1、索引失效
2、SQL性能优化四步
3、查询优化--小表驱动大表
4、查询优化--order by关键字优化
5、查询优化--group by关键字优化
6、慢查询日志分析--开启慢查询日志
7、MySQL日志分析工具 mysqldumpslow
8、show profiles
9、全局查询日志
1、索引失效 <--返回目录
1)全值匹配我最爱:查询条件于符合索引顺序
2)最佳左前缀法则:如果索引了多列,要遵守最左前缀法则,即查询where子句从索引的最左前列开始并且不跳过索引中的列(带头大哥要有,中间兄弟不能断)
3)不在索引列上做任何操作(计算、函数、自动或手动类型转换),因为这样会导致索引失效而转向全表扫描
4)存储引擎不能使用索引中范围条件右边的列
比如:创建符合索引 idx_staffs_name_age_pos(name, age, pos), 如果查询条件是 where name='xxx' and age > 10 and pos='xxx', 则因为 age > 10 是范围查询,导致idx_staffs_name_age_pos后面的索引列用不上索引(age这个索引列还是能用上的)。
5)尽量使用覆盖索引(只访问索引查询,索引列和查询列一致),少用 select *
6)mysql在使用不等于(!=, <>)时无法使用索引导致全表扫描
7)is null, is not null 也无法使用索引
8)like 以 '%xxx' 通配符开头,导致索引失效,(如果like 'xxx%',查询ref=range)
问题:解决like '%xxx%'时索引不被使用? 解决:使用覆盖索引
9)字符串不加单引号索引失效
10)少用or,用它来连接时会索引失效
2、SQL性能优化四步 <--返回目录
1)慢查询的开启并捕获
2)explain+慢SQL分析
3)show profile 查询 SQL 在 mysql 服务器里面的执行细节和生命周期情况
4)SQL 数据库服务器的参数调优
3、查询优化--小表驱动大表 <--返回目录
select * from A where exists (select 1 from B where A.id=B.id): 该语法理解 将主查询的数据,放到子查询中做条件验证,根据结果来决定主查询的数据结果是否得以保留。

4、查询优化--order by关键字优化 <--返回目录
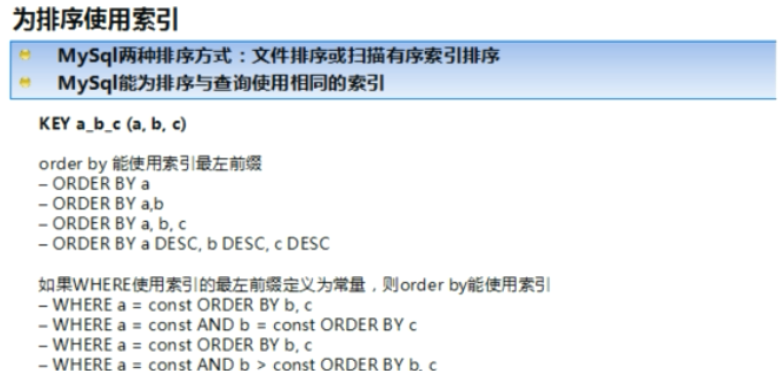
mysql 支持两种方式的排序,FileSort 和 Index。Index 效率高,它指 MySQL 扫描索引本身完成排序。FileSort效率较低。
order by 满足两情况,会使用 Index 方式排序:
1) order by语句使用索引最左前列
2) 使用 where 子句与 order by 子句条件列满足索引最左前列
如果不在索引列上,filesort 有两种算法:
1)双路排序:MySQL4.1 之前是使用双路排序,意思是两次扫描磁盘,最终得到数据,读取行指针和order by列,对它们排序,然后扫描已经排好序的列表,按照列表中的值重新从列表中读。从磁盘取排序字段,在buffer进行排序,再从磁盘取其他字段。两次扫描磁盘,IO耗时,所以在MySQL4.1之后,出现了第二种改进的算法,就是单路排序。
2)单路排序:从磁盘读取查询需要的所有列,按照order by列对它们进行排序,然后扫描排序后的列表进行输出,它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用更多了内存空间,因为它把每一行都保存在内存中。
问题:在 sort_buffer 中,单路排序比双路排序要多占用更多空间,因为单路排序把所有字段都取出,所以有可能取出的数据的总大小超出了sort_buffer的容量,导致每次只能取sort_buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再取sort_buffer容量大小,再排。。。从而多次IO。本来想省一次IO操作,反而导致了大量的IO操作,反而得不偿失。
优化策略:增大sort_buffer_size参数的设置,增大max_length_for_sort_data参数的设置

