副本放置策略
机架知识
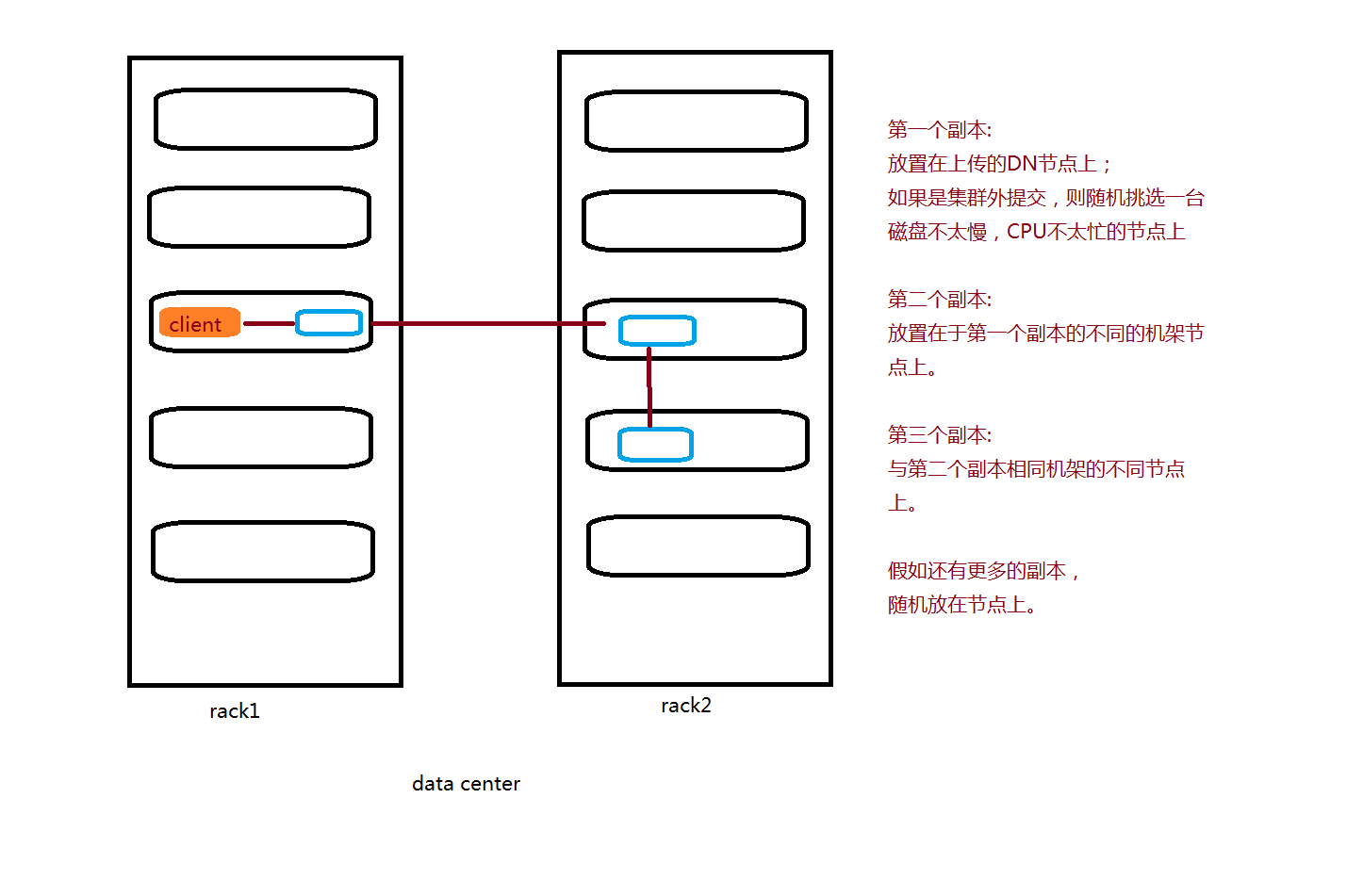
生产上 尽量将读写的动作 选取DN节点
机架,一台机架放5台服务器,本来按位置来说可以放10个但是我们只放5个,原因是一台机架的电量是多大,一个机柜的电流的安培是有标准的(10A,20A,40A,还可以改造)
所以每台机架放置服务台数的标准就是用机柜电流量的大小除以每台服务器所需电流,得到一个估算值。
(如果你的命令或者jar包的当前节点正好是datanode)上传的机器是datanode,那肯定优先在自己的节点上上传一个副本,这样就不需要通过网络IO,通过网线去传输数据包,这样会节省时间
第一个副本放置在上传的DN节点上
如果是集群外提交,则随机选一台磁盘不太慢,CPU不太忙的节点上
第2个副本放在与第一个副本在不同的机架节点上
第三个副本与第2个副本相同机架不同节点上
假如更多副本就随机放
面试题:
集群DN 3个,其中一个DN挂了,那么一个文件三个副本,
那么我现在能够正确读取文件内容吗?
其实就是block Miss,那么怎样去修复?
1.手动修复
https://blog.csdn.net/high2011/article/details/72461376
[hadoop@hadoop002 hadoop-2.6.0-cdh5.7.0]$ hdfs |grep debug
隐藏太深了
[hadoop@hadoop002 hadoop-2.6.0-cdh5.7.0]$ hdfs debug
Usage: hdfs debug <command> [arguments]
verify [-meta <metadata-file>] [-block <block-file>]
recoverLease [-path <path>] [-retries <num-retries>]
[hadoop@hadoop002 hadoop-2.6.0-cdh5.7.0]$
2.自动修复
https://www.cnblogs.com/prayer21/p/4819789.html