
一、Redis数据库
0. 导读
- Redis 服务器的所有数据库都保存在
redisServer.db数组中, 而数据库的数量则由redisServer.dbnum属性保存。 - 客户端通过修改目标数据库指针, 让它指向
redisServer.db数组中的不同元素来切换不同的数据库。 - 数据库主要由
dict和expires两个字典构成, 其中dict字典负责保存键值对, 而expires字典则负责保存键的过期时间。 - 因为数据库由字典构成, 所以对数据库的操作都是建立在字典操作之上的。
- 数据库的键总是一个字符串对象, 而值则可以是任意一种 Redis 对象类型, 包括字符串对象、哈希表对象、集合对象、列表对象和有序集合对象, 分别对应字符串键、哈希表键、集合键、列表键和有序集合键。
expires字典的键指向数据库中的某个键, 而值则记录了数据库键的过期时间, 过期时间是一个以毫秒为单位的 UNIX 时间戳。- Redis 使用惰性删除和定期删除两种策略来删除过期的键: 惰性删除策略只在碰到过期键时才进行删除操作, 定期删除策略则每隔一段时间, 主动查找并删除过期键。
- 执行 SAVE 命令或者 BGSAVE 命令所产生的新 RDB 文件不会包含已经过期的键。
- 执行 BGREWRITEAOF 命令所产生的重写 AOF 文件不会包含已经过期的键。
- 当一个过期键被删除之后, 服务器会追加一条 DEL 命令到现有 AOF 文件的末尾, 显式地删除过期键。
- 当主服务器删除一个过期键之后, 它会向所有从服务器发送一条 DEL 命令, 显式地删除过期键。
- 从服务器即使发现过期键, 也不会自作主张地删除它, 而是等待主节点发来 DEL 命令, 这种统一、中心化的过期键删除策略可以保证主从服务器数据的一致性。
- 当 Redis 命令对数据库进行修改之后, 服务器会根据配置, 向客户端发送数据库通知。
1.redis服务端数据库数量
Redis服务器将所有数据库都保存在服务器状态redis.h/redisServer结构都db数组中,db数据的每个项都是一个redis.h/redisDb结构,每个redisDb结构代表一个数据库:
struct redisServer{ // ... //一个数组,保存着服务器中的所有数据库 redisDb *db; //服务器的数据库数量 int dbnum; // ... };
- 在初始化服务器时,程序会根据服务器的状态的dbnum属性来决定应该创建多少个数据库;
- dbnum属性的值由服务器配置的database选项决定,默认情况下,该选项的值为16,所以Redis服务器默认会创建16个数据库。
如图

2.客户端,目标数据库
typedef struct redisClient { // ... // 记录客户端当前正在使用的数据库 redisDb *db; // ... } redisClient

3.数据库键空间的操作
- Redis 是一个键值对(key-value pair)数据库服务器, 服务器中的每个数据库都由一个
redis.h/redisDb结构表示, 其中,redisDb结构的dict字典保存了数据库中的所有键值对, 我们将这个字典称为键空间(key space):
typedef struct redisDb { // ... // 数据库键空间,保存着数据库中的所有键值对 dict *dict; // ... } redisDb;
- 键空间和用户所见的数据库是直接对应的:
- 键空间的键也就是数据库的键, 每个键都是一个字符串对象。
- 键空间的值也就是数据库的值, 每个值可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象在内的任意一种 Redis 对象。
举个例子, 如果我们在空白的数据库中执行以下命令:
redis> SET message "hello world"
OK
redis> RPUSH alphabet "a" "b" "c"
(integer) 3
redis> HSET book name "Redis in Action"
(integer) 1
redis> HSET book author "Josiah L. Carlson"
(integer) 1
redis> HSET book publisher "Manning"
(integer) 1
- 那么在这些命令执行之后, 数据库的键空间将会是图 IMAGE_DB_EXAMPLE 所展示的样子:
alphabet是一个列表键, 键的名字是一个包含字符串"alphabet"的字符串对象, 键的值则是一个包含三个元素的列表对象。book是一个哈希表键, 键的名字是一个包含字符串"book"的字符串对象, 键的值则是一个包含三个键值对的哈希表对象。message是一个字符串键, 键的名字是一个包含字符串"message"的字符串对象, 键的值则是一个包含字符串"hello world"的字符串对象。
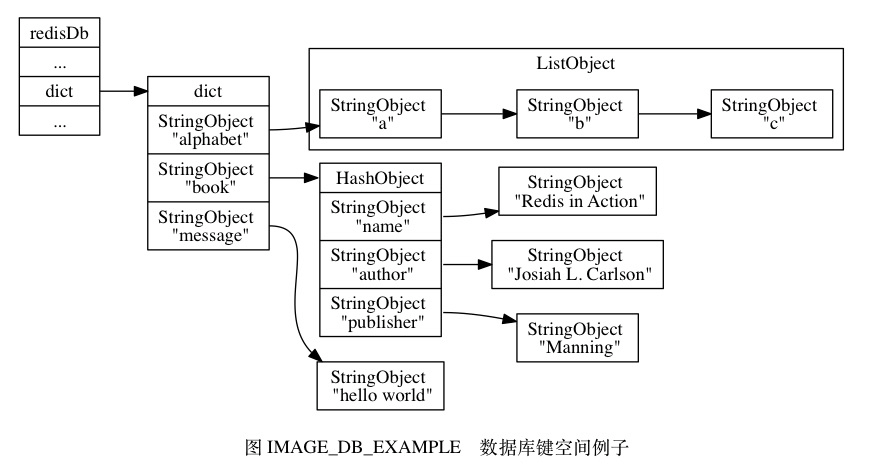
- 因为数据库的键空间是一个字典, 所以所有针对数据库的操作 —— 比如添加一个键值对到数据库, 或者从数据库中删除一个键值对, 又或者在数据库中获取某个键值对, 等等,实际上都是通过对键空间字典进行操作来实现的。
- 其他键空间操作。除了上面列出的添加、删除、更新、取值操作之外, 还有很多针对数据库本身的 Redis 命令, 也是通过对键空间进行处理来完成的。
- 比如说, 用于清空整个数据库的 FLUSHDB 命令, 就是通过删除键空间中的所有键值对来实现的。
- 又比如说, 用于随机返回数据库中某个键的 RANDOMKEY 命令, 就是通过在键空间中随机返回一个键来实现的。
- 另外, 用于返回数据库键数量的 DBSIZE 命令, 就是通过返回键空间中包含键值对的数量来实现的。
- 类似的命令还有 EXISTS 、 RENAME 、 KEYS , 等等, 这些命令都是通过对键空间进行操作来实现的。
- 读写键空间时的维护操作
-
- 当使用 Redis 命令对数据库进行读写时, 服务器不仅会对键空间执行指定的读写操作, 还会执行一些额外的维护操作, 其中包括:
- 在读取一个键之后(读操作和写操作都要对键进行读取), 服务器会根据键是否存在, 以此来更新服务器的键空间命中(hit)次数或键空间不命中(miss)次数, 这两个值可以在 INFO stats 命令的
keyspace_hits属性和keyspace_misses属性中查看。 - 在读取一个键之后, 服务器会更新键的 LRU (最后一次使用)时间, 这个值可以用于计算键的闲置时间, 使用命令 OBJECT idletime <key> 命令可以查看键
key的闲置时间。 - 如果服务器在读取一个键时, 发现该键已经过期, 那么服务器会先删除这个过期键, 然后才执行余下的其他操作, 本章稍后对过期键的讨论会详细说明这一点。
- 如果有客户端使用 WATCH 命令监视了某个键, 那么服务器在对被监视的键进行修改之后, 会将这个键标记为脏(dirty), 从而让事务程序注意到这个键已经被修改过, 《事务》一章会详细说明这一点。
- 服务器每次修改一个键之后, 都会对脏(dirty)键计数器的值增一, 这个计数器会触发服务器的持久化以及复制操作执行, 《RDB 持久化》、《AOF 持久化》和《复制》这三章都会说到这一点。
- 如果服务器开启了数据库通知功能, 那么在对键进行修改之后, 服务器将按配置发送相应的数据库通知, 本章稍后讨论数据库通知功能的实现时会详细说明这一点。
4.设置键的生存时间/过期时间;
- Redis有四个不同的命令可以用于设置键的生存时间(键可以存在多久)或过期时间(键什么时候会被删除):
- EXPIRE<key><ttl>命令用于将键key的生存时间设置为ttl秒。
- PEXPIRE<key><ttl>命令用于将键key的生存时间设置为ttl毫秒。
- EXPIREAT<key><timestamp>命令用于将键key的过期时间设置为timestamp所指定的秒数时间戳。
- PEXPIREAT<key><timestamp>命令用于将键key的过期时间设置为timestamp所指定的毫秒数时间戳。
- 虽然有多种不同单位和不同形式的设置命令,但实际上EXPIRE、PEXPIRE、EXPIREAT三个命令都是使用PEXPIREAT命令来实现的:无论客户端执行的是以上四个命令中的哪一个,经过转换之后,最终的执行效果都和执行PEXPIREAT命令一样。

- redisDb结构的expires字典保存了数据库中所有键的过期时间,我们称这个字典为过期字典
- 过期字典的键是一个指针,这个指针指向键空间中的某个键对象(也即是某个数据库键)。
- 过期字典的值是一个long long类型的整数,这个整数保存了键所指向的数据库键的过期时间——一个毫秒精度的UNIX时间戳。
查询剩余生命?移除过期时间?
