(Multiple Agent+ Multiple Channel+Custom)
- Flume(一)文章我们详细介绍了单Agent的生产演进过程,但是生产上是需要从多台机器上采集数据的,故更多的是多Agent的串联和并联组合使用。如下图串联的Agent
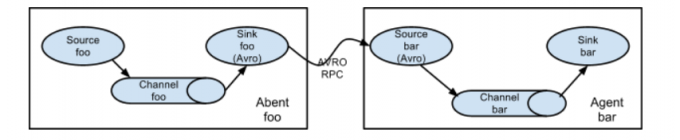
- 串联的Agent一定是采用Avro Sink和 Avro Source方式进行数据传输
Agent的结构:source -> channel -> sink -> source -> channel -> sink
Agent的选择:exec memory avro avro memory logger
###exec-avro-agent.conf文件### exec-avro-agent.sources = exec-source exec-avro-agent.channels = memory-channel exec-avro-agent.sinks = avro-sink exec-avro-agent.sources.exec-source.type = exec exec-avro-agent.sources.exec-source.command = tail -F /home/hadoop/data/flume/multiple/chuanlian/input/avro_access.data exec-avro-agent.channels.memory-channel.type = memory exec-avro-agent.sinks.avro-sink.type = avro exec-avro-agent.sinks.avro-sink.hostname = localhost exec-avro-agent.sinks.avro-sink.port = 44444 exec-avro-agent.sources.exec-source.channels = memory-channel exec-avro-agent.sinks.avro-sink.channel = memory-channel ###avro-logger-agent.conf文件### avro-logger-agent.sources = avro-source avro-logger-agent.channels = memory-channel avro-logger-agent.sinks = logger-sink avro-logger-agent.sources.avro-source.type = avro avro-logger-agent.sources.avro-source.bind = localhost avro-logger-agent.sources.avro-source.port = 44444 avro-logger-agent.channels.memory-channel.type = memory avro-logger-agent.sinks.logger-sink.type = logger avro-logger-agent.sources.avro-source.channels = memory-channel avro-logger-agent.sinks.logger-sink.channel = memory-channel ###先启动 avro-logger agent #### flume-ng agent --name avro-logger-agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/avro-logger-agent.conf -Dflume.root.logger=INFO,console ###再启动 exec-avro agent #### flume-ng agent --name exec-avro-agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/exec-avro-agent.conf -Dflume.root.logger=INFO,console
- Avro source 以及 Avro sinlk的绑定的端口和地址要一致
- 要先启动Avro soruce的Agent再启动Avro sink的Agent,关闭发的顺序反过来
Multiplexing the flow(多路传输流)
- Multiplexing Channel Selector:多路Channel选择器,是将根据自定义的选择器规则,将数据发送到指定的Channel上
- Replicating Channel Selector:多副本Channel选择器,每个Channel数据都是一样的。
- Multiplexing the flow即单Source多Channel、Sink,在生产中我们可能有这样的需求,采集到的数据一份存储HDFS(离线)一份存储Kafka(实时),这时我们就需要采用如下图的组合方式
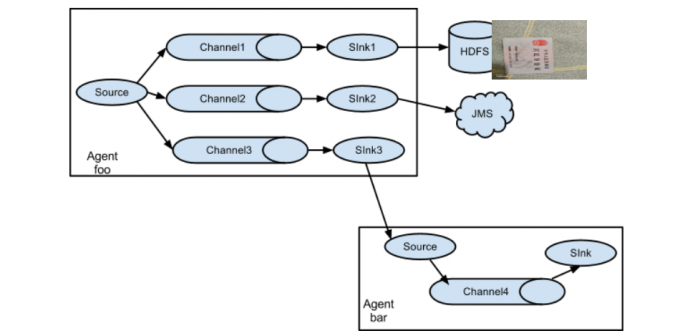
(重要) Replicating Channel Selector实现将数据采集到hdfs以及控制台
