一、什么是xml
- XML 指可扩展标记语言(EXtensible Markup Language)
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 标签没有被预定义。您需要自行定义标签。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准
二、html与xml区别
- XML 不是 HTML 的替代。XML 和 HTML 为不同的目的而设计:
- XML 被设计为传输和存储数据,其焦点是数据的内容。
- HTML 被设计用来显示数据,其焦点是数据的外观。
- HTML 旨在显示信息,而 XML 旨在传输信息。
- HTML语法比较松散,xml语法严格。
- HTML所有标签都是预先定义好的, 使用固定的标签,展示不同的内容;XML当中的标签都是自己定义的。
三、XML用处
- 数据存储
- 配置文件
- 数据传输
四、基本语法
(1)文档声明
必须写在文档的第一行
<?xml version="1.0" encoding="UTF-8"?>
属性:
- version:版本号,固定 1.0
- encoding:指定文档的码表,默认iso-8859-1
- standalone:指定文档是否独立yes或no,是否可以引用其它文件
(2)规则
- 所有 XML 元素都须有关闭标签
- XML 标签对大小写敏感
- XML 必须正确地嵌套
- XML 文档必须有根元素
- XML 的属性值须加引号
- 实体引用:在 XML 中,一些字符拥有特殊的意义。如果你把字符 "<" 放在 XML 元素中,会发生错误,这是因为解析器会把它当作新元素的开始。这样会产生 XML 错误:为了避免这个错误,请用实体引用来代替 "<" 字符:
5 个预定义的实体引用
| 实体引用 | 代表字符 |
|---|---|
| < | < 小于 |
| > | > 大于 |
| & | & 和号 |
| ' | ' 单引号 |
| " | " 引号 |
(3)元素
- 名称可以包含字母、数字、以及其他的字符
- 名称不能以数字或标点符号开始
- 名称不能以字符 “xml”(或者 XML,Xml) 开始
- 名称不能包含空格
(4)文本
CDATA:里面的数据会原样显示
<![CDATA[数据内容]]>
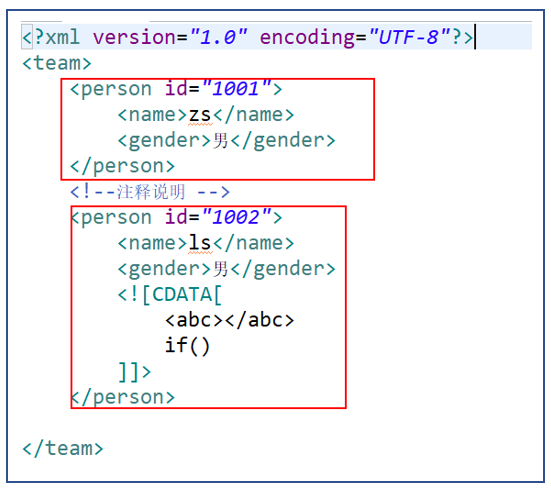

(5)属性
属性值必须引用引号,单双都行
五、XML约束
什么是约束:规定文档当中只能写哪些标签。并且会给一些提示。
(1)DTD约束
-
内部 dtd:在xml当中定义的 dtd
-
外部 dtd:在外部文件当中单独定义的 dtd
-
本地:
<!DOCTYPE 名称 SYSTEM "student.dtd"> -
网络:
<!DOCTYPE students PUBLIC "命名空间" "student.dtd">
-
约束语法
<!ELEMENT 元素 (子元素列表)>
| 标记 | 说明 |
|---|---|
| ? | 零次或一次 |
| * | 零次或多次 |
| + | 一次或多次 |
| | | 或 |
| #PCDATA | 文本 |
<!ELEMENT web-app (servlet*,servlet-mapping*,wel-file-list?)>
<!ELEMENT servlet (servlet-name,description?,(servlet-class|jsp-file))>
<!ELEMENT servlet-name (#PCDATA)>
<!ELEMENT wel-file-list (welcome-file+)>