5.过期键的删除策略:定时/惰性/定期。优缺点
- 删除策略有定时/惰性/定期三种。但Redis服务器实际使用的是惰性删除和定期删除两种策略:通过配合使用这两种删除策略,服务器可以很好地在合理使用CPU时间和避免浪费内存空间之间取得平衡。
- 惰性删除
惰性删除策略对CPU时间来说是最友好的:程序只会在取出键时才对键进行过期检查,这可以保证删除过期键的操作只会在非做不可的情况下进行,并且删除的目标仅限于当前处理的键,这个策略不会在删除其他无关的过期键上花费任何CPU时间。
惰性删除策略的缺点是,它对内存是最不友好的:如果一个键已经过期,而这个键又仍然保留在数据库中,那么只要这个过期键不被删除,它所占用的内存就不会释放。
在使用惰性删除策略时,如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么它们也许永远也不会被删除(除非用户手动执行FLUSHDB),我们甚至可以将这种情况看作是一种内存泄漏——无用的垃圾数据占用了大量的内存,而服务器却不会自己去释放它们,这对于运行状态非常依赖于内存的Redis服务器来说,肯定不是一个好消息。
举个例子,对于一些和时间有关的数据,比如日志(log),在某个时间点之后,对它们的访问就会大大减少,甚至不再访问,如果这类过期数据大量地积压在数据库中,用户以为服务器已经自动将它们删除了,但实际上这些键仍然存在,而且键所占用的内存也没有释放,那么造成的后果肯定是非常严重的。
- 定期删除
从上面对惰性删除的讨论来看,这删除方式在单一使用时有明显的缺陷:
惰性删除浪费太多内存,有内存泄漏的危险。定期删除策略是前两种策略的一种整合和折中:
定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。除此之外,通过定期删除过期键,定期删除策略有效地减少了因为过期键而带来的内存浪费。定期删除策略的难点是确定删除操作执行的时长和频率:
如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成定时删除策略,以至于将CPU时间过多地消耗在删除过期键上面。
如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除策略一样,出现浪费内存的情况。因此,如果采用定期删除策略的话,服务器必须根据情况,合理地设置删除操作的执行时长和执行频率。
6. RDB save/load; AOP写入/重放;主从过期策略;
- 生成RDB文件
在执行SAVE命令或者BGSAVE命令创建一个新的RDB文件时,程序会对数据库中的键进行检查,已过期的键不会被保存到新创建的RDB文件中。
举个例子,如果数据库中包含三个键k1、k2、k3,并且k2已经过期,那么当执行SAVE命令或者BGSAVE命令时,程序只会将k1和k3的数据保存到RDB文件中,而k2则会被忽略。
因此,数据库中包含过期键不会对生成新的RDB文件造成影响。
可参考rdb.c中函数rdbSave()函数源码:
- 载入RDB文件
在启动Redis服务器时,如果服务器开启了RDB功能,那么服务器将对RDB文件进行载入:
-
- 如果服务器以主服务器模式运行,那么在载入RDB文件时,程序会对文件中保存的键进行检查,未过期的键会被载入到数据库中,而过期键则会被忽略,所以过期键对载入RDB文件的主服务器不会造成影响;
- 如果服务器以从服务器模式运行,那么在载入RDB文件时,文件中保存的所有键,不论是否过期,都会被载入到数据库中。不过,因为主从服务器在进行数据同步的时候,从服务器的数据库就会被清空,所以一般来讲,过期键对载入RDB文件的从服务器也不会造成影响;
这部分代码可以查看rdb.c中rdbLoad()函数源码:
- AOF文件写入
当服务器以AOF持久化模式运行时,如果数据库中的某个键已经过期,但它还没有被惰性删除或者定期删除,那么AOF文件不会因为这个过期键而产生任何影响。
当过期键被惰性删除或者定期删除之后,程序会向AOF文件追加(append)一条DEL命令,来显式地记录该键已被删除。
举个例子,如果客户端使用GET message命令,试图访问过期的message键,那么服务器将执行以下三个动作:
1)从数据库中删除message键。
2)追加一条DEL message命令到AOF文件。(根据AOF文件增加的特点,AOF只有在客户端进行请求的时候才会有这个DEL操作)
3)向执行GET命令的客户端返回空回复。
这部分就是Redis中的惰性删除策略中expireIfNeeded函数的使用。关于惰性删除策略这一部分在Redis惰性删除策略一篇中有讲。所以这里就不赘述了。
需要提示一下的是:expireIfNeeded函数是在db.c/lookupKeyRead()函数中被调用,lookupKeyRead函数用于在执行读取操作时取出键key在数据库db中的值。
- AOF重写
和生成RDB文件时类似,在执行AOF重写的过程中,程序会对数据库中的键进行检查,已过期的键不会被保存到重写后的AOF文件中。
举个例子,如果数据库中包含三个键k1、k2、k3,并且k2已经过期,那么在进行重写工作时,程序只会对k1和k3进行重写,而k2则会被忽略。
这一部分如果掌握了AOF重写的方法的话,那就自然理解了。
- 复制
当服务器运行在复制模式下时,从服务器的过期键删除动作由主服务器控制:
-
- 主服务器在删除一个过期键之后,会显式地向所有从服务器发送一个DEL命令,告知从服务器删除这个过期键;
- 从服务器在执行客户端发送的读命令时,即使碰到过期键也不会将过期键删除,而是继续像处理未过期的键一样来处理过期键;
- 从服务器只有在接到主服务器发来的DEL命令之后,才会删除过期键。
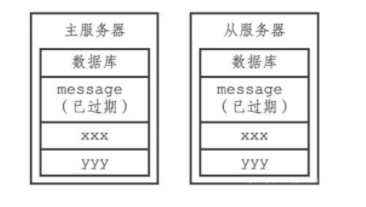
举个例子,有一对主从服务器,它们的数据库中都保存着同样的三个键message、xxx和yyy,其中message为过期键,如图所示
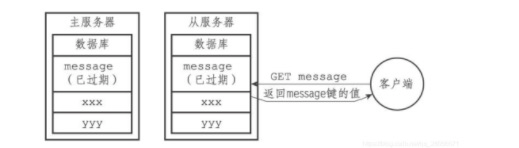
假设在此之后,有客户端向主服务器发送命令GET message,那么主服务器将发现键message已经过期:主服务器会删除message键,向客户端返回空回复,并向从服务器发送DEL message命令,如图所示:

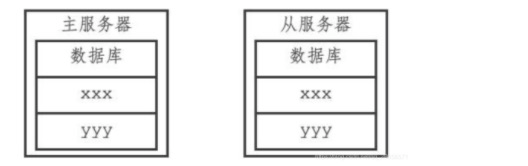
从服务器在接收到主服务器发来的DEL message命令之后,也会从数据库中删除message键,在这之后,主从服务器都不再保存过期键message了,如图所示:
7. 数据库通知
举个例子,以下代码展示了客户端如何获取0号数据库中针对message键执行的所有命令:
127.0.0.1:6379>SUBSCRIBE__keyspace@0__:message
Reading messages . . . (press Ctrl-C to quit)
1) "subscribe" //订阅信息
2) "_ _keyspace@0_:message"
3) (integer) 1
1) "message" //执行SET 命令
2) "_ _keyspace@0_: message"
3) "set"
1) "message" //执行EXPIE命令
2) " keyspace@0_:message"
3) "expire"
1) "message" //执行DEL 命令
2) "_ _keyspace@0_: message "
3) "de1"
根据发回的通知显示,先后共有SET、EXPlRE 、DEL 三个命令对键message进行了操作。
这一类关注"某个键执行了什么命令"的通知称为键空间通知(key-space-notification),除此之外,还有另一类称为键事件通知(key-event-notification)的通知,它们关注的是"某个命令被什么键执行了" 。
以下是一个键事件通知的例子,代码展示了客户端如何获取0 号数据库中所有执行DEL 命令的键:
127.0 . 0.1:6379> SUBSCRIBE_ _keyevent@0_ _:de1
Reading messages. . . (press Ctrl-C to quit)
1) "subcribe" //订阅信息
2) "_ _keyevent@0_ _:del"
3) (integer) 1
1) "message" //键key执行了DEL命令
2) "keyevent@0_ _:del"
3) "key"
1) "message" //键number执行了DEL命令
2) "_ _keyevent@0_ _:del"
3) "number"
1) "message" //键message执行了DEL命令
2) "keyevent@0_ _:del"
3) "message"
根据发回的通知显示,key、number、message三个键先后执行了DEL 命令。服务器配置的notify-keyspace-events选项决定了服务器所发送通知的类型:
想让服务器发送所有类型的键空间通知和键事件通知,可以将选项的值设置为AKE。
想让服务器发送所有类型的键空间通知,可以将选项的值设置为AK。
想让服务器发送所有类型的键事件通知,可以将选项的值设置为AE。
想让服务器只发送和字符串键有关的键空间通知,可以将选项的值设置为K$。
想让服务器只发送和列表键有关的键事件通知,可以将选项的值设置为E1。
