之前一直不在意这个东西,今天突然想起来了了一个问题.
经过百度和自己的测试发现,原来自己还有很多都不会.所以记录下来.毕竟细节决定成败!
学过数据结构的应该知道指针是一个很重要的概念,它记录了另一个对象的地址。
既然是来存放地址的,那么它当然等于计算机内部地址总线的宽度。
所以在32位编译器中,一个指针变量的返回值必定是4bytes,
但是,在64位编译器中指针变量的sizeof结果为8bytes。
指针变量的sizeof值与指针所指的对象没有任何关系
数组的sizeof值等于数组所占用的内存字节数
char a[] = {1, 2, 3}; printf("%lu ",sizeof(a));//3 char aa[] = "ab"; printf("%lu ",sizeof(aa));//3 int b[] = {1, 2, 3}; printf("%lu ",sizeof(b));//12 char *pa = "ab"; printf("%lu ",sizeof(pa));//8 int *pi = b; printf("%lu ",sizeof(pi));//8 char **ppa = &pa; printf("%lu ",sizeof(ppa));//8 void (*pf)();//函数指针 printf("%lu ",sizeof(pf));//8
可以总结一下:sizeof如果是数组变量名称和话就是数组长度乘上基本数据类型大小.(所以第三个的值是3 * 4 = 12)
sizeof如果是指针的话,64位编译器都是8bytes,32位编译器都是4bytes.
这里为什么要说是编译器呢,因为字节的大小其实不是计算机系统决定的,其实是编译器决定的.
具体可以看我之前写的博客:The different of bit Compiler
那么看下面两种情况:
void fp(int buffer[3]) { printf("%lu ",sizeof(buffer));//8 } void fp1(int buffer[]) { printf("%lu ",sizeof(buffer));//8 }
输出结果都是8,因为是地址传递,传的都是指针.所以在64位编译器中都是8
当我们用sizeof计算数组长度的时候正确的写法是这样:
printf("%lu ",sizeof(a)/sizeof(char));//总长度/单个元素的长度 char型 printf("%lu ",sizeof(b)/sizeof(b[0]));//总长度/第一个元素的长度 int型
结构体:
对于这两个结构体一样么?
struct s1 { char a; int b; char c; }; struct s2 { char a; char c; int b; };
看着一样,其实不一样.(有的人会觉得这两个结构体在内存中不都是占用6个字节么 4+1+1 = 6不就是变量位置换了一下么?)其实都不对
struct s1 s1 = { 'a', 0xFFFFFFFF, 'b' }; printf("%lu ",sizeof(s1));//12 struct s2 s2 = { 'a', 'b', 0xFFFFFFFF }; printf("%lu ",sizeof(s2));//8
一个占用12个字节的内存,一个占用8字节的内存!!!这仅仅就同一个变量换了一个位置而已.
解释:这就涉及到计算机组成原理的知识了.
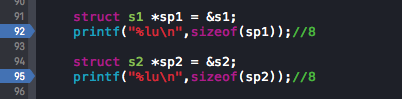
我们先设置指针指向s1和s2
struct s1 *sp1 = &s1; printf("%lu ",sizeof(sp1));//8 struct s2 *sp2 = &s2; printf("%lu ",sizeof(sp2));//8
设置断点,lldb分别输入x/8xh sp1和x/8xh sp2,显示结果如下.

可以看到显示不一样.对于第一个结构体sp1:占用了12个字节的位置.a后面占用了3个字节是空的.b后面的三个字节是空的.大大浪费了存储空间
再看看sp2:占用了8个字节,但是有些人会问,这后面为什么不是0呢?
sp2的内存地址是0x7fff5fbff868,而sp1是0x7fff5fbff870,其实sp2后面跟着的就是sp1的内存的地址值...
大家也许会问为什么要这样,计算机组成原理告诉我们这叫字节对齐,有助于加快计算机的取数速度.(这里是优先分配4字节,后面会说优先分配8字节,并解释为什么)
现在我来解释一下x/8xh sp1的意思.
在debug模式断点处,查看字符指针变量内存中的值,现在只能查看第一个内存中的值可以在输出窗口采用gdb命令:x /nfu <addr>
n表示要显示的内存单元的个数
-----------------------------------------
f表示显示方式, 可取如下值:
x 按十六进制格式显示变量
d 按十进制格式显示变量
u 按十进制格式显示无符号整型
o 按八进制格式显示变量
t 按二进制格式显示变量
a 按十六进制格式显示变量
i 指令地址格式
c 按字符格式显示变量
f 按浮点数格式显示变量
-----------------------------------------
u表示一个地址单元的长度:
b表示单字节
h表示双字节
w表示四字节
g表示八字节
-------------------------------------------
既然上面的搞定,那么下面也是一样的.就不多解释.
struct s3 { char a; char c; int b; short d; }; struct s4 { char a; char c; short d; int b; }; struct s3 s3 = { 'a', 'b', 0xFFFFFFFF, 0xFFFF }; printf("%lu ",sizeof(s3));//12 struct s4 s4 = { 'a', 'b', 0xFFFF, 0xFFFFFFFF }; printf("%lu ",sizeof(s4));//8
看来上面的是不是感觉可以了?
来看看下面的
struct F{ int a; char b; char c[2]; double d; int f; }; struct F f; printf("%lu",sizeof(f));//24
24?????为什么是24?
总结:
看到double了么!!double占8字节,所以分配的时候优先分配8字节,即使不满8字节,为什么之前的都是优先分配4字节呢?
这和结构体中最大字节大小有关,double在结构体中最大,所以优先分配8字节,之前都是int最大,所以优先分配4字节.
由此得出:
struct F{ char a; short b; char c; }; struct F f; printf("%lu",sizeof(f));//6
那么对于char数组呢?比如:
struct F{ char a; short b; char c[3]; }; struct F f; printf("%lu",sizeof(f));//8
char c[3]占3个字节,是不是优先分配3个字节呢?不是的,char最小单元依旧是一个字节,
这就解释为什么输出是8了.
更详细的解释在百度百科:sizeof
运行环境:Xcode7, OS X 10.10