存在的问题
在标签当中存放的内容不知道是什么类型,写的都是汉字,这种约束不严谨
(2)schema
<?xml version="1.0" encoding="UTF-8"?>
<note>
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>
下面这个例子是名为 "note.dtd" 的 DTD 文件,它对上面那个 XML 文档的元素进行了定义:
<!ELEMENT note (to, from, heading, body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>
下面这个例子是一个名为 "note.xsd" 的 XML Schema 文件,它定义了上面那个 XML 文档的元素:
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.w3school.com.cn"
xmlns="http://www.w3school.com.cn"
elementFormDefault="qualified">
<xs:element name="note">
<xs:complexType>
<xs:sequence>
<xs:element name="to" type="xs:string"/>
<xs:element name="from" type="xs:string"/>
<xs:element name="heading" type="xs:string"/>
<xs:element name="body" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
对 DTD 的引用:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE note SYSTEM "http://www.w3school.com.cn/dtd/note.dtd">
<note>
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>
对 XML Schema 的引用:
<?xml version="1.0" encoding="UTF-8"?>
<note
xmlns="http://www.w3school.com.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3school.com.cn note.xsd">
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>
<schema> 元素
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.w3school.com.cn"
xmlns="http://www.w3school.com.cn"
elementFormDefault="qualified">
</xs:schema>
| 属性 | 说明 |
|---|---|
| xmlns:xs | schema 中用到的元素和数据类型来自命名空间 "http://www.w3.org/2001/XMLSchema",同时它还规定了来自此命名空间的元素和数据类型应该使用前缀 xs: |
| targetNamespace | 显示被此 schema 定义的元素 (note, to, from, heading, body) 来自的命名空间 |
| xmlns | 指出默认的命名空间 |
| elementFormDefault | 指出任何 XML 实例文档所使用的且在此 schema 中声明过的元素必须被命名空间限定 |
元素
<xs:element name="xxx" type="yyy"/>
此处 xxx 指元素的名称,yyy 指元素的数据类型。XML Schema 拥有很多内建的数据类型。
最常用的类型是:
- xs:string
- xs:decimal
- xs:integer
- xs:boolean
- xs:date
- xs:time
元素的默认值和固定值
在下面的例子中,缺省值是 "red":
<xs:element name="color" type="xs:string" default="red"/>
在下面的例子中,固定值是 "red":
<xs:element name="color" type="xs:string" fixed="red"/>
属性
<xs:attribute name="xxx" type="yyy"/>
这是带有属性的 XML 元素:
<lastname lang="EN">Smith</lastname>
这是对应的属性定义:
<xs:attribute name="lang" type="xs:string"/>
属性的默认值和固定值
在下面的例子中,缺省值是 "EN":
<xs:attribute name="lang" type="xs:string" default="EN"/>
在下面的例子中,固定值是 "EN":
<xs:attribute name="lang" type="xs:string" fixed="EN"/>
可选的和必需的属性
在缺省的情况下,属性是可选的。如需规定属性为必选,请使用 "use" 属性:
<xs:attribute name="lang" type="xs:string" use="required"/>
简单标签
标签当中没有子标签了。
<xs:simpleType> </xs:simpleType>
限定
| 限定 | 描述 |
|---|---|
| enumeration | 定义可接受值的一个列表 |