关于数据库通知功能的详细用法,以及notify-keyspace-events选项的更多设置,Redis 的官方文档已经做了很详细的介绍,这里不再赘述。
二、RDB持久化
Redis是一个键值对数据库服务器,服务器中通常包含着任意个非空数据库,而每个非空数据库中又可以包含任意个键值对,为了方便起见,我们将服务器中的非空数据库以及他们的键值对统称为数据库状态。
因为Redis是内存数据库,它将自己的数据库状态储存在内存里面,所以如果不想办法将储存在内存中的数据库状态保存到磁盘里面,那么一旦服务器进程退出,服务器中的数据库状态也会消失不见。
为了解决这个问题,Redis提供了RDB持久化功能,这个功能可以将Redis在内存中的数据库状态保存到磁盘里面,避免数据意外丢失。
RDB持久化既可以手动执行,也可以根据服务器配置选项定期执行,该功能可以将某个时间点上的数据库状态保存到一个RDB文件中。
RDB持久化功能所生成的RDB文件是一个经过压缩的二进制文件,通过该文件可以还原生成RDB文件时的数据库状态。如下图所示

0.导读
- RDB 文件用于保存和还原 Redis 服务器所有数据库中的所有键值对数据。
- SAVE 命令由服务器进程直接执行保存操作,所以该命令会阻塞服务器。
- BGSAVE 命令由子进程执行保存操作,所以该命令不会阻塞服务器。
- 服务器状态中会保存所有用
save选项设置的保存条件,当任意一个保存条件被满足时,服务器会自动执行 BGSAVE 命令。 - RDB 文件是一个经过压缩的二进制文件,由多个部分组成。
- 对于不同类型的键值对, RDB 文件会使用不同的方式来保存它们。
1.RDB 文件的创建与载入
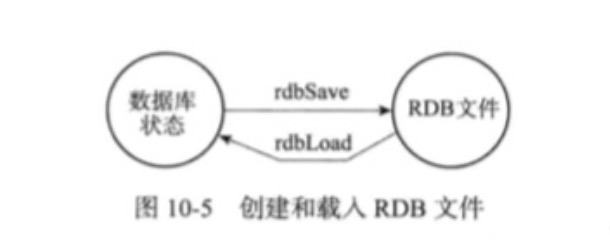
- 有两个Redis命令可以用于生成RDB文件,一个是SAVE,另一个是BGSAVE。
-
- SAVE命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求
- 和SAVE命令直接阻塞服务器进程的做法不同,BGSAVE命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求
创建RDB文件的实际工作由rdb.c/rdbSave函数完成,SAVE命令和BGSAVE命令会以不同的方式调用这个函数,通过以下伪代码可以明显地看出这两个命令之间的区别:

- 载入rdbLoad/aofLoad;
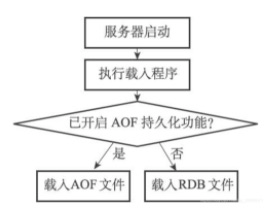
和使用SAVE命令或者BGSAVE命令创建RDB文件不同,RDB文件的载入工作是在服务器启动时自动执行的,所以Redis并没有专门用于载入RDB文件的命令,只要Redis服务器在启动时检测到RDB文件存在,它就会自动载入RDB文件。
- 另外值得一提的是,因为AOF文件的更新频率通常比RDB文件的更新频率高,所以:
- 如果服务器开启了AOF持久化功能,那么服务器会优先使用AOF文件来还原数据库状态。
- 只有在AOF持久化功能处于关闭状态时,服务器才会使用RDB文件来还原数据库状态。
服务器判断该使用哪个文件来还原数据库状态的流程,如下图所示:
载入RDB文件的实际工作由rdb.c/rdbLoad()完成,这个函数和rdbSave()之间的关系可以下图表示。
- bgsave执行时的服务器状态
待补充
2.自动间隔性保存
- 服务器save配置
因为BGSAVE命令可以在不阻塞服务器进程的情况下执行,所以Redis允许用户通过设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令。
举个例子,如果我们向服务器提供以下配置:
save 900 1
save 300 10
save 60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE命令就会被执行:
- 服务器在900秒之内,对数据库进行了至少1次修改。
- 服务器在300秒之内,对数据库进行了至少10次修改。
- 服务器在60秒之内,对数据库进行了至少10000次修改。
- 设置保存条件/数据结构
当Redis服务器启动时,用户可以通过指定配置文件或者传入启动参数的方式设置save选项,如果用户没有主动设置save选项,那么服务器会为save选项设置默认条件:
save 900 1
save 300 10
save 60 10000
接着,服务器程序会根据save选项所设置的保存条件,设置服务器状态redisServer结构的saveparams属性.
struct redisServer {
// ...
// 记录了保存条件的数组
struct saveparm *saveparams;
// ...
// 修改计数器
long long dirty;
// 上次执行保存的时间
time_t lastsave;
// ...
}
-
- dirty计数器记录距离上一次成功执行SAVE命令或者BGSAVE命令之后,服务器对数据库状态(服务器中的所有数据库)进行了多少次修改(包括写入、删除、更新等操作)。
- lastsave属性是一个UNIX时间戳,记录了服务器上一次成功执行SAVE命令或者BGSAVE命令的时间。
- saveparams属性是一个数组,数组中的每个元素都是一个saveparam结构,每个saveparam结构都保存了一个save选项设置的保存条件:
struct saveparm {
// 秒数
time_t seconds;
// 修改数
int changes;
}
那么服务器状态中的saveparams数组将会是下图所示的样子

- 检查保存条件是否满足
Redis的服务器周期性操作函数serverCron默认每隔100毫秒就会执行一次,该函数用于对正在运行的服务器进行维护,它的其中一项工作就是检查save选项所设置的保存条件是否已经满足,如果满足的话,就执行BGSAVE命令。以下伪代码展示了serverCron函数检查保存条件的过程:

程序会遍历并检查saveparams数组中的所有保存条件,只要有任意一个条件被满足,那么服务器就会执行BGSAVE命令。
3.RDB 文件结构
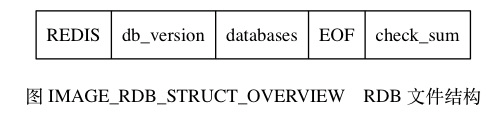
图 IMAGE_RDB_STRUCT_OVERVIEW 展示了一个完整 RDB 文件所包含的各个部分。
注意
- 为了方便区分变量、数据、常量, 图 IMAGE_RDB_STRUCT_OVERVIEW 中用全大写单词标示常量, 用全小写单词标示变量和数据。
- 因为 RDB 文件保存的是二进制数据, 而不是 C 字符串, 为了简便起见, 我们用
"REDIS"符号代表'R'、'E'、'D'、'I'、'S'五个字符, 而不是带'�'结尾符号的 C 字符串'R'、'E'、'D'、'I'、'S'、'�'。本章展示的所有 RDB 文件结构图都遵循此规则。
- RDB 文件的最开头是
REDIS部分, 这个部分的长度为5字节, 保存着"REDIS"五个字符。 通过这五个字符, 程序可以在载入文件时, 快速检查所载入的文件是否 RDB 文件。 db_version长度为4字节, 它的值是一个字符串表示的整数, 这个整数记录了 RDB 文件的版本号, 比如"0006"就代表 RDB 文件的版本为第六版。 本章只介绍第六版 RDB 文件的结构。EOF常量的长度为1字节, 这个常量标志着 RDB 文件正文内容的结束, 当读入程序遇到这个值的时候, 它知道所有数据库的所有键值对都已经载入完毕了。check_sum是一个8字节长的无符号整数, 保存着一个校验和, 这个校验和是程序通过对REDIS、db_version、databases、EOF四个部分的内容进行计算得出的。 服务器在载入 RDB 文件时, 会将载入数据所计算出的校验和与check_sum所记录的校验和进行对比, 以此来检查 RDB 文件是否有出错或者损坏的情况出现。
作为例子, 图 IMAGE_RDB_WITH_EMPTY_DATABASE 展示了一个 databases 部分为空的 RDB 文件: 文件开头的 "REDIS" 表示这是一个 RDB 文件, 之后的 "0006" 表示这是第六版的 RDB 文件, 因为 databases 为空, 所以版本号之后直接跟着 EOF 常量, 最后的 6265312314761917404 是文件的校验和。

- databases 部分
a. databases部分包含着零个或任意多个数据库, 以及各个数据库中的键值对数据:- 如果服务器的数据库状态为空(所有数据库都是空的), 那么这个部分也为空, 长度为
0字节。 - 如果服务器的数据库状态为非空(有至少一个数据库非空), 那么这个部分也为非空, 根据数据库所保存键值对的数量、类型和内容不同, 这个部分的长度也会有所不同。
比如说, 如果服务器的
0号数据库和3号数据库非空, 那么服务器将创建一个如图 所示的 RDB 文件, 图中的database 0代表0号数据库中的所有键值对数据, 而database 3则代表3号数据库中的所有键值对数据。
- 如果服务器的数据库状态为空(所有数据库都是空的), 那么这个部分也为空, 长度为
b.每个非空数据库在 RDB 文件中都可以保存为 SELECTDB 、 db_number 、 key_value_pairs 三个部分, 如图所示。
-
