《Designing Data-Intensive Applications》的第一部分,基于单点(single node)介绍了数据系统的基础理论与知识;在第二部分,则是将视野扩展到了分布式数据系统,主要是Partition和Repliacation。在第三部分,则聚焦于派生数据系统。
integrating multiple different data systems, potentially with different data models and optimized for different access patterns, into one coherent application architecture.
对于目前日益复杂的应用,没有哪一种单一的数据系统可以满足应用的所有需求,所以本章就是介绍如何将不同的数据系统整合到单一应用中。数据系统可以分为两类
system of record:原始数据,source of truth
derived data system:派生数据系统,即数据来自其他数据系统。派生数据系统包括但不限于:cache、索引、视图,本质上派生数据是原始数据的冗余,为了性能而做的冗余。
值得注意的是,原始数据系统与派生数据系统的区别并不在于对应的工具,而在于在应用中的具体使用方式。
The distinction between system of record and derived data system depends not on the tool, but on how you use it in your application.
本文地址:https://www.cnblogs.com/xybaby/p/9895725.html
Batch Processing
在某个层面,可以数据系统进行以下分类
- Services (online systems)
追求response time
- Batch processing systems (offline systems)
追求throughput
- Stream processing systems (near-real-time systems)
sth between online and batch system
本章讨论的是批处理系统(Batch processing),MapReduce是批处理系统的典型代表,在MapReduce的诸多设计中,都可以看到unix的一些影子。
unix哲学
- 一个程序只做一件事,做好这件事,如果有新需求,那么重新写一个程序,而不是在原来的程序上修修补补
- 尽量让每个程序的输出做其他程序的输入,即输出要通用、普适性,不要坚持交互式输入
- 设计和构造软件,即使是操作系统,都要及早尝试,对于不合理的地方,要毫不犹豫的推到重构
- 尽早借助工具来避免重复性的劳动,自动化
automation, rapid prototyping, incremental iteration, being friendly to experimentation, and breaking down large projects into manageable chunks
Separating the input/output wiring from the program logic makes
unix pipeline的最大缺陷在于这些组合工具只能在单个机器上运行,需要扩展到多个节点时,就需要Hadoop这样的分布式系统
MapReduce
与unix区别
- 从单机到多机
- stdin stdout 到 file
关于MapReduce的原理与框架,之前在《典型分布式系统分析:MapReduce》一文中描述过。下面关注一些不是在MapReduce论文中出现的一些讨论。
Joins and Grouping
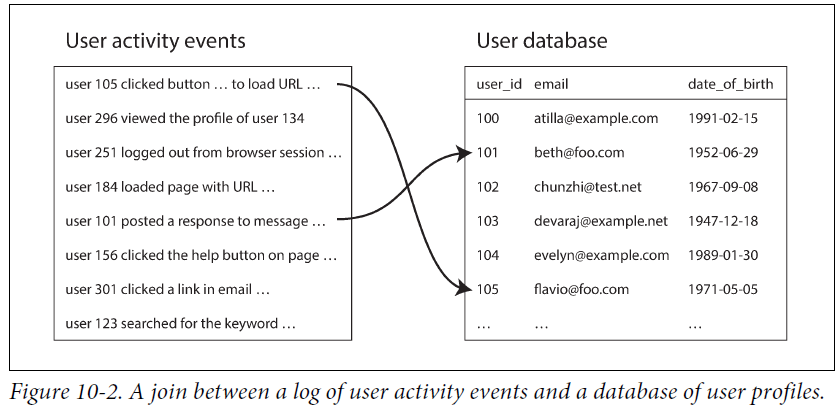
批处理中,经常也需要join操作,通过join操作来补充完整一个事件(event)。在批处理中,既可以在Map的时候join,也可以在Reduce的时候join,如下所示
 】
】
event log中只记录uid,而其他属性需要从user database(profile information)读取,这样避免了profile数据的冗余
每次通过网路去读取user profile 显然是不切实际的,拖慢批处理速度;而且由于profile 是可变的,导致批处理 结果不是确定性的。一个友好的解决办法是:冗余一份数据,放到批处理系统中。