| fractionDigits | 定义所允许的最大的小数位数。必须大于等于0。 |
| length | 定义所允许的字符或者列表项目的精确数目。必须大于或等于0。 |
| maxExclusive | 定义数值的上限。所允许的值必须小于此值。 |
| maxInclusive | 定义数值的上限。所允许的值必须小于或等于此值。 |
| maxLength | 定义所允许的字符或者列表项目的最大数目。必须大于或等于0。 |
| minExclusive | 定义数值的下限。所允许的值必需大于此值。 |
| minInclusive | 定义数值的下限。所允许的值必需大于或等于此值。 |
| minLength | 定义所允许的字符或者列表项目的最小数目。必须大于或等于0。 |
| pattern | 定义可接受的字符的精确序列。 |
| totalDigits | 定义所允许的阿拉伯数字的精确位数。必须大于0。 |
| whiteSpace | 定义空白字符(换行、回车、空格以及制表符)的处理方式。 |
(1)值的限定
下面的例子定义了带有一个限定且名为 "age" 的元素。age 的值不能低于 0 或者高于 120:
<xs:element name="age">
<xs:simpleType>
<xs:restriction base="xs:integer">
<xs:minInclusive value="0"/>
<xs:maxInclusive value="120"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
(2)选择限定
如需把 XML 元素的内容限制为一组可接受的值,我们要使用枚举约束。
下面的例子定义了带有一个限定的名为 "car" 的元素。可接受的值只有:Audi, Golf, BMW:
<xs:element name="car">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value="Audi"/>
<xs:enumeration value="Golf"/>
<xs:enumeration value="BMW"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
上面的例子也可以被写为:
<xs:element name="car" type="carType"/>
<xs:simpleType name="carType">
<xs:restriction base="xs:string">
<xs:enumeration value="Audi"/>
<xs:enumeration value="Golf"/>
<xs:enumeration value="BMW"/>
</xs:restriction>
</xs:simpleType>
(3)正则限定
如需把 XML 元素的内容限制定义为一系列可使用的数字或字母,我们要使用模式约束。
下面的例子定义了带有一个限定的名为 "letter" 的元素。可接受的值只有小写字母 a - z 其中的一个:
<xs:element name="letter">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:pattern value="[a-z]"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
(4)长度限定
如需限制元素中值的长度,我们需要使用 length、maxLength 以及 minLength 限定。
本例定义了带有一个限定且名为 "password" 的元素。其值必须精确到 8 个字符:
<xs:element name="password">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:length value="8"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
这个例子也定义了带有一个限定的名为 "password" 的元素。其值最小为 5 个字符,最大为 8 个字符:
<xs:element name="password">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:minLength value="5"/>
<xs:maxLength value="8"/>
</xs:restriction>
</xs:simpleType>
</xs:element>
复杂标签
标签当中还有子标签
<xs:complexType> </xs:complexType>
Order 指示器:用于定义元素的顺序。
-
All:规定子元素可以按照任意顺序出现,且每个子元素必须只出现一次:
当使用 <all> 指示器时,你可以把 <minOccurs> 设置为 0 或者 1,而只能把 <maxOccurs> 指示器设置为 1
-
Choice:规定可出现某个子元素或者可出现另外一个子元素(非此即彼)
如需设置子元素出现任意次数,可将 <maxOccurs> 设置为 unbounded(无限次)。
-
Sequence:规定子元素必须按照特定的顺序出现。
Occurrence 指示器:用于定义某个元素出现的频率。
-
maxOccurs:可规定某个元素可出现的最大次数
如需使某个元素的出现次数不受限制,请使用 maxOccurs="unbounded" 这个声明
-
minOccurs:可规定某个元素能够出现的最小次数
minOccurs 的默认值是 1
Group 指示器:用于定义相关的数批元素。
- Group name
- attributeGroup name

