第一步:新建一个映射,以保存原来的chrome不被污染
- 添加环境变量
将chrome.exe放入系统环境变量中,找到驱动位置添加变量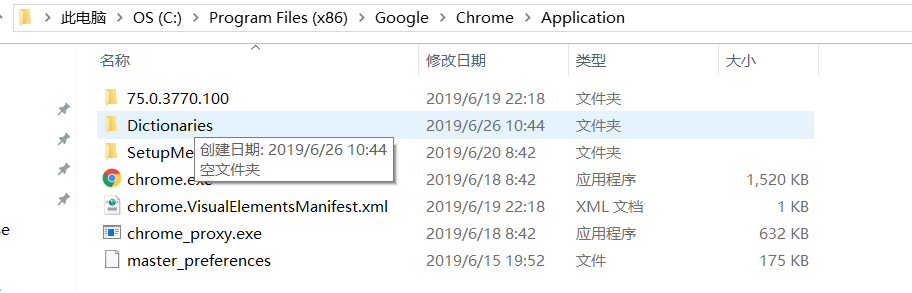
- 新建一个存放新环境的文件夹并映射
使用指令【chrome.exe --remote-debugging-port=9222 --user-data-dir="E:data_infoselenium_data"】
其中--remote-debugging-port是建立新的移植位置,其中端口后面会使用(自定义), --user-data-dir是数据存储的目录(自定义)
此时会打开一个网页放着就行
第二步:selenium代码接管
通过下面的代码就可以登录知乎

import time
import json
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
class ZhiHu:
def __init__(self):
self.url = 'https://www.zhihu.com/'
self.chrome_options = Options()
self.chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222") # 前面设置的端口号
self.browser = webdriver.Chrome(executable_path=r'E:Environmentpython_globalScriptschromedriver.exe', options=self.chrome_options) # executable执行webdriver驱动的文件
def get_start(self):
self.browser.get(self.url)
# time.sleep(20) # 可以选择手动登录或者是自动化,我这里登录过就直接登陆了
info = self.browser.get_cookies() # 获取cookies
print(info)
with open(r"..download_txtinfo.json", 'w', encoding='utf-8') as f:
f.write(json.dumps(info))
if __name__ == '__main__':
zhihu = ZhiHu()
zhihu.get_start()
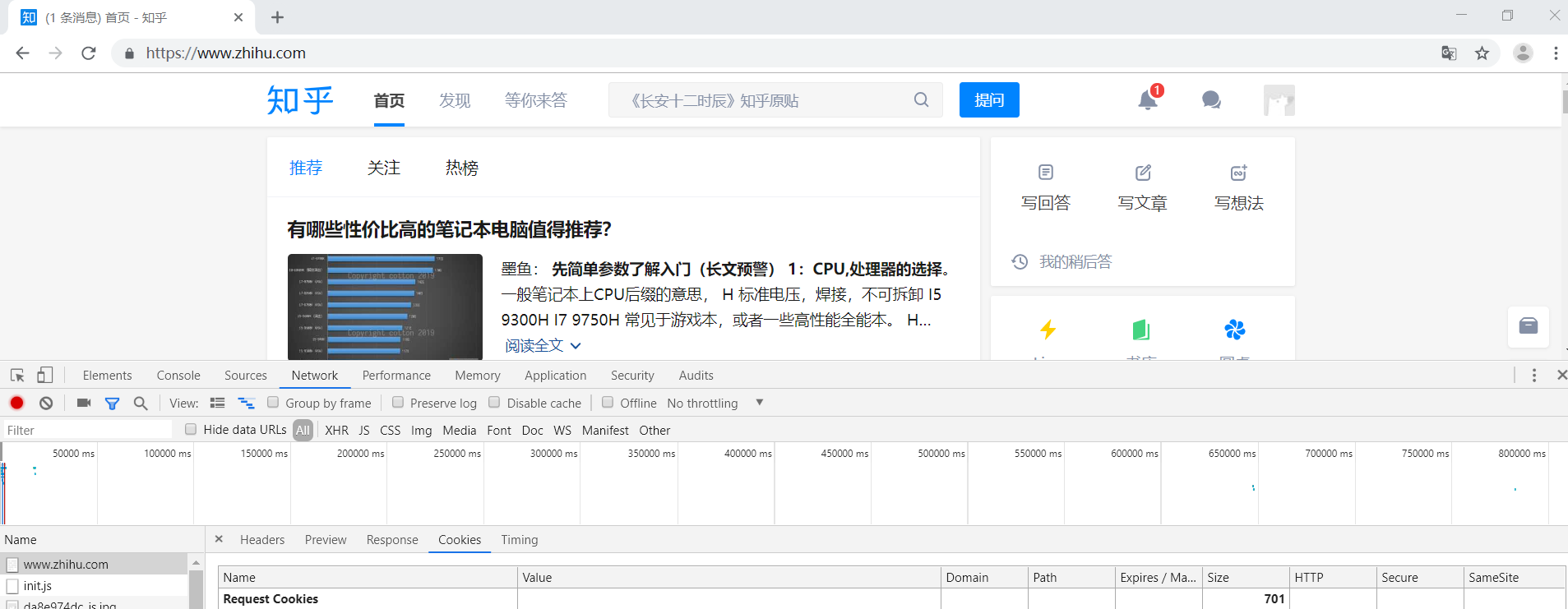
三、结果展示