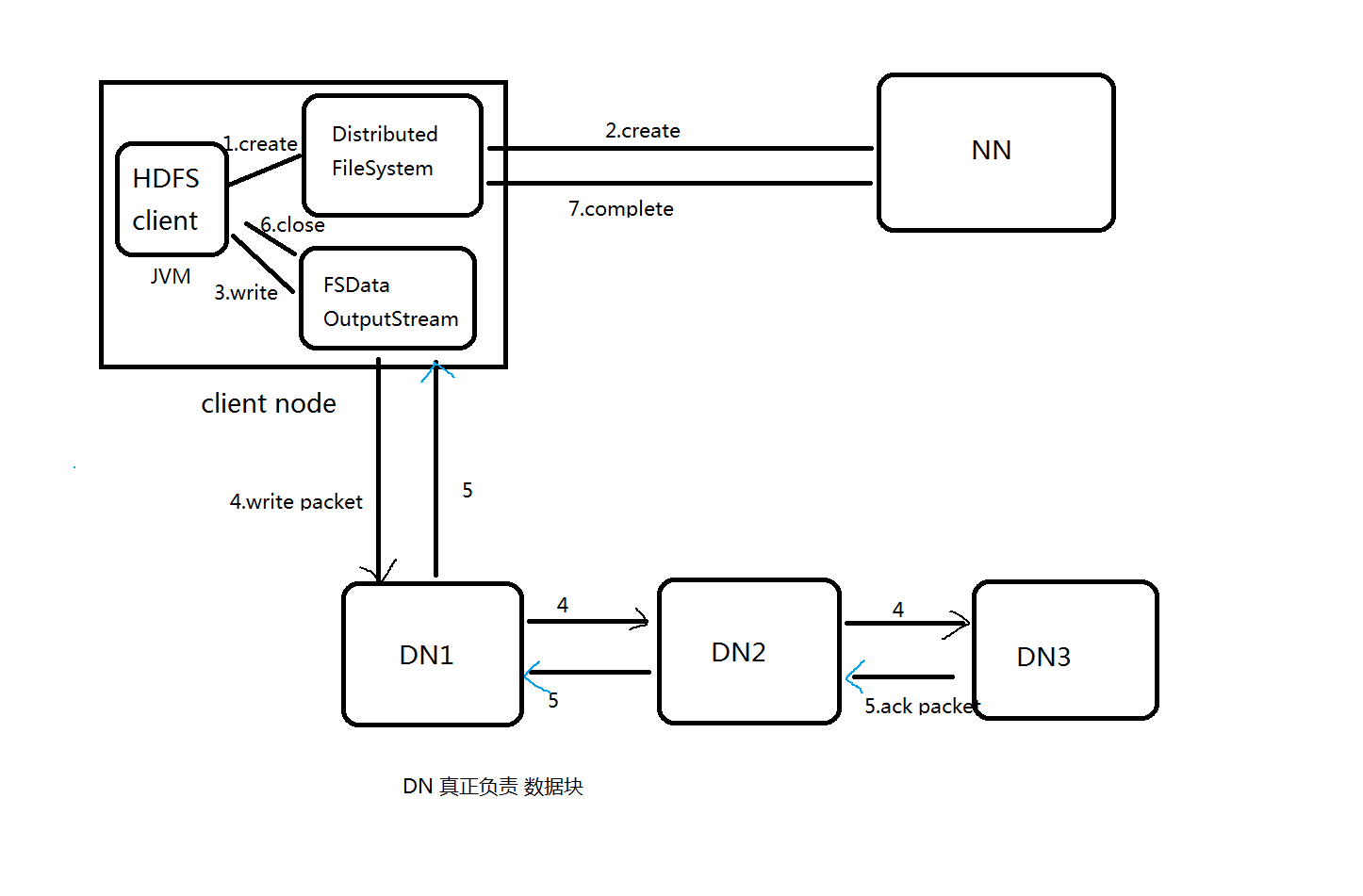
HDFS写流程
[hadoop@hadoop002 hadoop-2.6.0-cdh5.7.0]$ hdfs dfs -put LICENSE.txt /
19/02/20 21:30:22 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[hadoop@hadoop002 hadoop-2.6.0-cdh5.7.0]$
对于我们操作者而言,是无感知的
1.Client调用FileSystem.create(filePath)方法,
去与NN进行【RPC】通信,check该路径的文件是否存在
以及有没有权限创建该文件。 假如OK,就创建一个新文件,
但是不关联任何的block,nn根据上传的文件大小且块大小且副本数,
计算多少块,以及块存放的dn,最终将这些信息返回给客户端
则为【FSDataOutputStream】。
2.Client调用FSDataOutputStream.write方法,将第一个块的
第一个副本写到第一个DN,写完写第二个副本,写完写第三个副本;
当第三个副本写完,返回给ack packet给第二个副本的DN,然后第二个DN返回ack packet给第一个DN;
第一个DN返回ack packet给FSDataOutputStream对象,标识第一个块,3副本写完!
副本默认个数的参数设置参考:https://www.cnblogs.com/xuziyu/p/10426186.html
然后依次写剩余的块!
注意:
客户端调用FSDataInputStream API的write方法首先将其中一个block写在datanode上,每一个block默认都有3个副本,并不是由客户端分别往3个datanode上写3份,而是由已经上传了block的datanode产生新的线程,由这个namenode按照放置副本规则往其它datanode写副本,这样的优势就是快。
参考:https://www.cnblogs.com/fssqblogsit/p/6938999.html
(对操作者来说是透明的)
3.当向文件写入数据完成后,Client调用FSDataOutputStream.close()方法。关闭输出流,flush换成区的数据包。
4.再调用FileSystem.complete(),通知NN节点写入成功。
3DN
3副本
副本数据=DN
1DN
1副本
测试:DN挂了 能不能写
同比: 3DN 3副本 1DN挂了 肯定写不成功
10DN
3副本
副本数据<DN
测试:DN挂了 写
总结: 存活的DN满足我们的副本数 就能写