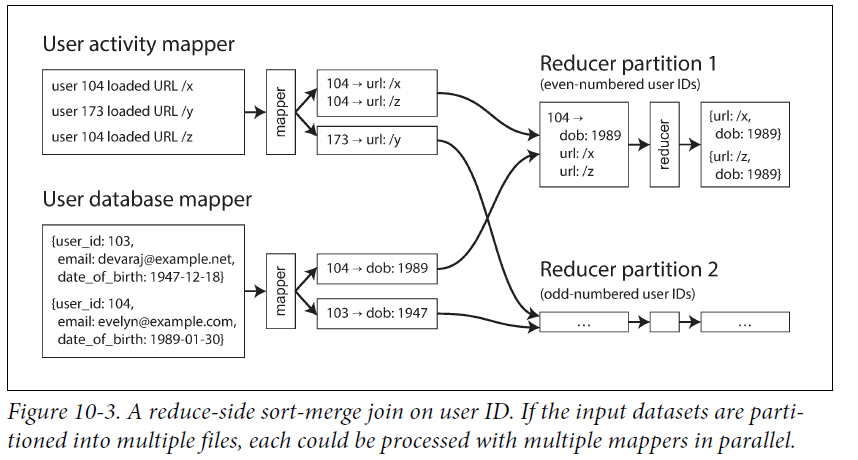
下面是一个reduce_side join的例子。称之为sort-merge join,因为不管是User event 还是 User profile都按照userID进行hash,因此都一个用户的event 和 profile会分配到都一个reducer。
批处理使用场景
- 搜索引擎 search index
关于增量创建search index,写入新的segment文件,后台批量合并压缩。
new segment files and asynchronously merges and compacts segment files in the background.
- 机器学习与推荐
一般来说,将数据写入到一个key value store,然后给用户查询
怎么讲批处理的结果导入到kvs? 直接导入是不大可能的。写入到一个新的db,然后切换。
build a brand-new database inside the batch job and write it as files to the job’s output directory in the distributed filesystem
Beyond MapReduce
MapReduce的问题
(1)比较底层,需要写大量代码:using the raw MapReduce APIs is actually quite hard and laborious
解决办法:higher-level programming models (Pig, Hive, Cascading, Crunch) were created as abstractions on top of MapReduce.
(2) mapreduce execution model的问题,如下
Materialization of Intermediate State
materiallization(物化)是指:每一个MapReduce的输出都需要写入到文件再给下一个MapReduce Task Job。
显然,materiallization是提前计算,而不是按需计算。而Unix pipleline 是通过stream按需计算,只占用少量内存空间。
MapReduce相比unix pipeline缺陷
- MapReduce job完成之后才能进行下一个,而unix pipeline是同时执行的
- Mapper经常是多余的:很多时候仅仅是出去上一个reducer的输出
- 中间状态的存储也是要冗余的,有点浪费
dataflow engines如Spark、Tez、Flink试图解决Mapreduce问题的
they handle an entire workflow as one job, rather than breaking it up into independent subjobs.
dataflow engines 没有明显的map reduce , 而是一个接一个的operator。其优势:
- 避免了无谓的sort(mr 在map和reduce之间总是要sort)
- 较少非必需的map task
- 由于知道整个流程,可以实现locality optimizations
- 中间状态写入内存或者本地文件,而不是HDFS
- operator流水线工作,不同等到上一个stage完全结束
- 在运行新的operator时,可以复用JVM
Stream Processing
批处理与流处理的最大区别在于,批处理的输入是确定的、有限的,而流处理的输入是源源不断的,因此流处理系统一般比批处理系统有更好的实时性。
流处理相关术语
event:In a stream processing context, a record is more commonly known as an event
producer、publisher、sender
consumer、subscriber、recipient
topic、stream,一组相关event
messaging system
用于事件发生时,通知消费者,对于某个topic 一般是多生产者 多消费者。
如何对消息系统分类:
(1)What happens if the producers send messages faster than the consumers can process them?
