在弄清楚yarn是什么之前,先来看一下MRv1。
它的由编程模型+数据处理引擎(map/reduceTask)+运行时环境组成(JobTracker/TaskTracker)。其中JobTracker存在很多问题,如下:
1、JobTracker本身承担了调度和计算的任务,太累了
2、JobTracker是单点的,不好扩展不能支持其他计算框架,还有单点故障风险
3、资源是以槽位的方式来调度。粗粒度,不合理。比如提交了一个特别占用资源的任务,整个节点就被占用了。还有map阶段往往reduce槽位就是闲置,反之也是这样。
针对以上问题,MRv2做了以下优化:
1、拆分为资源调度和作业管理两个独立的服务。
2、可以部署集群,可以在yarn上运行其他框架(比如内存计算、流式计算)
3、资源的管理方式是Container,他是一组硬件资源(内存、cpu)等的集合。控制的更细粒度。
这样,新版MRv2,的组成为:编程模型+数据处理引擎(map/reduceTask)+运行时环境组成(yarn),前两者基本实现原理不变。
yarn的概念呼之欲出:
YARN 是Hadoop 2.0 中的资源管理系统,它是一个通用的资源管理模块,可为各类应
用程序进行资源管理和调度。
1、管理系统资源(ResourceManager)
2、管理作业(监控、容错)(ApplicationMaster)
YARN 不仅限于MapReduce 一种框架使用,也可以供其他框架使用。
yarn都包含哪些基本模块呢?
1、ResourceManager(RM) 全局资源管理器。负责资源的管理和分配。
2、ApplicationMaster(AM)应用程序主管,每一个作业对应一个。协调资源,分配任务,与NM通信启动任务,监控任务等。
3、NodeManager(NM)各个节点上的资源管理器。它有两个作用,监控本机资源使用情况汇报到RM;接收来自AM的Container启动/停止等指令
4、Container逻辑意义上的资源隔离机制。
其中,RM有两个主要组成模块:
1、Scheduler调度器
2、ApplicationManager应用程序管理器,作用是接收作业->向Scheduler请求资源(Container)分配给AM->启动AM->监控AM->容错AM。
学习yarn,主要应该从以下几个类入手:
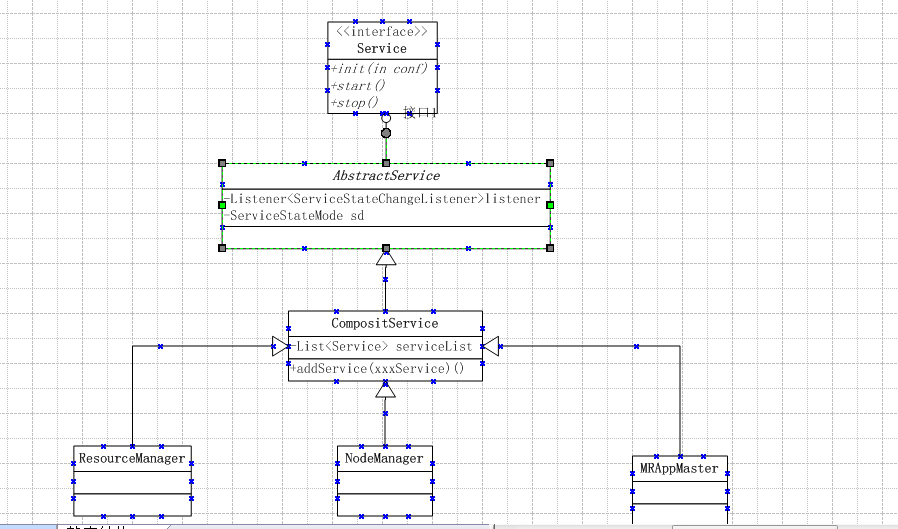
Job,ResourceManager,NodeManager,MRAPPMaster,YarnClient,MapTask,ReduceTask
其中ResourceManager,NodeManager,MRAPPMaster是类似的实现机制。都是服务模型,都是事件监听机制。如下图:
本篇主要介绍了yarn的组成模块,下一篇将从代码级别分析一个job提交过程。