六、XML解析
(1)XML文档结构
XML的树结构

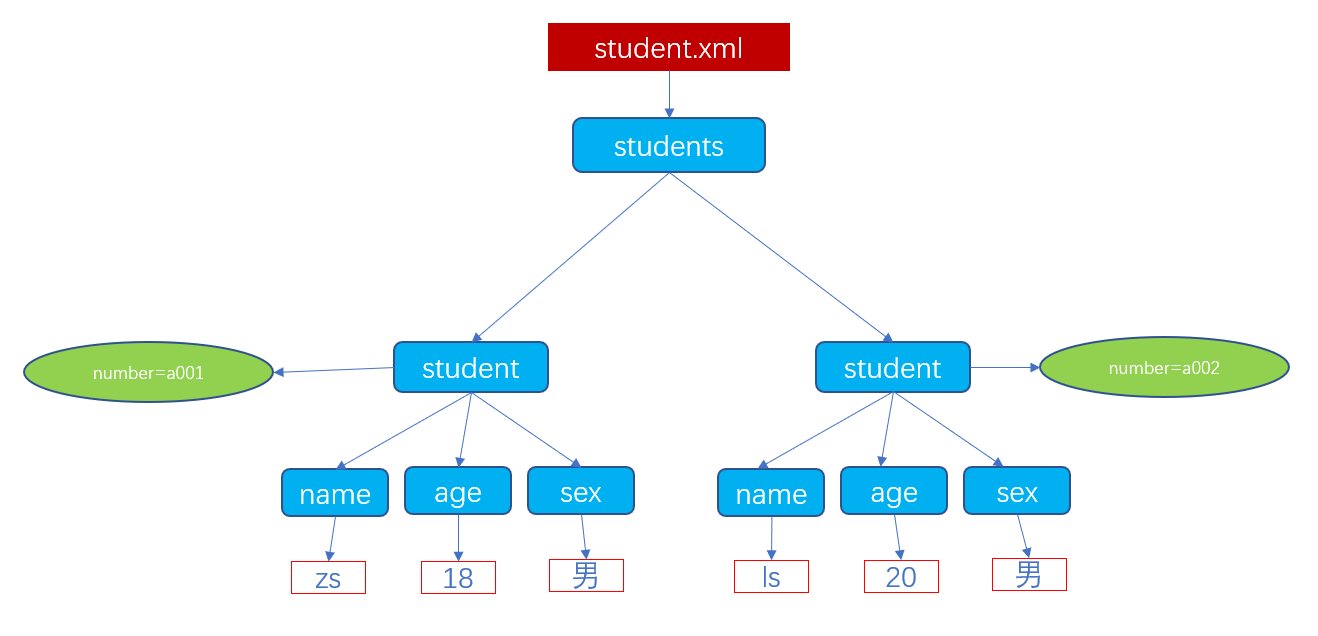
使用结点方式来表示整个xml
文档结点

元素结点
属性结点

文本结点

(2)DOM
什么是DOM
Document Object Model:文档对象模型,把文档中的成员描述成一个个对象。使用Java代码操作XML 或者 js代码操作HTML。
DOM解析的特点
在加载的时候,一次性的把整个XML文档加载进内存,在内存中形成一颗树(Document对象)。
以后使用代码操作Document,其实操作的是内存中的DOM树,和本地磁盘中的XML文件没有直接关系。
由于操作的是内存当中的dom,磁盘中xml当中的内容并没有变,要进行同步,让两边保持一致。
查询不需要同步,只有数据变化的时候,才需要同步。
缺点:若XML文件过大,可能造成内存溢出。
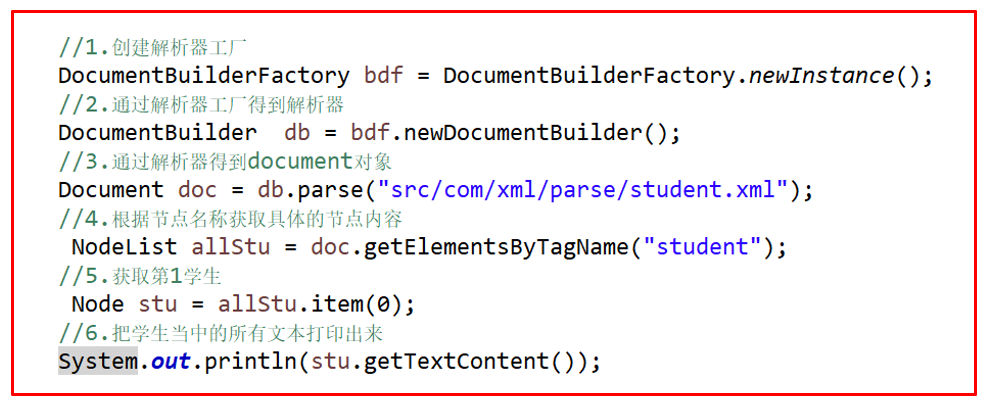
DOM解析步骤
(1)创建解析器工厂
(2)通过解析器工厂得到解析器
(3)通过解析器得到document对象
(4)获取具体的节点内容
DOM修改元素内容
(1)获取所有指定节点
(2)获取要修改的节点
(3)修改元素内容
(4)从内存写到文档做同步操作

