上一篇笔记记录了JDBC的手动实现,这次记录JDBC使用数据库连接池技术,实际上这也是开发中使用的最多的方式。
既然使用最多,那么肯定要讲讲使用数据库连接池的好处:
1.实现资源重用,避免了频繁创建、释放连接引起的开销,减少系统消耗;
2.更快的系统反应速度;
3.对连接进行统一管理,避免数据库连接泄漏。根据预先的占用超时设定,强制回收被占用连接,从而避免了常规数据库连接操作中可能出现的资源泄露;
不多说先上图:
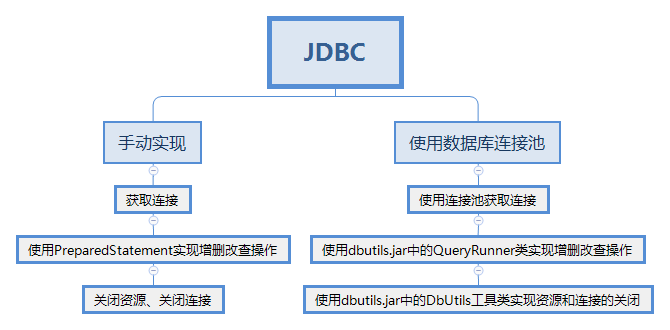
这次要记录的是右边的路线,和左边的路线一样是分为三步的,但是在最开始之前都要先进行导包,为什么要进行导包?
JDBC 的数据库连接池使用 javax.sql.DataSource 来表示,DataSource 只是一个接口,该接口的实现是由一些组织或者服务器提供的,所以需要导包;
DataSource 通常被称为数据源,它包含连接池和连接池管理两个部分,习惯上也经常把 DataSource 称为连接池。
DataSource用来取代DriverManager来获取Connection,和手动实现一样,我们只需要一个数据源,但是这个数据源产生的数据库连接可以有很多个。
这里将所有的包都导入进来,数据库的驱动不要忘了导!
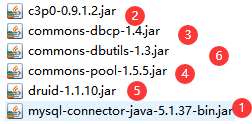
①是MySQL对应的jdbc驱动
②是c3p0数据库连接池的jar包
③和④是dbcp数据库连接池的jar包
⑤是druid数据库连接池的jar包
⑥是dbutils的jar包
这是一些比较常用的数据库连接池,还有很多其他的数据库连接池,这里不做介绍。
一、获取连接
这里将记录三种数据库连接池分别是:
① C3P0(速度较慢,稳定性好);
② DBCP(tomcat自带连接池,速度快,但不怎么稳定);
③ Druid(阿里巴巴提供,速度快,稳定性好,目前使用较多)。
①C3P0数据库连接池实现。一般使用配置文件的方式获取获取连接,所以这里介绍的都是这种方式
<?xml version="1.0" encoding="UTF-8"?>
<c3p0-config>
<named-config name="helloc3p0">
<!-- 提供获取连接的4个基本信息 -->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/test</property>
<property name="user">root</property>
<property name="password">1234</property>
</named-config>
</c3p0-config>
和手动实现一样,依然需要这四个基本信息。接下来是代码。注意看注释
package notes1.jdbc.jdbc_2;
import java.sql.Connection;
import java.sql.SQLException;
import javax.sql.DataSource;
import com.mchange.v2.c3p0.ComboPooledDataSource;
public class C3P0Test {
//首先需要造一个池子,括号里面的是配置名,对应配置文件的
//<named-config name="helloc3p0">
ComboPooledDataSource cpds = new ComboPooledDataSource("helloc3p0");
public Connection getConnectionByC3p0() throws SQLException {
//然后通过池子获取连接
//这里抛异常而不采用try-catch处理是因为:
//如果连接没获取到,报了异常,即使将异常处理掉,也没有意义,因为我们想要的是获取到连接
Connection conn = cpds.getConnection();
//接着返回连接
return conn;
}
}
②DBCP数据库连接池实现。先是配置信息
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/test
username=root
password=1234
接下来是代码,注意看注释
package notes1.jdbc.jdbc_2;
import java.io.InputStream;
import java.sql.Connection;
import java.util.Properties;
import javax.sql.DataSource;
import org.apache.commons.dbcp.BasicDataSourceFactory;
public class DBCPTest {
private static DataSource source;
static {
try {
//1.先获取一个properties对象,将配置文件加载进来
Properties pros = new Properties();
//2.加载文件需要一个输入流,通过类加载器获取一个系统类加载器,然后获取流
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("dbcp.properties");
//3.这里有异常,我们先抛一下
pros.load(is);
//4.先通过数据库连接池工厂创建一个池子,括号里需要的是properties对象
source = new BasicDataSourceFactory().createDataSource(pros);
}catch(Exception e) {
e.printStackTrace();
}
}
public Connection getConnectionByDbcp() throws Exception {
//0.先将所有步骤写在方法里
//5.通过池子获取连接
Connection conn = source.getConnection();
//6.返回连接
return conn;
//7.反思,发现如果调用一次这个方法,就会创建一个池子,
//而我们说了池子只需要一个,所以将创建池子的步骤放到方法外面,并使用静态代码块保证只有一个池子
//8.将获取source的步骤放到方法外面发现会报错,因为pros在方法里面,所以pros的相关操作也需要放到外面
//9.提到外面发现3.处的异常不能抛了,4.也出现了异常,所以只能try-catch处理掉
//10.处理完异常,发现5.处的source又无法通过编译,所以只能将source作为一个属性来声明
}
}
③ Druid数据库连接池实现。先配置文件
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/test
username=root
password=1234
这里的代码和dbcp的代码构思一样,所以就只上代码了。
package notes1.jdbc.jdbc_2;
import java.io.InputStream;
import java.sql.Connection;