- Agent的结构:
Source --》Chianel--》Sink --》Chianel--》Sink
- Agent的选择:
netcat--》memory--》hdfs --》memory--》logger
配置文件:
##multiple-channel-agent.conf##
a1.sources = r1 a1.channels = c1 c2 a1.sinks = k1 k2 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sources.r1.selector.type = replicating a1.channels.c1.type = memory a1.channels.c2.type = memory a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = hdfs://hadoop001:9000/flume/multipleFlow/%Y%m%d%H%M a1.sinks.k1.hdfs.useLocalTimeStamp=true a1.sinks.k1.hdfs.filePrefix = wsktest- a1.sinks.k1.hdfs.rollInterval = 30 a1.sinks.k1.hdfs.rollSize = 100000000 a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.writeFormat=Text a1.sinks.k2.type = logger a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2
启动命令;
flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/multiple-channel-agent.conf -Dflume.root.logger=INFO,console
踩坑,官网的Replicating Channel Selector的配置为a1.source.r1.selector.type = replicating 这是错误的配置source少了s
Multiplexing Channel Selector实现将数据采集到不同的Channel然后移动到hdfs
- 它实现了将生产上不同业务数据使用同一的Flume进行数据收集
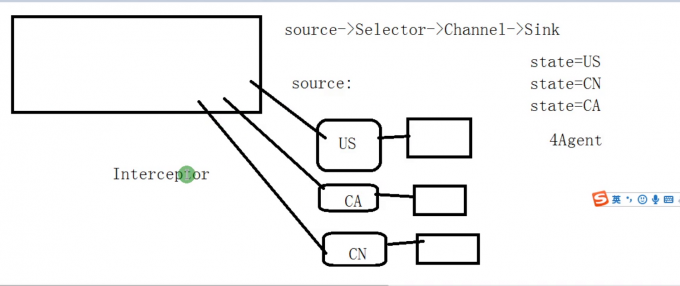
实现思路:
- 第一步:首先配置三个Agent分别抽取US、CN、CA的业务数据,每个Agent都需要添加静态拦截器,添加state=v信息
- 第二步:配置聚合的Agent,该Agent用于收集 之前三个Agent数据,并根据Event的head的State的value执法选择具体的Channel,不同的Channel将数据分别写到不同的HDFS上
(重要)Consolidation并联Agent采集数据到HDFS

- 生产上客户的服务器可能有成千上万台,而且大数据集群是我们自己内部,首先客户业务集群和咱们的大数据集群网络肯定是不通的,其次上万台同时写hdfs,那hdfs网络开销太大了。实际是先通过写到具有大数据集群getway权限的一个或多个洛盘机器上,然后由该洛盘机器将数据写到hdfs上。次流程实现也是非常简单的,在两个串联Agent实现数据采集到控制台基础上并联复制avro sink Agent到每台机器上即可,avro source Agent的sink要写成hdfs。
- 注意:为了保证sink端挂了如hdfs无法使用时channel不会被撑爆以及重启数据丢失,channel最好选择为File
(了解)Sink Processors(sink group)
- 上面提到的都是一个sink只能消费一个channel,若哪个唯一的sink异常了,那么channel就会阻塞,同时无法转移数据,故Flume提出了Sink group(Processors)概念,一个组内的所有的sink可以消费一个channel,生产上一般processor.type采用failover,即向组内优先级高的sink发送数据,若挂了就向次优先级的sink发送数据
6.(重要)Custom Source
官网提供的source以及sink有时并不能满足我们的需求,此时我们就需要custom source以及sink了。可参考如下文档
完全idea要添加Flume core依赖:
<dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.7.0</version> </dependency>
去github上搜custom的source以及sink借鉴学习:
(重要)生产中的Flume架构
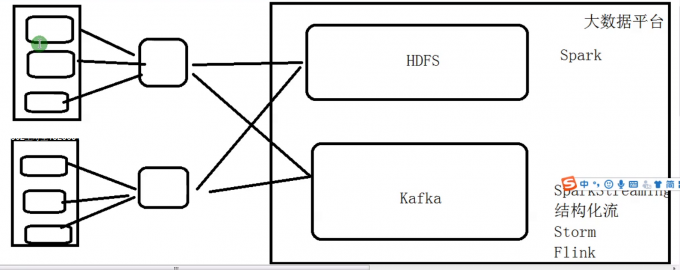
- 第一层Agent:
Taildir Source -> File Channel -> AVRO Sink
- 第二层Agent:
AVRO Source -> File Channel -> HDFS -> File Channel -> Kafka