Zookeeper 架构
-
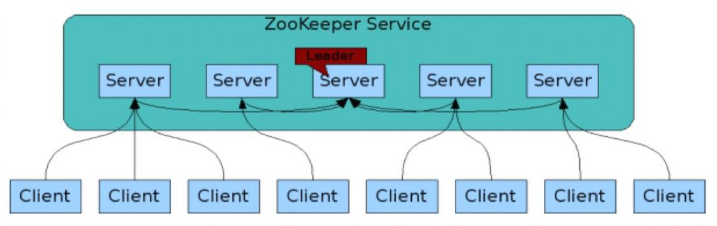
客户端随机连接集群中的任何一台 server
-
集群内所有的 server 基于 Zab(ZooKeeper Atomic Broadcast)协议通信
-
集群内部根据算法自动选举出 leader, 负责向 follower 广播所有变化消息
-
集群中每个follower 都和 leader 通信
-
follower 接收来自 leader 的所有变化消息,保存在自己的内存中
-
follower 转发来自客户端的写请求给 leader(再由leader广播给各个follower,当半数以上follower将修改持久化后,leader才会提交这个更新,接下来客户端才会收到一个更新成功的响应)
-
客户端的读请求会在 follower 端直接处理,无需转发给 leader
server状态(只有server参与选举):
- Looking(选举状态)
- Leading(领导者状态,表明当前server是leader)
- Following(跟随者状态,表明当前server是Follower)
- Observing(观察者状态、表明当前server是Observer)。
Zookeeper选举原理 https://www.cnblogs.com/scuwangjun/p/9063149.html
Zookeeper 数据模型
-
基于树形结构的命名空间,与文件系统类似
-
节点(znode)都可以存储数据,可以有子节点
-
节点不支持重命名
-
数据大小不超过1MB(可配置)
-
数据读写保持完整性
Znode 节点类型
PERSISTENT 持久化节点
PERSISTENT_SEQUENTIAL 顺序自动编号持久化节点,这种节点会根据当前已存在的节点数自动加 1
EPHEMERAL 临时节点, 客户端session超时这类节点就会被自动删除
EPHEMERAL_SEQUENTIAL 临时自动编号节点
自动编号节点 实际生成节点名末尾自动添加一个10位长度,左边以0填充的单递增数字,eg:address0000000442
临时节点 在客户端session结束或超时后自动删除
ZooKeeper Session
-
客户端和 server 间采用长连接
-
连接建立后, server生成 session id(64位)返还给客户端
-
客户端定期发送 ping 包来检查和保存和 server 的连接
-
一旦 session 结束或超时,所有 ephemeral节点会被删除
-
客户端可根据情况设置合适的 session 超时时间
Zookeeper Watcher
-
Watch 是客户端安装在 server 的事件监听方法
-
当监听的节点发生变化, server 将通知所有注册的客户端
-
客户端使用单线程对所有事件按顺序同步回调
-
触发回调条件:
-
客户端连接,断开连接
-
节点数据发生变化
-
节点本身发生变化
注意:
-
Watch 是单次的,每次触发后会被自动删除
-
如果需要再次监听时间,必须重新安装 Watch(Zookeeper客户端Curator可以不用每次重新安装监听)
Watch 的创建和触发规则
-
在读操作 exists、getChildren和getData上可以设置观察,这些观察可以被写操作create、delete和setData触发
参考如下: