一.概要部分
1.代码能符合需求和规格说明么?
经过我自己的测试和助教的检测,他的代码符合需求和规格的说明。
2.代码设计是否有周全的考虑?
这里代码设计我们是从两个方面检查的:
- 对方处理控制台输入的逻辑是不是考虑全面:
经过我的分析和他的解释,我可以得到他的处理控制台输入的逻辑是这样的:
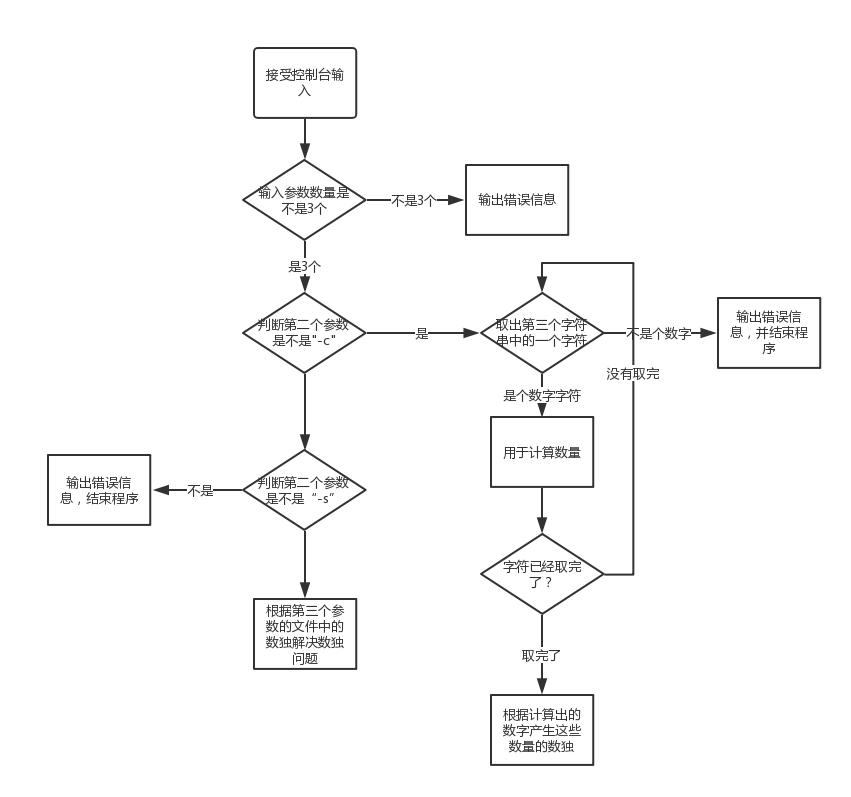
画了逻辑图就可以看出处理输入的这部分大致判断逻辑已经很完备了,还可以再更完备:
输入的数字的范围处理:对于输入的生成数独的数量,规定是N范围在1到100万之间,但是上面的逻辑并没有对输入的数字字符串做这方面的可能超出范围的检测。比如对于一段超长的数字字符串,超过了最大int的范围,这时就会产生错误。
具体的comment在:https://github.com/Liu-SD/sudoku/commit/cd48b384a93b39bda48a74d8f37096211f9594bc
- 可扩展性怎样?
较好的可扩展性需要代码模块之间的松耦合,模块内部的高聚合。在这次的作业中,我觉得大致可以分为这么几个大的模块:命令行参数处理模块,数独生成模块,数独解决模块,最后的结果写入模块。
经过仔细的检查,觉得我们在这方面的实现还不太完善,因为:
1.并没有把命令行参数处理模块化,而是直接把数独生成和数独解决这两个过程写在了main函数的if else逻辑中。这样命令行参数这个处理过程与数独的生成和解决耦合性过大。
2.最后文件的写入没有和数独生成/解决分开。
所以这里我们都需要改进。
3.代码可读性如何?
总体来讲,我觉得他的代码满足简明,易读,无二义性的基本原则。我从两个方面评判他的代码可读性:
- 命名规范:
我觉得他的代码命名简洁明了:
例如:
int val, pos_row, pos_col;
整体上都是采用单词和单词之间加下划线的表示方法。
- 单词与单词之间的空隙:
他的缩进让代码整体上看起来很舒服,例如:
A = new cross_link(rownum, colnum); rows = A->rows; cols = A->cols; head = A->head; for (int i = 0; i < rownum; i++) { int val = i % 9 + 1; int pos = i / 9; int row = pos / 9; int col = pos % 9; int block = (row / 3) * 3 + (col / 3); A->insert(i, pos); A->insert(i, 81 + row * 9 + val - 1); A->insert(i, 81 * 2 + col * 9 + val - 1); A->insert(i, 81 * 3 + block * 9 + val - 1); }
还有其他的分行,括号等用的都很好,但是有个缺点我觉的就是注释太少。
4.代码容易维护么?
因为之前说的封装性不够,注释少,所以我觉得代码的可维护性还不够,还需要加强。
二.设计规范部分
1.设计是否遵从已知的设计模式或项目中常用的模式?
目前因为完成的功能较少,所以还没有用到特别明显的设计模式。
2.有没有硬编码或字符串/数字等存在?
还是有一些硬编码的存在的,例如:
- 左上角数字题目要求固定,但是我觉得需要使用特别的常量标识符来代替它
rstr[0][0] = 3;
- 最后写入文件时,必须要先计算好每一行所需要写的字符数19,我觉得这个数字也可以用更明白的方式表示出来
str[i * 19 + 2 * j + 1] = ' ';
3.代码有没有依赖于某一平台,是否会影响将来的移植(如Win32到Win64)?
根据我和他的讨论,应该对平台没有依赖性。
4.开发者新写的代码能否用已有的Library/SDK/Framework中的功能实现?在本项目中是否存在类似的功能可以调用而不用全部重新实现?
根据交流和检查的结果,在他的代码中没有这样的可以直接调用库函数的功能。
5.有没有无用的代码可以清除?
确实还有一些无用代码是可以清除的。
三.具体代码部分
1.有没有对错误进行处理?对于调用的外部函数,是否检查了返回值或处理了异常?
目前还没有调用外部的函数,所以还没有这方面的检查。而且目前还没有太多的错误处理,只有在main函数中的命令行参数处的错误处理。
2.参数传递有无错误,字符串的长度是字节的长度还是字符(可能是单/双字节)的长度,是以0开始计数还是以1开始计数?
参数传递目前检查结果来看没有错误,字符串的长度是单字节。
3.边界条件是如何处理的?Switch语句的Default是如何处理的?循环有没有可能出现死循环?
- 代码中没有发现switch语句
- 边界条件在他的代码中有这么几处,①链表的结尾,我查看了都加了不为NULL的判断②数独本身9*9的限制,也都处理的很好
- 对于他的每个for循环,首先我可以确定他的每一个循环的循环变量在循环体的执行中都不会改变,这样循环变量的改变只有for()的变化了,然后我可以确定他的循环终止条件都是正确的,所以不可能出现死循环
- 对于他在读文件时用的while循环,使用的判断条件是:getline函数的返回值。getline函数在读到文件结尾时,会返回false,不会出现死循环。
4.有没有使用断言(Assert)来保证我们认为不变的条件真的满足?
经过检查,代码中没有断言。
5.对资源的利用,是在哪里申请,在哪里释放的?有没有可能导致资源泄露(内存、文件、各种GUI资源、数据库访问的连接,等等)?有没有可能优化?
检查了他的代码中的资源申请,有这么几处
- 文件流的打开和结束。检查发现他的写入文件流最后没有close,数独解决时读入题目的文件流也没有close。
具体的comment在https://github.com/Liu-SD/sudoku/commit/efdf472f4b7e05fb688a01c82366d42b2bc3852d
- 对于cross_link对象(具体的数据结构)和dlx对象(解数独和生成数独的对象),在析构函数中都定义好了相应的释放资源的逻辑。所以这里没有问题。
6.数据结构中是否有无用的元素?
经过细致的检查,他的代码中的数据结构只有这个;
typedef struct cross_node { cross_node *left; cross_node *right; cross_node *up; cross_node *down; bool ishead; int count; int row; int col; } *Cross;
其中包括四个方向上的指针,这个是有用的;
还有是否为头指针的判断ishead,这个也是有用的;
count成员是对于头结点来说的,头结点需要记录这一行或者这一列有多少个有效节点,这个也是有用的;
row,col表示节点所在的行,列。
综上,数据结构都是有用的,可能count只对于头结点有用,对非头结点无用,有点冗余。但是如果不同意写起来的话,可能需要定义两种数据结构了,所以还是统一写起来会实现的更好吧。
四.效能
1.代码的效能(Performance)如何?最坏的情况是怎样的?