SELECTDB常量的长度为1字节, 当读入程序遇到这个值的时候, 它知道接下来要读入的将是一个数据库号码。db_number保存着一个数据库号码, 根据号码的大小不同, 这个部分的长度可以是1字节、2字节或者5字节。 当程序读入db_number部分之后, 服务器会调用 SELECT 命令, 根据读入的数据库号码进行数据库切换, 使得之后读入的键值对可以载入到正确的数据库中。key_value_pairs部分保存了数据库中的所有键值对数据, 如果键值对带有过期时间, 那么过期时间也会和键值对保存在一起。 根据键值对的数量、类型、内容、以及是否有过期时间等条件的不同,key_value_pairs部分的长度也会有所不同。
- key_value_pairs 部分
- RDB 文件中的每个
key_value_pairs部分都保存了一个或以上数量的键值对, 如果键值对带有过期时间的话, 那么键值对的过期时间也会被保存在内。
- RDB 文件中的每个
不带过期时间的键值对在 RDB 文件中对由 TYPE 、 key 、 value 三部分组成, 如图 IMAGE_KEY_WITHOUT_EXPIRE_TIME 所示。

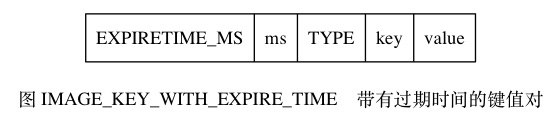
带有过期时间的键值对在 RDB 文件中的结构如图 IMAGE_KEY_WITH_EXPIRE_TIME 所示。
-
TYPE记录了value的类型,TYPE常量都代表了一种对象类型或者底层编码, 当服务器读入 RDB 文件中的键值对数据时, 程序会根据TYPE的值来决定如何读入和解释value的数据。 TYPE长度为1字节, 值可以是以下常量的其中一个:REDIS_RDB_TYPE_STRINGREDIS_RDB_TYPE_LISTREDIS_RDB_TYPE_SETREDIS_RDB_TYPE_ZSETREDIS_RDB_TYPE_HASHREDIS_RDB_TYPE_LIST_ZIPLISTREDIS_RDB_TYPE_SET_INTSETREDIS_RDB_TYPE_ZSET_ZIPLISTREDIS_RDB_TYPE_HASH_ZIPLIST
key和value分别保存了键值对的键对象和值对象:- 其中
key总是一个字符串对象, 它的编码方式和REDIS_RDB_TYPE_STRING类型的value一样。 根据内容长度的不同,key的长度也会有所不同。 - 根据
TYPE类型的不同, 以及保存内容长度的不同, 保存value的结构和长度也会有所不同, 本节稍后会详细说明每种TYPE类型的value结构保存方式。
- 其中
-
EXPIRETIME_MS常量的长度为1字节, 它告知读入程序, 接下来要读入的将是一个以毫秒为单位的过期时间。ms是一个8字节长的带符号整数, 记录着一个以毫秒为单位的 UNIX 时间戳, 这个时间戳就是键值对的过期时间。
4.分析 RDB 文件
通过前面的学习,我们对RDB文件对各种内容和结构有了一定对了解,是时候抛开单纯的示例开始分析和观察一下实际的RDB的文件了。
我们使用od命令来分析服务器产生的RDB文件,该命令可以用给定的格式转存(dump)并打印输入文件。比如说,给对给定 -c参数可以以ASCII编码的方式打印输入文件,给定 -x参数可以以十六进制的方式打印输入文件,诸如此类,具体信息可以参考 od命令的文档。
-
无数据的RDB文件
127.0.0.1:6379> FLUSHALL
9737:M 18 Apr 11:06:48.335 * DB saved on disk
OK
127.0.0.1:6379> SAVE
9737:M 18 Apr 11:06:59.704 * DB saved on disk
sun@sun-pc:~$ od -c dump.rdb
0000000 R E D I S 0 0 0 7 372 r e d i s
0000020 - v e r v 9 9 9 . 9 9 9 . 9 9 9
0000040 372
r e d i s - b i t s 300 @ 372 005
0000060 c t i m e 302 S O 024 W 372 u s e d
0000100 - m e m 302 370 220 f 0 377 C r 227 036 F 332
0000120 R l
0000122
- 有数据的RDB文件
127.0.0.1:6379> FLUSHALL
9737:M 18 Apr 11:25:34.688 * DB saved on disk
OK
127.0.0.1:6379> set msg "hello"
OK
127.0.0.1:6379> save
9737:M 18 Apr 11:25:50.574 * DB saved on disk
OK
127.0.0.1:6379> QUIT
sun@sun-pc:~$ od -c dump.rdb
0000000 R E D I S 0 0 0 7 372 r e d i s
0000020 - v e r v 9 9 9 . 9 9 9 . 9 9 9
0000040 372
r e d i s - b i t s 300 @ 372 005
0000060 c t i m e 302 276 S 024 W 372 u s e d
0000100 - m e m 302 310 222 f 0 376 0 373 001 0 0 003
0000120 m s g 005 h e l l o 377 243 006 365 < 357 004
0000140
k
0000142
- 有过期时间的RDB文件
127.0.0.1:6379> FLUSHALL
9737:M 18 Apr 11:31:30.420 * DB saved on disk
OK
127.0.0.1:6379> SETEX msg 10086 "hello"
OK
127.0.0.1:6379> save
9737:M 18 Apr 11:33:16.016 * DB saved on disk
OK
127.0.0.1:6379> QUIT
sun@sun-pc:~$ od -c dump.rdb
0000000 R E D I S 0 0 0 7 372 r e d i s
0000020 - v e r v 9 9 9 . 9 9 9 . 9 9 9
0000040 372
r e d i s - b i t s 300 @ 372 005
0000060 c t i m e 302 { U 024 W 372 u s e d
0000100 - m e m 302 370 223 f 0 376 0 373 001 001 374 4
0000120 306 a ( T 001 0 0 0 003 m s g 005 h e l
0000140 l o 377 326 037 274 X 353 n 362 037
0000153
- 数字以8进制显示
- REDIS0007:RDB文件标志和版本号
- 372 结束符
- redis-bit:redis的位数64或32
- resdis-ver999.999.999:redis服务版本为999.999.999
- ctime :时间戳 8字节
- used-mem:redis使用内存的大小
- 374:RDB_OPCODE_EXPIRETIME_MS占8字节
- 377 EOF常量
- 最后8字节为校验和
三、AOF持久化
除了RDB持久化功能之外, Redis还提供了AOF(Append Only File)持久化功能。与RDB持久化通过保存数据库中的键值对来记录数据库状态不同,AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态的。
服务器在启动时,可以通过载入和运行AOF文件中保存的命令来还原服务器关闭之前的数据库状态。
0.导读
- AOF 文件通过保存所有修改数据库的写命令请求来记录服务器的数据库状态。
- AOF 文件中的所有命令都以 Redis 命令请求协议的格式保存。
- 命令请求会先保存到 AOF 缓冲区里面, 之后再定期写入并同步到 AOF 文件。
appendfsync选项的不同值对 AOF 持久化功能的安全性、以及 Redis 服务器的性能有很大的影响。- 服务器只要载入并重新执行保存在 AOF 文件中的命令, 就可以还原数据库本来的状态。
- AOF 重写可以产生一个新的 AOF 文件, 这个新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样, 但体积更小。
- AOF 重写是一个有歧义的名字, 该功能是通过读取数据库中的键值对来实现的, 程序无须对现有 AOF 文件进行任何读入、分析或者写入操作。
- 在执行 BGREWRITEAOF 命令时, Redis 服务器会维护一个 AOF 重写缓冲区, 该缓冲区会在子进程创建新 AOF 文件的期间, 记录服务器执行的所有写命令。 当子进程完成创建新 AOF 文件的工作之后, 服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾, 使得新旧两个 AOF 文件所保存的数据库状态一致。 最后, 服务器用新的 AOF 文件替换旧的 AOF 文件, 以此来完成 AOF 文件重写操作。
1. AOF持久化的实现
- 命令追加
当 AOF 持久化功能处于打开状态时, 服务器在执行完一个写命令之后, 会以协议格式将被执行的写命令追加到服务器状态的 aof_buf 缓冲区的末尾:
struct redisServer {
// ...
// AOF 缓冲区
sds aof_buf;
// ...