第一个问题,生产速度大于消费速度,对应的处理方式包括:丢包、缓存、流控(限制写入速度)
(2)What happens if nodes crash or temporarily go offline—are any messages lost?
第二个问题,当节点crash或者临时故障,消息会不会丢
event如何从producer到达consumer
(1)直达消息系统(没有中间商)
即一个event直接从producer到达consumer,如UDP广播,brokerless : zeroMQ,这样的系统有消息丢失的风险。
(2)message broker(message queue)
定制化的DB
异步过程
保证消息可靠性
multi consumer
shared subscriptions,一条消息任意一个consumer处理即可;负载均衡;可扩展性
topic subscriptions 一条消息需要被不同的comsumer消费
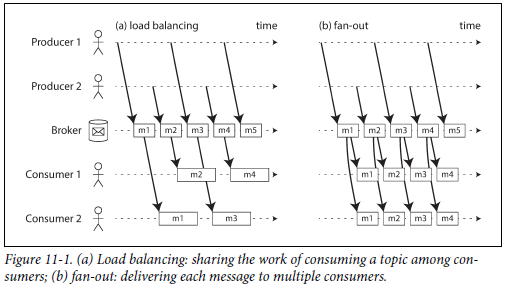
上图(a)中的event只需要被任意一个consumer消费即可,而(b)中的每一个event则需要被所有关注该topic的consumer处理
Acknowledgments and redelivery
需要consumer的ack来保证消息已被消费,消息可能会被重复投递,因此需要幂等性
当 load balancing遇上redeliver,可能会出现messgae 乱序
logbased message brokers
一般的消息队列都是一次性消费,基于log的消息队列可以重复消费
The log-based approach trivially supports fan-out messaging, because several consumers can independently read the log without affecting each other—reading a message does not delete it from the log
其优点在于:持久化且immutable的日志允许comsumer重新处理所有的事件
This aspect makes log-based messaging more like the batch processes of the last chapter, where derived data is clearly separated from input data through a repeatable transformation process. It allows more experimentation and easier recovery from errors and bugs, making it a good tool for integrating dataflows within an organization
Databases and Streams
在log-based message broker有数据库的影子,即数据在log中,那么反过来呢,能否将message的思想应用于db,或者说db中是否本身就有message的思想?
其实是有的,在primary-secondary 中,primary写oplog, produce event;secondary读oplog, consume event。
Keep Systems in Sync
一份数据以不同的形式保存多分,db、cache、search index、recommend system、OLAP
很多都是使用full database dumps(batch process),这个速度太慢,又有滞后; 多写(dual write)也是不现实的,增加应用层负担、耦合严重。
Change Data Capture
一般来说,应用(db_client)按照db的约束来使用db,而不是直接读取、解析replication log。但如果可以直接读取,则有很多用处,例如用来创建serach index、cache、data warehouse。
如下图所示
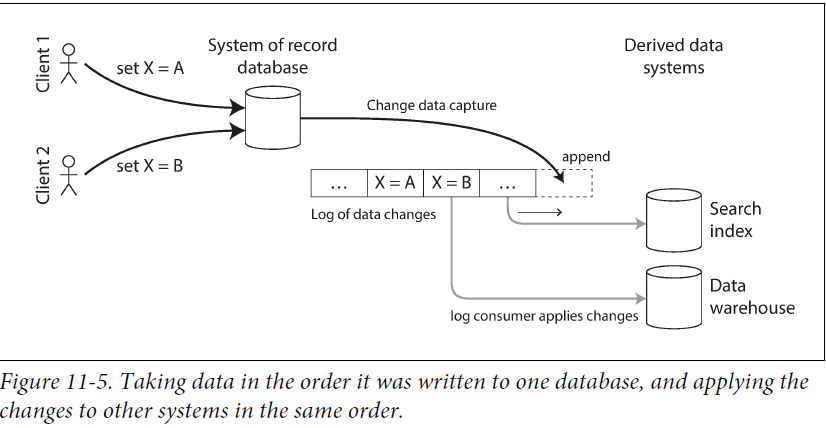
前面是DB(leader),中间是log-based message broker,后面是derived data system(cache, data warehouse) as followers
这样做的潜在问题是,日志会越来越多,耗光磁盘,直接删除就的log也是不行的,可以周期性的log compaction:处理对一个key重复的操作,或者说已经被删除的key。这样也能解决新增加一个consumber,且consumber需要所有完整数据的情况。
Event Sourcing
event sourcing involves storing all changes to the application state as a log of change events.