DOM添加元素
(1)创建一个节点
(2)设置元素内容
(3)获取要添加元素的父结点
(4)添加节点
(5)从内存写到文档做同步操作

DOM删除元素
(1)获取一个节点
(2)获取该节点的父节点,从父节点当中移除
(3)从内存写到文档做同步操作

DOM添加元素属性
(1)获取要添加属性的节点
(2)把获取的节点强制转换成element
(3)设置属性
(4)从内存写到文档做同步操作

实例
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<students>
<student number="a001">
<name>张三</name>
<age>18</age>
<sex>男</sex>
</student>
<student number="a002">
<name>李四</name>
<age>30</age>
<sex>男</sex>
</student>
</students>
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.TransformerFactoryConfigurationError;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class ParseClass {
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException, Exception {
// 1.创建解析器工厂
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
// 2.通过解析器工厂得到解析器
DocumentBuilder db = dbf.newDocumentBuilder();
// 3.通过解析器得到document对象
Document doc = db.parse("src/Test/student.xml");
// 获取具体的节点内容
get(doc);
set(doc);
add(doc);
remove(doc);
setAttr(doc);
}
static void setAttr(Document doc) throws Exception, TransformerFactoryConfigurationError {
// 1.获取要添加属性的节点
Node stu = doc.getElementsByTagName("student").item(1);
// 2.把获取的节点强制转换成element
Element ele = (Element) stu;
// 3.设置属性
ele.setAttribute("ID", "00001");
// 4.从内存写到文档做同步操作
Transformer tf = TransformerFactory.newInstance().newTransformer();
tf.transform(new DOMSource(doc), new StreamResult("src/Test/student.xml"));
}
// 删除节点
static void remove(Document doc) throws Exception, TransformerFactoryConfigurationError {
// 1.获取一个节点
Node addressNode = doc.getElementsByTagName("address").item(0);
// 2.获取该节点的父节点,从父节点当中移除
addressNode.getParentNode().removeChild(addressNode);
// 3.从内存写到文档做同步操作
Transformer tf = TransformerFactory.newInstance().newTransformer();
tf.transform(new DOMSource(doc), new StreamResult("src/Test/student.xml"));
}
// 添加节点
static void add(Document doc) throws Exception, TransformerFactoryConfigurationError {
// 1.创建一个节点
Element addressEle = doc.createElement("address");
// 2.设置元素内容
addressEle.setTextContent("地址1");
// 3.获取要添加元素的父结点
Node stuNode = doc.getElementsByTagName("student").item(0);
// 4.添加节点
stuNode.appendChild(addressEle);
// 5.从内存写到文档做同步操作
Transformer tf = TransformerFactory.newInstance().newTransformer();
tf.transform(new DOMSource(doc), new StreamResult("src/Test/student.xml"));
}
// 修改元素的内容
static void set(Document doc) throws TransformerFactoryConfigurationError, Exception {
// 1.获取所有指定节点
NodeList ageList = doc.getElementsByTagName("age");
// 2.获取要修改的节点
Node ageNode = ageList.item(1);
// 3.修改元素内容
ageNode.setTextContent("30");
// 4.从内存写到文档做同步操作
Transformer tf = TransformerFactory.newInstance().newTransformer();
tf.transform(new DOMSource(doc), new StreamResult("src/Test/student.xml"));
}
// 获取具体的节点内容
static void get(Document doc) {
// 4.获取具体的节点内容
NodeList list = doc.getElementsByTagName("name");
Node name = list.item(1);
System.out.println(name.getTextContent());
}
}
七、Sax解析介绍
- 逐行读取,基于事件驱动
- 优点:不占内存,速度快
- 缺点:只能读取,不能回写
八、DOM4J
- DOM4J 是 dom4j.org 出品的一个开源XML解析包。
- dom4J 是一个十分优秀的 JavaXML API,具有性能优异、功能强大和极其易使用的特点,它的性能超过sun公司官方的dom技术,同时它也是一个开放源代码的软件。
- 越来越多的Java软件都在使用 dom4j 来读写XML,特别值得一提的是连Sun的JAXM也在用dom4j。这已经是必须使用的jar包, Hibernate也用它来读写配置文件。
dom4J解析步骤
(1)下载Dom4j的jar包
(2)在工程根目录当中创建一个文件夹为lib
(3)编译jar包
(4)创建SAXReader
(5)读取指定路径的xml
(6)获取所有指定标签内容
- 创建SAXReader
- 获取根元素
- 获取根元素下所有的元素
- 遍历每一个子元素
- 获取指定名称的元素
- 获取标签当中的文本