};
比如说, 如果客户端向服务器发送以下命令:
redis> RPUSH NUMBERS ONE TWO THREE
(integer) 3
那么服务器在执行这个 RPUSH 命令之后, 会将以下协议内容追加到 aof_buf 缓冲区的末尾:
*5
$5
RPUSH
$7
NUMBERS
$3
ONE
$3
TWO
$5
THREE
以上就是 AOF 持久化的命令追加步骤的实现原理。
- AOF 文件的写入与同步
Redis 的服务器进程就是一个事件循环(loop), 这个循环中的文件事件负责接收客户端的命令请求, 以及向客户端发送命令回复, 而时间事件则负责执行像 serverCron 函数这样需要定时运行的函数。
因为服务器在处理文件事件时可能会执行写命令, 使得一些内容被追加到 aof_buf 缓冲区里面, 所以在服务器每次结束一个事件循环之前, 它都会调用 flushAppendOnlyFile 函数, 考虑是否需要将 aof_buf 缓冲区中的内容写入和保存到 AOF 文件里面, 这个过程可以用以下伪代码表示:
def eventLoop(): while True: # 处理文件事件,接收命令请求以及发送命令回复 # 处理命令请求时可能会有新内容被追加到 aof_buf 缓冲区中 processFileEvents() # 处理时间事件 processTimeEvents() # 考虑是否要将 aof_buf 中的内容写入和保存到 AOF 文件里面 flushAppendOnlyFile()
flushAppendOnlyFile 函数的行为由服务器配置的 appendfsync 选项的值来决定, 各个不同值产生的行为如表所示。
appendfsync 选项的值 | flushAppendOnlyFile 函数的行为 |
|---|---|
always |
将 aof_buf 缓冲区中的所有内容写入并同步到 AOF 文件。 |
everysec |
将 aof_buf 缓冲区中的所有内容写入到 AOF 文件, 如果上次同步 AOF 文件的时间距离现在超过一秒钟, 那么再次对 AOF 文件进行同步, 并且这个同步操作是由一个线程专门负责执行的。 |
no |
将 aof_buf 缓冲区中的所有内容写入到 AOF 文件, 但并不对 AOF 文件进行同步, 何时同步由操作系统来决定。 |
- 文件的写入和同步
为了提高文件的写入效率, 在现代操作系统中, 当用户调用 write 函数, 将一些数据写入到文件的时候, 操作系统通常会将写入数据暂时保存在一个内存缓冲区里面, 等到缓冲区的空间被填满、或者超过了指定的时限之后, 才真正地将缓冲区中的数据写入到磁盘里面。
这种做法虽然提高了效率, 但也为写入数据带来了安全问题, 因为如果计算机发生停机, 那么保存在内存缓冲区里面的写入数据将会丢失。
为此, 系统提供了 fsync 和 fdatasync 两个同步函数, 它们可以强制让操作系统立即将缓冲区中的数据写入到硬盘里面, 从而确保写入数据的安全性。
AOF 持久化的效率和安全性
服务器配置
appendfsync选项的值直接决定 AOF 持久化功能的效率和安全性。当
appendfsync的值为always时, 服务器在每个事件循环都要将aof_buf缓冲区中的所有内容写入到 AOF 文件, 并且同步 AOF 文件, 所以always的效率是appendfsync选项三个值当中最慢的一个, 但从安全性来说,always也是最安全的, 因为即使出现故障停机, AOF 持久化也只会丢失一个事件循环中所产生的命令数据。当
appendfsync的值为everysec时, 服务器在每个事件循环都要将aof_buf缓冲区中的所有内容写入到 AOF 文件, 并且每隔超过一秒就要在子线程中对 AOF 文件进行一次同步: 从效率上来讲,everysec模式足够快, 并且就算出现故障停机, 数据库也只丢失一秒钟的命令数据。当
appendfsync的值为no时, 服务器在每个事件循环都要将aof_buf缓冲区中的所有内容写入到 AOF 文件, 至于何时对 AOF 文件进行同步, 则由操作系统控制。因为处于
no模式下的flushAppendOnlyFile调用无须执行同步操作, 所以该模式下的 AOF 文件写入速度总是最快的, 不过因为这种模式会在系统缓存中积累一段时间的写入数据, 所以该模式的单次同步时长通常是三种模式中时间最长的: 从平摊操作的角度来看,no模式和everysec模式的效率类似, 当出现故障停机时, 使用no模式的服务器将丢失上次同步 AOF 文件之后的所有写命令数据。
2. AOF文件的载入与数据还原
AOF文件包含来重建数据库状态的所有写命令,所以服务器只要读入并重新执行一遍AOF文件里面保存的写命令,就可以还原服务器关闭之前的数据库状态。
Redis 读取 AOF 文件并还原数据库的详细步骤如下:
1).创建一个不带网络连接的伪客户端(fake client)。
2).读取 AOF 所保存的文本,并根据内容还原出命令、命令的参数以及命令的个数。
3).根据命令、命令的参数和命令的个数,使用伪客户端执行该命令。
4).执行 2 和 3 ,直到 AOF 文件中的所有命令执行完毕。
完成第 4) 步之后, AOF 文件所保存的数据库就会被完整地还原出来。
注意, 因为 Redis 的命令只能在客户端的上下文中被执行, 而 AOF 还原时所使用的命令来自于 AOF 文件, 而不是网络, 所以程序使用了一个没有网络连接的伪客户端来执行命令。 伪客户端执行命令的效果, 和带网络连接的客户端执行命令的效果, 完全一样。
3. AOF重写
- 因为AOF是通过保存被执行的写命令来记录数据库状态的,所以随着服务器的运行时间久,AOF的文件会变得越来越大,不仅占用系统资源,而且当通过AOF文件来进行数据还原时花费的额时间也会更久。
- 为了解决AOF文件体积膨胀的问题,Redis提供了AOF文件重写(rewrite)功能。通过该功能,Redis服务器可以创建一个新的AOF文件来替代现有的AOF文件,新旧两个AOF文件所保存的额数据库状态相同,但新的AOF文件不会包含任何浪费空间的冗余命令,所以新AOF文件的体积通常会比旧AOF文件的体积要小的多。
- 虽然Redis将生成新AOF文件替换旧AOF文件的功能命名为“AOF文件重写”,但实际上,AOF文件重写并不需要对现有的AOF文件进行任何读取、分析或者写入操作,这个过程是通过读取服务器当前的数据库状态来实现的。
很明显,作为一种辅佐性的维护手段,Redis不希望AOF重写造成服务器无法处理请求,所以Redis决定将AOF重写程序放到子进程里进行,这样做可以达到两个目的:
- 子进程进行AOF重写期间,服务器进程(父进程)可以继续处理命令请求。
- 子进程带有服务器进程的额数据副本,使用子进程而不是线程,可以避免在使用锁的情况下保证数据的安全性。