import java.util.Properties;
import javax.sql.DataSource;
import com.alibaba.druid.pool.DruidDataSourceFactory;
public class DruidTest {
private static DataSource source;
static {
try {
Properties pros = new Properties();
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");
pros.load(is);
source = (DataSource) new DruidDataSourceFactory().createDataSource(pros);
}catch(Exception e) {
e.printStackTrace();
}
}
public Connection getConnectionByDruid() throws Exception {
Connection conn = source.getConnection();
return conn;
}
}
至此,三种数据库连接池的获取连接方式都写好了,可以把三种方式放在一个JDBCUtils类中,添加static关键字作为工具类来使用
二、使用dbutils.jar中的QueryRunner类来实现增删查改操作
这里只演示了添加操作,因为删除和更改操作都是调用update()方法,只是sql语句不一样罢了。
对于查询操作,只写了一种多条查询,不同的查询操作结果集由不同的ResultSetHandler接口的子类实现来接收查询结果。上代码
package notes1.jdbc.jdbc_2;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.List;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.junit.Test;
import notes1.jdbc.jdbc_2.JDBCUtils;;
public class QueryRunnerTest {
@Test
public void testInsert() {
Connection conn = null;
try {
// 1.获取一个QueryRunner类的对象
QueryRunner runner = new QueryRunner();
// 2.通过runner调用update方法实现增删查操作
// 通过查看源码发现update也是使用的PreparedStatement来进行操作的
conn = JDBCUtils.getConnectionByDruid();
String sql1 = "insert into customers(name,email,birth) values(?,?,?)";
int insertCount = runner.update(conn, sql1, "学渣很忙", "xzhm@126.com", "1998-09-08");
System.out.println("添加了:" + insertCount + "条记录");
// 下面是查询操作,Customer是要查询的类,根据ORM编程思想所创建的类,由sql1可以看出这个类里面有些什么属性
// ResultSetHandler接口,用于处理数据库查询操作得到的结果集,不同结果集的情形由不同子类来实现
// BeanListHandler:是ResultSetHandler接口的实现类,用于封装表中的多条记录构成的集合
String sql2 = "select id,name,email,birth from customers where id < ?";
BeanListHandler<Customer> handler = new BeanListHandler<Customer>(Customer.class);
List<Customer> list = runner.query(conn, sql2, handler, 12);
// 打印list
list.forEach(System.out::println);
} catch (Exception e) {
e.printStackTrace();
} finally {
JDBCUtils.closeResource(conn, null, null);
}
}
}
下面是Customer类的代码:
package notes1.jdbc.jdbc_2; import java.sql.Date; /* * ORM编程思想(object relational mapping) * 一个数据表对应一个Java类 * 表中的一条记录对应Java类的一个对象 * 表中的一个字段对应Java类的一个属性 * */ public class Customer { private int id; private String name; private String email; private Date birth; public Customer() { super(); } public Customer(int id, String name, String email, Date birth) { super(); this.id = id; this.name = name; this.email = email; this.birth = birth; } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getEmail() { return email; } public void setEmail(String email) { this.email = email; } public Date getBirth() { return birth; } public void setBirth(Date birth) { this.birth = birth; } @Override public String toString() { return "Customer [id=" + id + ", name=" + name + ", email=" + email + ", birth=" + birth + "]"; } }
三、释放连接
将标题写为释放连接是因为使用连接池获取的连接,使用完毕以后只是将连接放回了连接池,而这个连接并没有被销毁。
使用DbUtils类的关闭资源连接的方法特别简单,所以我也将其放在了JDBCUtils这个工具类中了
public static void closeResource(Connection conn, Statement ps, ResultSet rs) {
DbUtils.closeQuietly(conn);
DbUtils.closeQuietly(ps);
DbUtils.closeQuietly(rs);
}
以上就是本期笔记的全部内容了,写了一个上午才完成。希望大家给点意见,谢谢!
我是学渣很忙,感谢大家的观看!