CDC在数据层记录,增删改查,一个event可能对应多个data change;mutable
event sourcing 在应用层记录,immutable(不应该修改 删除)
event soucing 一般只记录操作,不记录操作后的结果,因此需要所有数据才能恢复当前的状态
周期性的snapshot有助于性能
Commands and events: 二者并不等价,Command只是意图(比如想预定座位),只有通过检查,执行成功,才会生成对应的event,event 代表 fact
State, Streams, and Immutability

上图非常有意思:state是event stream的累计值,积分的效果,而stream是state的瞬时值,微分的效果
Advantages of immutable events
- immutable event log 有利于追溯到任意时间点,也可以更容易从错误中恢复
- immutable event log 比当前状态有更多的信息:用户添加物品到购物篮,然后从购物篮移除;从状态来看,什么都没有发生,但event log却意义丰富
- Deriving several views from the same event log 当有event log,很容易回放event,产生新的数据视图,而不用冒险修改当前使用的数据视图,做到灰度升级
Processing Streams
数据流应用广泛:
- 写到其他数据系统:db、cache等
- 推送给用户,或者实时展示
- 产生其他的数据流,形成链路
stream processing 通常用于监控:风控、实时交易系统、机器状态、军事系统
CEP(Complex event processing)是对特定事件的监控,对于stream,设置匹配规则,满足条件则触发 complex event
In these systems, the relationship between queries and data is reversed compared to normal databases.
DB持久化数据,查询是临时的
而CEP持久化的是查询语句,数据时源源不断的
Reasoning About Time
批处理一般使用event time,而流处理可能采用本地时间(stream processing time),这可能导致不准确的时间窗口(尤其两个时间差抖动的时候)
以event time作为时间窗口的问题:不确定是否收到了某个window内所有的event。
通常,需要结合使用本地时钟与服务器时钟,考虑一个情况,客户端采集日志发送到服务器,在未联网的时候本地缓存。如果用本地时间,本地时间可能不准,用服务器时间,不能反映事件发生的时刻(可能过了很长时间才从缓存发送到服务器),解决办法:
- 用device clock记录事件发生时间;
- 用device clock记录事件上传时间;
- 用server clock记录服务器收到event的时间
用(3)减去(2)可以得到时间偏差(忽略了网络延时),在用(1)加上这个时间偏差就得到了事件的真正发生时间。
Types of windows
- 滚动 tumbling window
正交的时间块,一个5分钟,接下来又一个5分钟
- 跳动 hopping window
相交的时间块,5分钟,然后前进1分钟,有一个5分钟
- 滑动 Sliding window
无固定的边界,一点点向前滑
Stream Joins
流处理系统中也是需要一些join操作
- stream-stream joins
for example.click-through rate 网页搜索、点击事件
- stream-table joins(stream enrichment)
a set of user activity events and a database of user profiles
- Time-dependence of joins
if events on different streams happen around a similar time, in which order are they processed?