不过,使用子进程也有一个问题需要解决,因为子进程在进行AOF重写期间,服务器进程还需要继续处理命令请求,而新的命令可能会对现有的数据库状态进行修改,从而使得服务器当前的数据库状态和重写后的AOF文件所保存的数据库状态不一致。
为了解决这个问题,Redis服务器设置了一个AOF重写缓冲区,这个缓冲区在服务器创建子进程之后开始使用,当Redis服务器执行完一个命令后,他会同时将这个写命令发送给AOF缓冲区和AOF重写缓冲区。
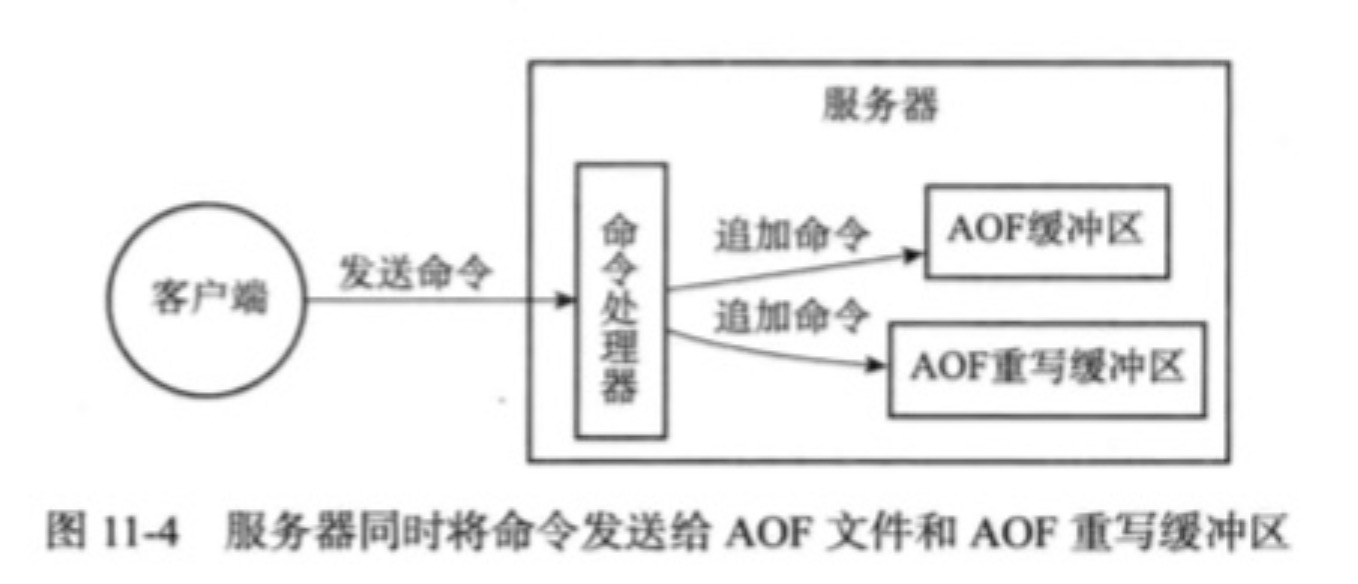
当子进程完成AOF重写之后,他会向父进程发送一个信号,父进程在接收到该信号后会调用一个信号处理函数,并进行一下工作:
- 1)将AOF重写缓冲区中的所有内容写入到新的AOF文件中,这时新AOF文件所保存的数据库状态将和服务器的状态一致。
- 2)对新的AOF文件进行该米ing,原子的(atomic)覆盖现有的AOF文件,完成新旧两个AOF文件的替换。
在这个信号处理函数执行完毕之后,父进程就可以继续向往常一样接受命令请求了。
在整个AOF重写后台执行过程中,只有信号处理函数执行时会对服务器进程(父进程)造成阻塞,在其他时候不会阻塞,这将AOF重写对服务器性能造成的影响降到了最低。
四、事件
Redis服务器是一个事件驱动程序,服务器需要处理一下两类事件:
1)文件事件 File Event: Redis服务器通过套接字与客户端或其他Redis服务器进行连接,而文件事件就是服务器对套接字操作的抽象。服务器与客户端或其他服务器的通信会产生相应的文件事件,而服务器则通过监听并处理这些事件来完成一系列网络通信操作。
2)时间事件 Time Event: Redis服务器中的一些操作(比如serverCron函数)需要在给定的时间点执行,而时间事件就是服务器对这类定时操作的抽象。
0.导读
- Redis 服务器是一个事件驱动程序, 服务器处理的事件分为时间事件和文件事件两类。
- 文件事件处理器是基于 Reactor 模式实现的网络通讯程序。
- 文件事件是对套接字操作的抽象: 每次套接字变得可应答(acceptable)、可写(writable)或者可读(readable)时, 相应的文件事件就会产生。
- 文件事件分为
AE_READABLE事件(读事件)和AE_WRITABLE事件(写事件)两类。 - 时间事件分为定时事件和周期性事件: 定时事件只在指定的时间达到一次, 而周期性事件则每隔一段时间到达一次。
- 服务器在一般情况下只执行
serverCron函数一个时间事件, 并且这个事件是周期性事件。 - 文件事件和时间事件之间是合作关系, 服务器会轮流处理这两种事件, 并且处理事件的过程中也不会进行抢占。
- 时间事件的实际处理时间通常会比设定的到达时间晚一些。
1.文件事件
Redis 基于 Reactor 模式开发了自己的网络事件处理器: 这个处理器被称为文件事件处理器(file event handler):
- 文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字, 并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时, 与操作相对应的文件事件就会产生, 这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行, 但通过使用 I/O 多路复用程序来监听多个套接字, 文件事件处理器既实现了高性能的网络通信模型, 又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接, 这保持了 Redis 内部单线程设计的简单性。
- 文件事件处理器的构成
下图展示了文件事件处理器的四个组成部分, 它们分别是套接字、 I/O 多路复用程序、 文件事件分派器(dispatcher)、 以及事件处理器。
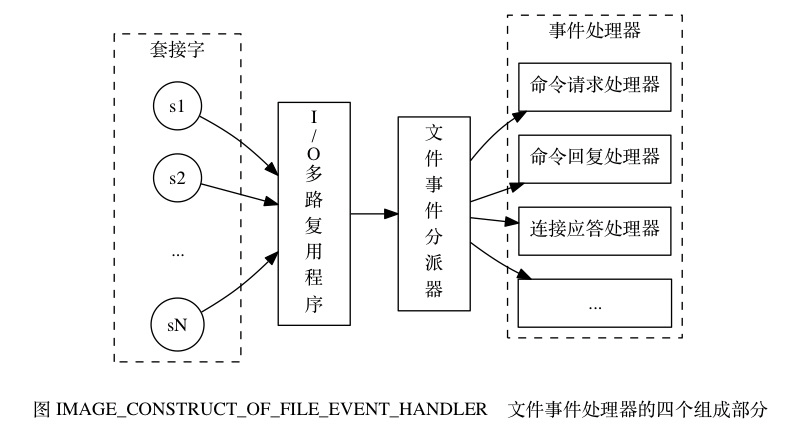
I/O 多路复用程序负责监听多个套接字, 并向文件事件分派器传送那些产生了事件的套接字。
尽管多个文件事件可能会并发地出现, 但 I/O 多路复用程序总是会将所有产生事件的套接字都入队到一个队列里面, 然后通过这个队列, 以有序(sequentially)、同步(synchronously)、每次一个套接字的方式向文件事件分派器传送套接字: 当上一个套接字产生的事件被处理完毕之后(该套接字为事件所关联的事件处理器执行完毕), I/O 多路复用程序才会继续向文件事件分派器传送下一个套接字, 如图 。

文件事件分派器接收 I/O 多路复用程序传来的套接字, 并根据套接字产生的事件的类型, 调用相应的事件处理器。
服务器会为执行不同任务的套接字关联不同的事件处理器, 这些处理器是一个个函数, 它们定义了某个事件发生时, 服务器应该执行的动作。
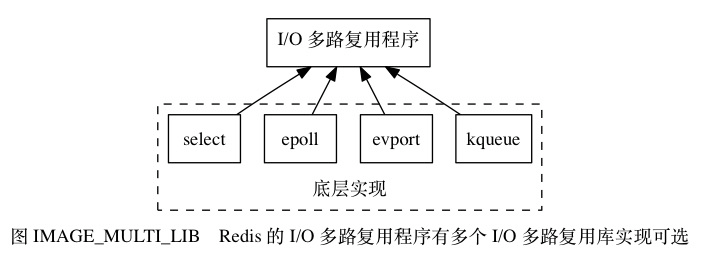
- I/O 多路复用程序的实现
Redis 的 I/O 多路复用程序的所有功能都是通过包装常见的 select 、 epoll 、 evport 和 kqueue 这些 I/O 多路复用函数库来实现的, 每个 I/O 多路复用函数库在 Redis 源码中都对应一个单独的文件, 比如 ae_select.c 、 ae_epoll.c 、 ae_kqueue.c , 诸如此类。
因为 Redis 为每个 I/O 多路复用函数库都实现了相同的 API , 所以 I/O 多路复用程序的底层实现是可以互换的, 如图 IMAGE_MULTI_LIB 所示。
- 事件的类型
I/O 多路复用程序可以监听多个套接字的
文件事件的处理器ae.h/AE_READABLE事件和ae.h/AE_WRITABLE事件, 这两类事件和套接字操作之间的对应关系如下:
- 当套接字变得可读时(客户端对套接字执行
write操作,或者执行close操作), 或者有新的可应答(acceptable)套接字出现时(客户端对服务器的监听套接字执行connect操作), 套接字产生AE_READABLE事件。 - 当套接字变得可写时(客户端对套接字执行
read操作), 套接字产生AE_WRITABLE事件。
I/O 多路复用程序允许服务器同时监听套接字的
AE_READABLE事件和AE_WRITABLE事件, 如果一个套接字同时产生了这两种事件, 那么文件事件分派器会优先处理AE_READABLE事件, 等到AE_READABLE事件处理完之后, 才处理AE_WRITABLE事件。这也就是说, 如果一个套接字又可读又可写的话, 那么服务器将先读套接字, 后写套接字。
- 当套接字变得可读时(客户端对套接字执行
-
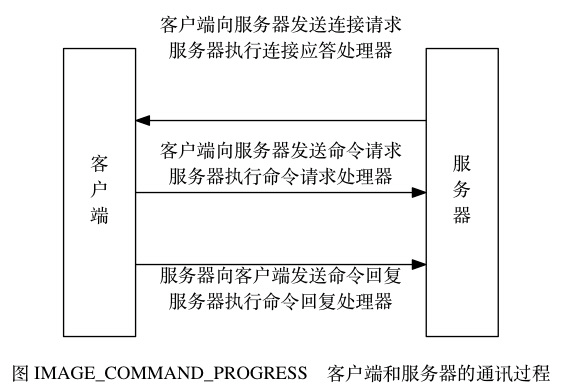
一次完整的客户端与服务器连接事件示例
让我们来追踪一次 Redis 客户端与服务器进行连接并发送命令的整个过程, 看看在过程中会产生什么事件, 而这些事件又是如何被处理的。