order by总结
1)order by 和 where查询条件组合符合最佳左前缀法则
2)order by a desc, b asc:这要会导致filesort
3) 入伙
5、查询优化--group by关键字优化 <--返回目录
与order by类似
group by 实质是先排序后进行分组,遵照索引键的最佳左前缀
当无法使用索引列,增大max_length_for_sort_data参数的设置和增大sort_buffer_size参数的设置
where高于having,能写在where限定的条件就不要写在having限定。
6、慢查询日志分析--开启慢查询日志 <--返回目录
慢查询日志:是 MySQL 提供的一种日志记录,用来记录在 MySQL 中响应时间超过阈值的语句,具体指运行时间超过 long_query_time 值的SQL,则会被记录到慢查询日志中。long_query_time默认值为10s。默认情况下,MySQL 没有开启慢查询日志,需要我们手动开启设置。当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件。
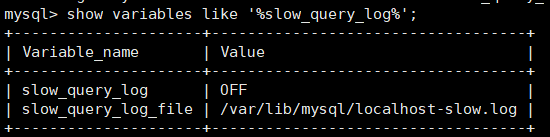
查看是否开启及如何开启:show variables like '%slow_query_log%';
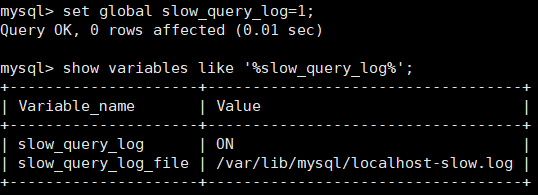
开启:set global slow_query_log=1; (只对当前数据库生效,并且重启mysql服务后失效)
如果要永久生效,就必须修改配置文件 my.cnf(其他系统也是如此)。修改my.cnf文件,在[mysqld]下增加或修改参数:
[mysqld] slow_query_log=1 slow_query_log_file=/var/lib/mysql/slow.log
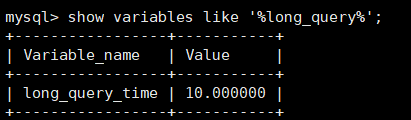
查看慢查询阈值时间:show variables like 'long_quer';
修改慢查询阈值时间: set global long_query_time=3;
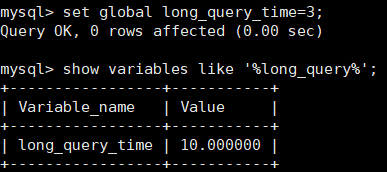
重新连接或新开一个会话,才能看到生效的结果
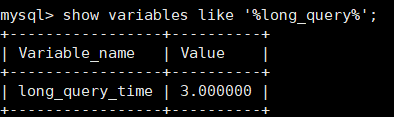
查看记录的慢查询日志:
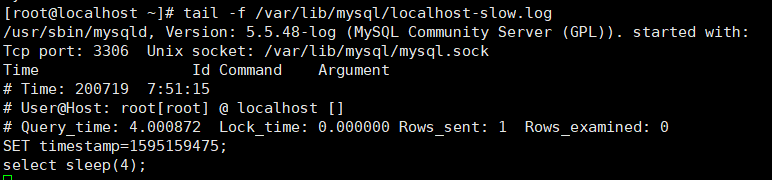
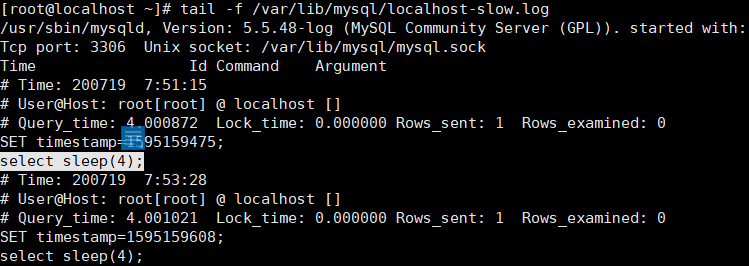
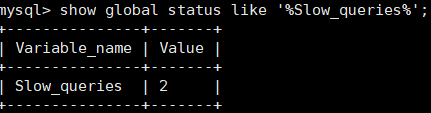
查看当前系统有多少条慢查询日志:show global status like '%Slow_queries%';
总结,开发时开启,线上不开启。开发时在 my.cnf配置
[mysqld] slow_query_log=1 slow_query_log_file=/var/lib/mysql/slow.log long_query_time=3 log_output=FILE
7、MySQL日志分析工具 mysqldumpslow <--返回目录
mysqldumpslow --help
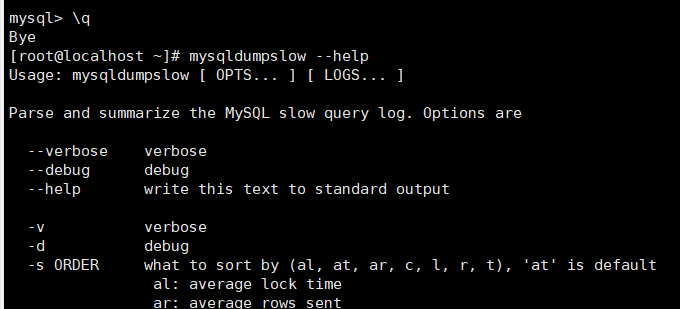

