2 'name' %}
<h3>缓存:-----:{{ t }}</h3>
{% endcache %}
-全局使用缓存
from django.core.cache import cache
cache.set("ergouzi","18",20) #设置缓存 键 值 超时时间
cache.get("ergouzi") #从缓存里取出数据
redis
百度云
链接:https://pan.baidu.com/s/1vdecdjmk32ckWBxT-1VTLQ
提取码:pw7l
为什么不用navicat 因为不能持久化
自动生成文档
# 8. 自动生成接口文档 REST framework可以自动帮助我们生成接口文档。 接口文档以网页的方式呈现。 自动接口文档能生成的是继承自`APIView`及其子类的视图。 ## 8.1. 安装依赖 REST framewrok生成接口文档需要`coreapi`库的支持。 ```python pip install -i https://pypi.douban.com/simple/ coreapi ``` ## 8.2. 设置接口文档访问路径 在总路由中添加接口文档路径。 文档路由对应的视图配置为`rest_framework.documentation.include_docs_urls`, 参数`title`为接口文档网站的标题。 ```python from rest_framework.documentation import include_docs_urls urlpatterns = [ ... path('docs/', include_docs_urls(title='站点页面标题')) ] ``` ## 8.3. 文档描述说明的定义位置 1) 单一方法的视图,可直接使用类视图的文档字符串,如 ```python class BookListView(generics.ListAPIView): """ 返回所有图书信息. """ ``` 2)包含多个方法的视图,在类视图的文档字符串中,分开方法定义,如 ```python class BookListCreateView(generics.ListCreateAPIView): """ get: 返回所有图书信息. post: 新建图书. """ ``` 3)对于视图集ViewSet,仍在类视图的文档字符串中封开定义,但是应使用action名称区分,如 ```python class BookInfoViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, GenericViewSet): """ list: 返回图书列表数据 retrieve: 返回图书详情数据 latest: 返回最新的图书数据 read: 修改图书的阅读量 """ ``` ## 8.4. 访问接口文档网页 浏览器访问 127.0.0.1:8000/docs/,即可看到自动生成的接口文档。 #### 两点说明: 1) 视图集ViewSet中的retrieve名称,在接口文档网站中叫做read 2)参数的Description需要在模型类或序列化器类的字段中以help_text选项定义,如: ```python class Student(models.Model): ... age = models.IntegerField(default=0, verbose_name='年龄', help_text='年龄') ... ``` 或 ```python class StudentSerializer(serializers.ModelSerializer): class Meta: model = Student fields = "__all__" extra_kwargs = { 'age': { 'required': True, 'help_text': '年龄' } } ```