哈希冲突的根本问题就是哈希函数对输入域映射到哈希表的时候,因为哈希表的位桶的数目小于输入域的关键字个数,所以对于输入域的关键字来说很可能产生一个关键字映射到同一个位桶中,这种情况就是哈希冲突。目前解决方法有三种方案,拉链法、开放地址法、再散列法,本篇主要讲述拉链法。
HashMap的数据结构
数组
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
哈希表
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hash table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表的数组” ,如图:
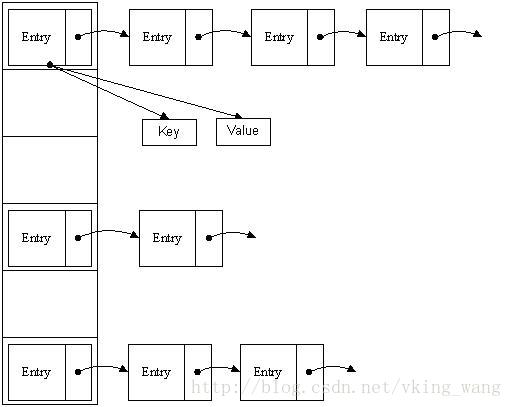
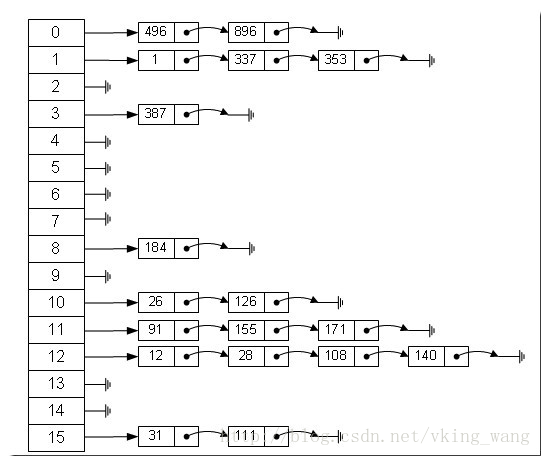
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
解决hash冲突的办法
- 开放定址法(线性探测再散列,二次探测再散列,伪随机探测再散列)
- 再哈希法
- 链地址法
- 建立一个公共溢出区
hashmap的解决办法就是采用的链地址法。
总结
HashMap是一个数组,数组中的每个元素是链表。put元素进去的时候,会通过计算key的hash值来获取到一个index,根据index找到数组中的位置,进行元素插入。当新来的元素映射到冲突的数组位置时,只需要插入到对应链表位置即可,新来的元素是插入到链表的头部。 Java中HashMap是利用“拉链法”处理HashCode的碰撞问题。在调用HashMap的put方法或get方法时,都会首先调用hashcode方法,去查找相关的key,当有冲突时,再调用equals方法。hashMap基于hasing原理,我们通过put和get方法存取对象。当我们将键值对传递给put方法时,他调用键对象的hashCode()方法来计算hashCode,然后找到bucket(哈希桶)位置来存储对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当碰撞发生了,对象将会存储在链表的下一个节点中。hashMap在每个链表节点存储键值对对象。当两个不同的键却有相同的hashCode时,他们会存储在同一个bucket位置的链表中。键对象的equals()来找到键值对