假设一个 Redis 服务器正在运作, 那么这个服务器的监听套接字的
AE_READABLE事件应该正处于监听状态之下, 而该事件所对应的处理器为连接应答处理器。如果这时有一个 Redis 客户端向服务器发起连接, 那么监听套接字将产生
AE_READABLE事件, 触发连接应答处理器执行: 处理器会对客户端的连接请求进行应答, 然后创建客户端套接字, 以及客户端状态, 并将客户端套接字的AE_READABLE事件与命令请求处理器进行关联, 使得客户端可以向主服务器发送命令请求。之后, 假设客户端向主服务器发送一个命令请求, 那么客户端套接字将产生
AE_READABLE事件, 引发命令请求处理器执行, 处理器读取客户端的命令内容, 然后传给相关程序去执行。执行命令将产生相应的命令回复, 为了将这些命令回复传送回客户端, 服务器会将客户端套接字的
AE_WRITABLE事件与命令回复处理器进行关联: 当客户端尝试读取命令回复的时候, 客户端套接字将产生AE_WRITABLE事件, 触发命令回复处理器执行, 当命令回复处理器将命令回复全部写入到套接字之后, 服务器就会解除客户端套接字的AE_WRITABLE事件与命令回复处理器之间的关联。图 IMAGE_COMMAND_PROGRESS 总结了上面描述的整个通讯过程, 以及通讯时用到的事件处理器。
2.时间事件
- Redis的事件事件分为以下两类:
1)定时事件:让一段程序在指定的时间之后执行一次。比如,让程序X在当前时间的30毫秒之后执行一次。
2)周期性事件:让一段程序每隔指定时间就执行一次。比如,让程序X每隔30毫秒执行一次。
目前版本的Redis只使用周期性事件,而没有使用定时事件。
- 时间事件由三部分组成:
1)id:服务器为时间时间创建全局唯一id,标识事件。ID号按从小到大的顺序递增,新的事件比旧的事件id大;
2)when:unix毫秒级时间戳,记录时间事件的到达时间;
3)timeProc:时间事件处理器,时间事件到达时调用相应的处理器进行处理。
- 一个时间事件是定时还是周期性,取决于其返回值:
1)如果返回的是AE_NOMORE,表示其是一次性的事件,即定时的,执行完毕后redis会将其删除;
2)如果返回的不是该结果,则表示是周期性事件,服务器会根据返回值,更新unix毫秒级时间戳,这样当下一次时间到达时又会执行该事件。
- 实现
redis将所有的时间事件放在一个无序链表中,当时间事件执行器执行时,会遍历整个链表,将所有已到达执行时间的事件调用相应的时间事件处理器进行处理。
虽然是无序链表,但是由于新的时间事件总是插入到表头,因此表头总是最新的时间事件。
无序链表结构如下图:

注意,我们这里说得无序链表,不是指的链表不按ID排序,而是指链表的元素不按照when的先后进行排序。正是没有按when属性进行排序,所以当时间时间运行时,必须遍历整个链表所有事件,这样才能确保所有到达执行时间的事件都能被执行。
- serverCron函数
redis目前仅使用serverCron函数作为时间事件,即目前仅有这一个时间事件。该时间事件主要进行以下操作:
1)更新redis服务器各类统计信息,包括时间、内存占用、数据库占用等情况。
2)清理数据库中的过期键值对。
3)关闭和清理连接失败的客户端。
4)尝试进行aof和rdb持久化操作。
5)如果服务器是主服务器,会定期将数据向从服务器做同步操作。
6)如果处于集群模式,对集群定期进行同步与连接测试操作。
redis服务器开启后,就会周期性执行此函数,直到redis服务器关闭为止。默认每秒执行10次,平均100毫秒执行一次,可以在redis配置文件的hz选项,调整该函数每秒执行的次数。
3.事件的调度与执行
由于redis服务器同时存在文件事件和时间事件,因此必须对这两个事件进行调度,决定何时处理文件事件,何时处理时间事件,以及花费多少时间处理这两类事件。
- 事件调度执行流程
事件的调度和执行由ae.c/aeProcessEvents函数负责,执行流程如下:
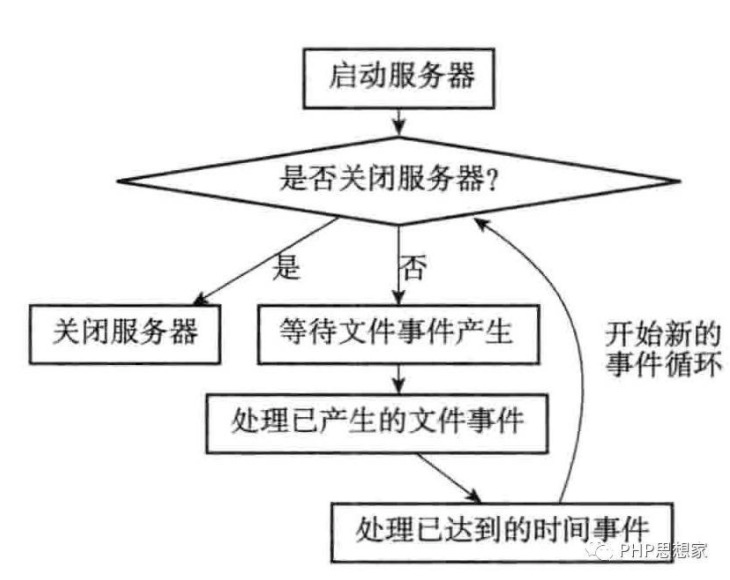
1)启动服务器,初始化服务器,一直处理事件,循环下面的2~6步骤,直到服务器关闭。服务器关闭会执行相关的清理操作。
2)获取到达时间距离当前时间最近的时间事件,计算到达时间,单位是毫秒,假设结果是x毫秒。
3)如果时间已经到达,则x是负数,将x置成0。
4)如果x不是0,则程序阻塞,等待文件事件的产生,再进入下一步,其中程序阻塞的最大等待时间是x毫秒,因为即使x毫秒内都没有文件事件的产生,但是x毫秒后必然有时间事件需要执行,因此不能继续阻塞;如果x是0,即已经有时间事件到了需要执行的时候,则程序不阻塞,直接进入下一步。
5)处理所有已经产生的文件事件。
6)处理所有已经产生的时间事件。
- 事件调度执行规则
1)程序等待文件事件的最大阻塞时间,是由到达时间最接近当前时间的时间时间决定,即避免了程序对时间事件的不断轮询,又保证阻塞时间不会太长。
2)由于文件事件的发生,是由客户端决定,即完全随机的。因此程序处理完一个文件事件后,如果没有新的待处理的文件事件,且还没到达最近的时间事件的执行时间,则程序会继续阻塞,直到达到最近的时间事件的时间,或期间有新的文件事件。
3)文件事件和时间事件都是同步、有序、原子的执行,执行一个事件的时候,其他事件会阻塞等待,不会发生事件的抢占。两类事件处理器都会减少程序的阻塞时间,并在有需要的时候主动让出执行权,避免事件的饥饿等待。
例如:文件事件的命令回复处理器,如果内容太多,写入的字节数超出预设的常量,则处理器会自动break,留下剩余的内容下一次再写;时间事件中会将耗时的rdb持久化、aof重写等操作,通过创建子进程,由子进程执行。
4)由于都是优先处理文件事件,后处理时间事件,且处理过程不会发生事件抢占,因此时间事件的实际执行时间,有可能比设定的执行时间稍晚一些。
执行示例如下图:

在等待下一个时间事件的过程中,程序处理了两个文件事件。其中第85毫秒,由于还没到时间事件的执行时间,而有文件事件,因此处理文件事件。由于文件事件处理完毕后是在130毫秒,则时间事件只能在131毫秒执行,比预设的100毫秒晚了31毫秒。
五、客户端
redis服务器是典型的一对多服务器程序,一个服务器可以与多个客户端可以与建立网络连接,每个客户端可以向服务器发送命令请求,而服务器接收并处理客户端发送的命令请求,并向客户端返回命令回复。
通过使用I/O多路复用技术实现的文件事件处理器,redis服务器使用单线程单进程的方式来处理请求,并与多个客户端建立网络通信。
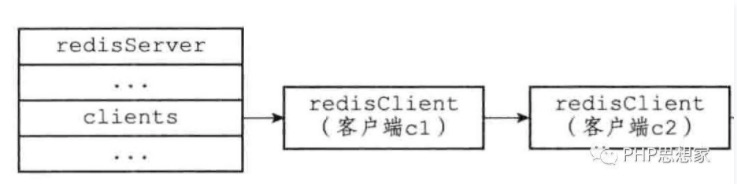
Redis服务器状态结构的clients属性是一个链表,这个链表保存了所有与服务器连接的客户端的状态结构,对客户端执行批量操作,或者查找某个指定的客户端,都可以通过遍历clients链表来完成:
struct redisServer {
// ...
list *clients;
// ...