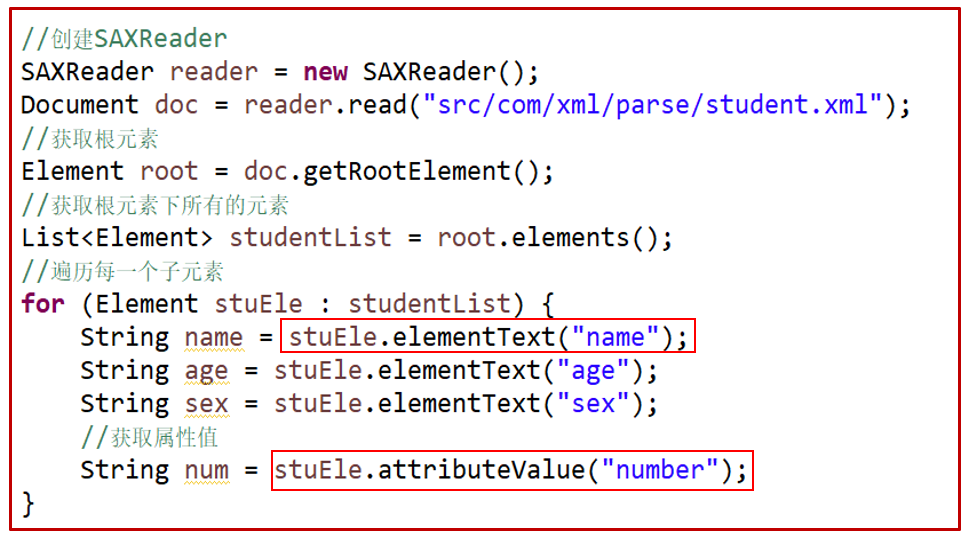
(7)获取全部标签内容
- 创建SAXReader
- 获取根元素
- 获取根元素下所有的元素
- 遍历每一个子元素
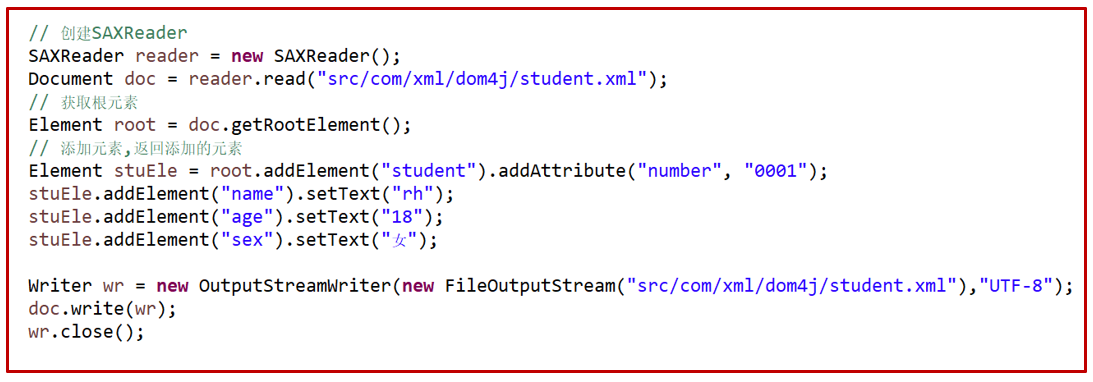
(8)添加元素
- 创建SAXReader
- 获取根元素
- 给根元素添加元素和属性,并返回添加的元素
- 将文档写入文件(同步内存)
FileWriter out = new FileWriter("foo.xml");
document.write(out);
out.close();
以上代码可能会乱码。
Writer out = new OutputStreamWriter(new FileOutputStream("foo.xml"),"UTF-8");
document.write(out);
out.close();
漂亮打印文档(按格式化打印)
OutputFormat format = OutputFormat.createPrettyPrint();
Writer out = new OutputStreamWriter(new FileOutputStream("foo.xml"),"UTF-8");
XMLWriter writer = new XMLWriter(out, format);
writer.write(doc);
out.close();