比如跨境交易,汇率是实时变化的,那么交易事件与事件发生时间的汇率绑定。解决办法是 交易事件里面维护当时的汇率id,但这导致没法做log compaction
Fault Tolerance
stream processing system的容错性,batch processing 可以做到 exactly-once semantics,虽然可能会有失败-重试。对于流处理
- Microbatching and checkpointing 做到了可重试
- Idempotence 保证了可重复执行
The Future of Data Systems
Data Integration
the most appropriate choice of software tool also depends on the circumstances.
in complex applications, data is often used in several different ways. There is unlikely to be one piece of software that is suitable for all the different circumstances in which the data is used
复杂的应用可能需要集成多个数据系统,让单个数据系统各司其职,那么如何保证多个数据系统数据的一致性:以其中一个数据系统为准(Primary),然后通过CDC或者event sourcing复制到其他数据系统。
Derived data versus distributed transactions
分布式事务通过互斥锁决定写操作顺序;而CDC 使用log来保证顺序
分布式事务通过atomic保证只生效一次;而log based依赖于确定性的重试与幂等
The lambda architecture
batch processing is used to reprocess historical data, and stream processing is used to process recent updates, then how do you combine the two?
结合批处理与流处理
- 批处理:慢但是准确
- 流处理:快速但不一定精确
潜在的问题:
- 在batch、stream processing framework上维护两份一样的逻辑
- batch pipeline、stream pipeline输出不同,导致读取的时候需要merge
- 增量batch 需要解决时间窗口、stragglers 问题
解决办法如下:Unifying batch and stream processing
Unbundling Databases
Unix and relational databases have approached the information management problem with very different philosophies.
Unix 提供了是比较底层的对硬件的封装,thin wrapper; 而relationaldb 对程序员提供high-level抽象
Composing Data Storage Technologies
it seems that there are parallels between the features that are built into databases and the derived data systems that people are building with batch and stream processors.
数据库的feature(secondary index、view、replication log, full-text search index)与 derived data system有一些类似之处
以创建新索引为例:
- 快照,然后处理已有数据
- 处理在上一步过程中新加入的数据
- 索引创建完毕,处理后续数据
这个过程类似于
- 增加新的secondary(follower)
- 在流处理系统中增加新的消费者
Observing Derived State
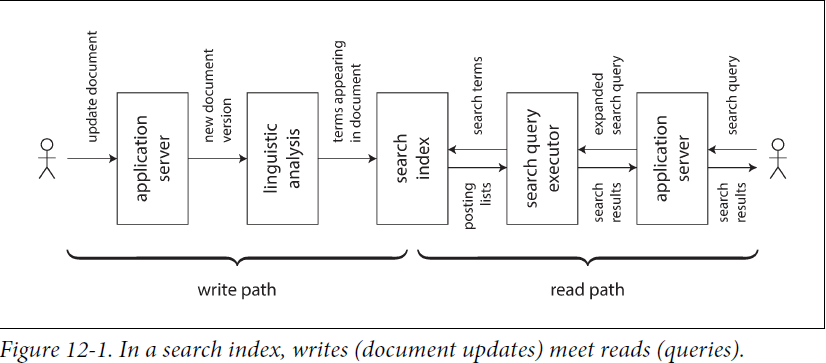
write path:precomputed; eager evaluation
whenever some piece of information is written to the system, it may go through multiple stages of batch and stream processing, and eventually every derived dataset is updated to incorporate the data that was written
read path:lazy evaluation
when serving a user request you read from the derived dataset, perhaps perform some more processing on the results, and construct the response to the user.
The derived dataset is the place where the write path and the read path meet, as illustrated in Figure 12-1. It represents a trade-off between the amount of work that needs to be done at write time and the mount that needs to be done at read time.
derived dataset是write path与read path连接的地方,是写入时处理与读取时工作量的折中。caches, indexes, and materialized views 都是在write path上多做一些工作,减轻read path负担
写 与 读的折中;twinter的例子,名人 普通人策略不一样
Stateful, offline-capable clients
当前互联网应用都是client server模式,client无状态,数据都在server;但single path application或者mobile app在断网的时候也能使用,提供更好的用户体验;而且,web-socket等技术提供了server主动向client推送的能力,这就是的write-path 进一步扩展到了客户端
大多数的db,lib,framework、protocol都是按照staleless and request/response的思想来设计的,根深蒂固
In order to extend the write path all the way to the end user, we would need to fundamentally rethink the way we build many of these systems: moving away from request response interaction and toward publish/subscribe dataflow
Aiming for Correctness
build applications that are reliable and correct
In this section I will suggest some ways of thinking about correctness in the context of dataflow architectures.