常见用法:

mysqldumpslow -s r -t 10 /var/lib/mysql/localhost-slow.log

8、show profiles <--返回目录
show profiles: 是 MySQL 提供用来分析当前会话中语句执行的资源消耗情况。可以用于 SQL 调优的测量。
官网:http://dev.mysql.com/doc/refman/5.5/en/show-profile.html
默认该参数处于关闭状态,并保存最近15次的运行结果。
查看 MySQL 是否支持:show variables like '%profiling%';
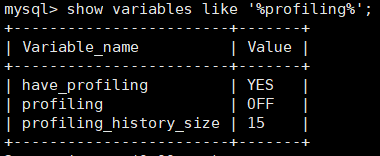
开启:set profiling=on;
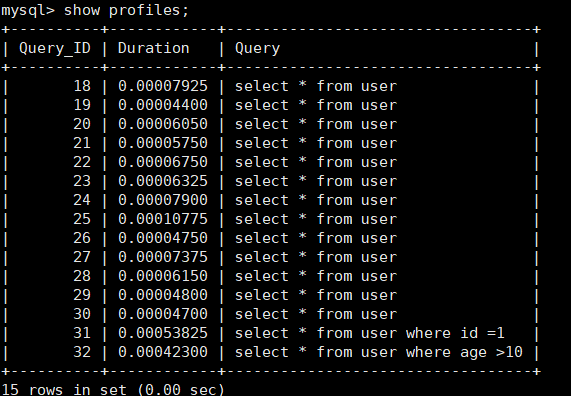
查看SQL语句执行的总时长:show profiles
诊断SQL(查看SQL执行生命周期中的每一步花费时长): show profile cpu,block io for query [Query_ID];
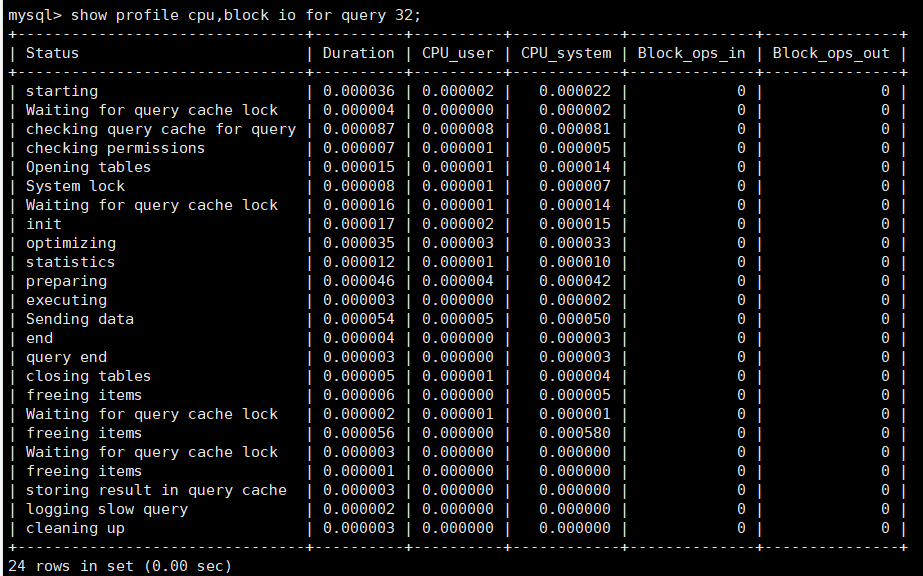
诊断SQL结果分析:(出现哪些情况表明SQL有问题?)

9、全局查询日志 <--返回目录
全局查询日志:永远不要在生产环境使用。
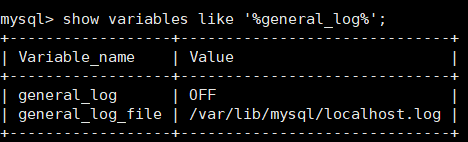
查看:show variables like '%general_log%';
开启:set global general_log=1;
set global log_output='TABLE';
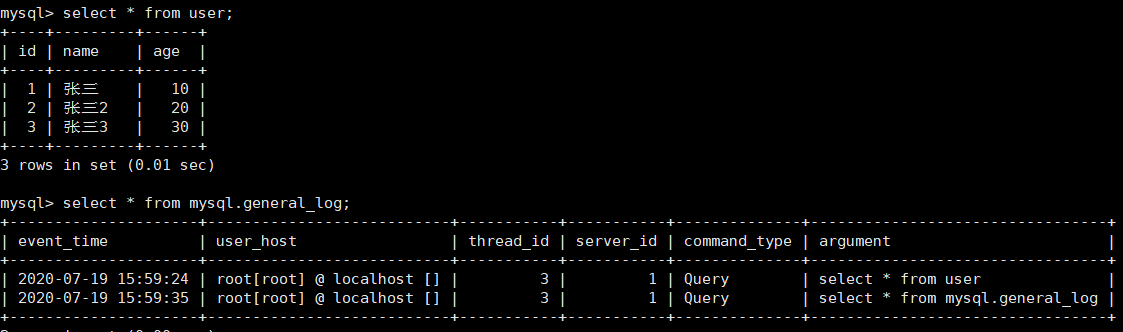
开启全局日志查询后,所有执行的 SQL 语句,将会记录到 MySQL 库里的general_log 表,可以使用命令查看:select * from mysql.general_log;
my.cnf 配置:
general_log=1
general_log_file=/var/lib/mysql/all.log
log_output=FILE
---