DLX算法本质上也是递归回溯的算法,所以最坏的情况可能是对于一些数独初局,回溯搜索太多。因为搜索是按照一定的顺序比如1-9来搜索的,所以固定的搜索顺序可能导致找到解之前已经回溯了大量的分支了。
2.代码中,特别是循环中是否有明显可优化的部分(C++中反复创建类,C#中string的操作是否能用StringBuilder 来优化)?
经过检查,他的代码中没有反复创建类这个过程,无论是数独的解决和生成都是只创建一个类。
3.对于系统和网络调用是否会超时?如何处理?
目前还不涉及系统和网络的调用。
五.可读性
1.代码可读性如何?有没有足够的注释?
他的代码确实没有足够的注释,但是命名清晰,可读性还可以。
六.可测试性
1.代码是否需要更新或创建新的单元测试?
他实现的单元测试有:
- 生成数独功能的单元测试
- 解决数独功能的单元测试
- CrossLink_insert的单元测试
- CrossLink_delAndRecover的单元测试
在代码更新后,可能会增加一些模块功能,可以为他们创建新的单元测试。
2.还可以有针对特定领域开发(如数据库、网页、多线程等)的核查表。
目前还不涉及特定领域的开发。
七.看了Google C++ Style规范后的心得
因为我使用了c++来编码,所以我参考了google的C++编码规范。因为刚接触C++所以其中有很多规范还没太看懂,不过也是有很多心得的:
1.工具提供的代码规范和你个人的代码风格有什么不同?
在我能理解的范围内,google规定的代码规范和自己的代码风格有以下不同:
- 规范中倡导“Avoid defining macros, especially in headers; prefer inline functions, enums, and
constvariables.”,不提倡用宏定义我还是第一次听说,规范中的理由是这样的:①宏定义会让你所看到的代码和编译器看到的代码不一致。我觉得就是因为宏在预处理时会被替换,就可能会在替换后导致错误吧。②宏定义是全局的,这和C++一直倡导的命名空间有冲突,一般对于常量的宏定义用const来代替,函数用inline来代替。我在C中定义常量时喜欢用宏,看了这个规范我是很惊讶的,也许是没接触很大的工程吧,还没有遇到规范上说的宏定义的缺陷。不过既然规范这样说了,那么以后就尽量用常量和内联函数来代替宏定义吧。 - 常量定义在google的规范中是以k开头的,之后是每个单词的第一个字母大写
- 之前我在定义成员变量时,命名时前面加m_,这里google规范定义的是名字后加_
2.工具提供的代码规范里有哪些部分是你之前没有想到的?
有很多我都没有想到,除了上面说的那几个规范,还有这些规范我之前是不了解的:
- 变量的声明尽可能的置于最小作用域内,并且在变量声明时就要初始化好。
- 但是有个例外,对于一个对象,因为它在每次进入作用域初始化时都会调用其构造函数,每次退出时都会调用其构析函数,所以如果没有必要的话,不要重复的初始化一个类,这一点我在自己这次作业中实现的并不太好。
- 传递对象的所有权,开销比copy一下来的少
- 所有按引用传递的参数在函数参数定义时必须加上const,这个规范可以保证在函数中不会对这个引用修改,其实本来引用就是不能修改的。
- 前置自增即++i比后置自增i++效率高,在不考虑返回值时,还是用++i吧,比如在一些循环中
- 最好使用C++的自己的类型转换方法
上面都是我能看懂的规范中对我有帮助的。
八.代码规范整理
1.代码风格规范整理
- 缩进以及不同单词之间的空隙完全由VS工具自动调整的结果为准
- 命名:(1)类型命名首字母大写,不含下划线(2)变量命名一律小写,单词之间用_连接,类的成员变量最后加_(3)常量以k开头,首字母大写不加下划线(4)常规函数使用大小写混合, 取值和设值函数则要求与变量名匹配(5)特殊的命名再做商议
- 注释:(1)尽量为每个类都写一份注释声明(2)为复杂函数前加上注释声明(3)注释要上下对齐
2.代码设计规范整理
- 不用goto语句
- 尽可能的把清理工作放在析构函数中
- 构造函数尽可能的简短
- 仅在必要时再使用类的继承