The End-to-End Argument for Databases
即使使用了强事务性,也不能保证数据不会有问题,因为由于代码bug、人为错误,导致数据的损坏 丢失,immutable and append-only data helps
考虑一个复杂的问题 exactly-once
其中一个解决办法:Idempotent(幂等)。 但需要额外的一些工作,而且需要非常细心的实现
TCP的seq number也是为了保证excat once, 但这只对单个TCP连接生效
In many databases, a transaction is tied to a client connection。 If the client suffers a network interruption and connection timeout after sending the COMMIT, but before hearing back from the database server, it does not know whether the transaction has been committed or aborted。
2pc break the 1:1 mapping between a TCP connection and a transaction,因此 suppress duplicate transactions between the database client and server;但是end-user与 application server之间呢
终极解决办法,Unique Operation ID
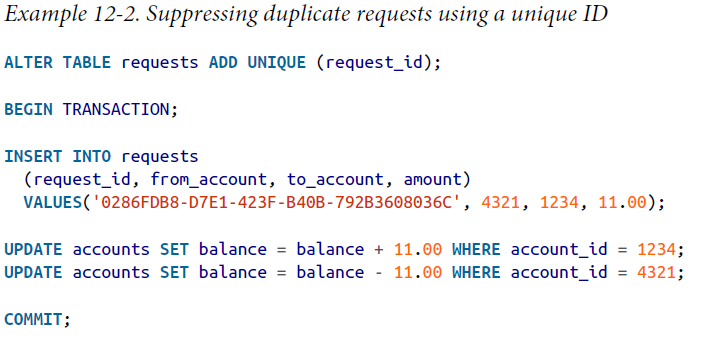
Besides suppressing duplicate requests, the requests table in Example 12-2 acts as a kind of event log, hinting in the direction of event sourcing
除了保证点到点的约束,也充当了event log,可以用于event sourcing
Enforcing Constraints
约束:如unique constraint,账户余额不能为负等
通过consume log来实现约束:
Its fundamental principle is that any writes that may conflict are routed to the same partition and processed sequentially
Timeliness and Integrity
consistency可能包含两重意义
及时性(Timeliness ):user读取到的是实时状态
完整性(Integrity):user读取到的是完整的状态
violations of timeliness are “eventual consistency,” whereas violations of integrity are “perpetual inconsistency.”
ACID同时保证及时性与完整性,但基于时间的数据流一般不保证及时性,exactly-once保证完整性
在数据流系统如何保证完整性?
(1) 写操作是一个单一的message,原子性写入
(2)derived datasystem从单一消息确定性地提取状态
(3)客户端生成reqid,在整个流程用整个reqid保证幂等性
(4)单一消息不可变,持久化,允许derived datasystem重新处理所有消息
尽量避免协调的数据系统 Coordination-avoiding data systems
(1)数据流系统通过derived data,无需原子性提交、线性、跨分片的同步协调就能保证完整性
(2)虽然严格的unique 约束要求实时性(timeliness)和协调,很多应用可以通过事后补偿放松约束
Trust, but Verify
对数据完整性的校验,防止数据默默出错silent corruption,多副本不能解决这个问题
基于事件的系统提供了更好的可审计性, 如记录A给B转账,比记录A扣钱,B加钱更好
Checking the integrity of data systems is best done in an end-to-end fashion
Doing the Right Thing
软件和数据大大影响了我们生存的世界,对于我们这些工程师,需要承担起责任:创建一个充满人文关怀和尊重的世界。