}
0. 导读
- 服务器状态结构使用
clients链表连接起多个客户端状态, 新添加的客户端状态会被放到链表的末尾。 - 客户端状态的
flags属性使用不同标志来表示客户端的角色, 以及客户端当前所处的状态。 - 输入缓冲区记录了客户端发送的命令请求, 这个缓冲区的大小不能超过 1 GB 。
- 命令的参数和参数个数会被记录在客户端状态的
argv和argc属性里面, 而cmd属性则记录了客户端要执行命令的实现函数。 - 客户端有固定大小缓冲区和可变大小缓冲区两种缓冲区可用, 其中固定大小缓冲区的最大大小为 16 KB , 而可变大小缓冲区的最大大小不能超过服务器设置的硬性限制值。
- 输出缓冲区限制值有两种, 如果输出缓冲区的大小超过了服务器设置的硬性限制, 那么客户端会被立即关闭; 除此之外, 如果客户端在一定时间内, 一直超过服务器设置的软性限制, 那么客户端也会被关闭。
- 当一个客户端通过网络连接连上服务器时, 服务器会为这个客户端创建相应的客户端状态。 网络连接关闭、 发送了不合协议格式的命令请求、 成为 CLIENT_KILL 命令的目标、 空转时间超时、 输出缓冲区的大小超出限制, 以上这些原因都会造成客户端被关闭。
- 处理 Lua 脚本的伪客户端在服务器初始化时创建, 这个客户端会一直存在, 直到服务器关闭。
- 载入 AOF 文件时使用的伪客户端在载入工作开始时动态创建, 载入工作完毕之后关闭。
1. 客户端的参数
多个与服务器建立连接的客户端,服务器都为这些客户端建立相应的redis.h/redisClient结构,这个结构保存客户端当前的信息,以及执行相关功能时候需要用到的数据结构,主要包括:
1)客户端的套接字描述符
2)客户端名字
3)客户端的标志值
4)客户端用到的数据结构
-
- 客户端复制状态信息,及复制所需的数据结构,
- 客户端执行brpop、blpop等阻塞列表命令时用到的数据结构
- 客户端事务及watch用到的数据结构
- 客户端执行发布订阅功能用到的数据结构
2. 客户端属性
typedef struct redisClient{ //... int fd; robj *name; int flags; sds querybuf; robj **argv; int argc; struct redisCommand*cmd; char buf[REDIS_REPLY_TRUNK_BYTES]; int bufpos; list *reply; int authenticated; time_t ctime; time_tlastinteraction; time_t obuf_soft_limit_reached_time; //... }redisClient;
- 客户端状态包含的属性可以分为两类:
1)一类是比较通用的属性, 这些属性很少与特定功能相关, 无论客户端执行的是什么工作, 它们都要用到这些属性。
2)另外一类是和特定功能相关的属性, 比如操作数据库时需要用到的 db 属性和 dictid 属性, 执行事务时需要用到的 mstate 属性, 以及执行 WATCH 命令时需要用到的 watched_keys 属性, 等等。
- 套接字描述符
客户端状态的 fd 属性记录了客户端正在使用的套接字描述符:
typedef struct redisClient {
// ...
int fd;
// ...
} redisClient;
根据客户端类型的不同, fd 属性的值可以是 -1 或者是大于 -1 的整数:
-
- 伪客户端(fake client)的
fd属性的值为-1: 伪客户端处理的命令请求来源于 AOF 文件或者 Lua 脚本, 而不是网络, 所以这种客户端不需要套接字连接, 自然也不需要记录套接字描述符。 目前 Redis 服务器会在两个地方用到伪客户端, 一个用于载入 AOF 文件并还原数据库状态, 而另一个则用于执行 Lua 脚本中包含的 Redis 命令。 - 普通客户端的
fd属性的值为大于-1的整数: 普通客户端使用套接字来与服务器进行通讯, 所以服务器会用fd属性来记录客户端套接字的描述符。 因为合法的套接字描述符不能是-1, 所以普通客户端的套接字描述符的值必然是大于-1的整数。
- 伪客户端(fake client)的
执行 CLIENT_LIST 命令可以列出目前所有连接到服务器的普通客户端, 命令输出中的 fd 域显示了服务器连接客户端所使用的套接字描述符:
redis> CLIENT list
addr=127.0.0.1:53428 fd=6 name= age=1242 idle=0 ...
addr=127.0.0.1:53469 fd=7 name= age=4 idle=4 ...
- 名字
客户端的名字记录在客户端状态的 name 属性里面:
typedef struct redisClient {
// ...
robj *name;
// ...
} redisClient;
在默认情况下, 一个连接到服务器的客户端是没有名字的。比如在下面展示的 CLIENT_LIST 命令示例中, 两个客户端的 name 域都是空白的:
redis> CLIENT list
addr=127.0.0.1:53428 fd=6 name= age=1242 idle=0 ...
addr=127.0.0.1:53469 fd=7 name= age=4 idle=4 ...
使用 CLIENT_SETNAME 命令可以为客户端设置一个名字, 让客户端的身份变得更清晰。以下展示的是客户端执行 CLIENT_SETNAME 命令之后的客户端列表:
redis> CLIENT list
addr=127.0.0.1:53428 fd=6 name=message_queue age=2093 idle=0 ...
addr=127.0.0.1:53469 fd=7 name=user_relationship age=855 idle=2 ...
- 标志
客户端的标志属性 flags 记录了客户端的角色(role), 以及客户端目前所处的状态:
typedef struct redisClient {
// ...
int flags;
// ...
} redisClient;
flags 属性的值可以是单个标志,也可以是多个标志的二进制或, 比如:
flags = <flag>
or
flags = <flag1> | <flag2> | ...
每个标志使用一个常量表示, 一部分标志记录了客户端的角色:
-
- 在主从服务器进行复制操作时, 主服务器会成为从服务器的客户端, 而从服务器也会成为主服务器的客户端。
REDIS_MASTER标志表示客户端代表的是一个主服务器,REDIS_SLAVE标志表示客户端代表的是一个从服务器。 REDIS_PRE_PSYNC标志表示客户端代表的是一个版本低于 Redis 2.8 的从服务器, 主服务器不能使用 PSYNC 命令与这个从服务器进行同步。 这个标志只能在REDIS_SLAVE标志处于打开状态时使用。REDIS_LUA_CLIENT标识表示客户端是专门用于处理 Lua 脚本里面包含的 Redis 命令的伪客户端。
- 在主从服务器进行复制操作时, 主服务器会成为从服务器的客户端, 而从服务器也会成为主服务器的客户端。
而另外一部分标志则记录了客户端目前所处的状态:
-
REDIS_MONITOR标志表示客户端正在执行 MONITOR 命令。REDIS_UNIX_SOCKET标志表示服务器使用 UNIX 套接字来连接客户端。REDIS_BLOCKED标志表示客户端正在被 BRPOP 、 BLPOP 等命令阻塞。REDIS_UNBLOCKED标志表示客户端已经从REDIS_BLOCKED标志所表示的阻塞状态中脱离出来, 不再阻塞。REDIS_UNBLOCKED标志只能在REDIS_BLOCKED标志已经打开的情况下使用。REDIS_MULTI标志表示客户端正在执行事务。REDIS_DIRTY_CAS标志表示事务使用 WATCH 命令监视的数据库键已经被修改,REDIS_DIRTY_EXEC标志表示事务在命令入队时出现了错误, 以上两个标志都表示事务的安全性已经被破坏, 只要这两个标记中的任意一个被打开, EXEC 命令必然会执行失败。 这两个标志只能在客户端打开了REDIS_MULTI标志的情况下使用。REDIS_CLOSE_ASAP标志表示客户端的输出缓冲区大小超出了服务器允许的范围, 服务器会在下一次执行serverCron函数时关闭这个客户端, 以免服务器的稳定性受到这个客户端影响。 积存在输出缓冲区中的所有内容会直接被释放, 不会返回给客户端。REDIS_CLOSE_AFTER_REPLY标志表示有用户对这个客户端执行了 CLIENT_KILL 命令, 或者客户端发送给服务器的命令请求中包含了错误的协议内容。 服务器会将客户端积存在输出缓冲区中的所有内容发送给客户端, 然后关闭客户端。REDIS_ASKING标志表示客户端向集群节点(运行在集群模式下的服务器)发送了 ASKING 命令。REDIS_FORCE_AOF标志强制服务器将当前执行的命令写入到 AOF 文件里面,REDIS_FORCE_REPL标志强制主服务器将当前执行的命令复制给所有从服务器。 执行 PUBSUB 命令会使客户端打开REDIS_FORCE_AOF标志, 执行 SCRIPT_LOAD 命令会使客户端打开REDIS_FORCE_AOF标志和REDIS_FORCE_REPL标志。- 在主从服务器进行命令传播期间, 从服务器需要向主服务器发送 REPLICATION ACK 命令, 在发送这个命令之前, 从服务器必须打开主服务器对应的客户端的
REDIS_MASTER_FORCE_REPLY标志, 否则发送操作会被拒绝执行。
以上提到的所有标志都定义在 redis.h 文件里面。
# 客户端是一个主服务器
REDIS_MASTER
# 客户端正在被列表命令阻塞
REDIS_BLOCKED
# 客户端正在执行事务,但事务的安全性已被破坏
REDIS_MULTI | REDIS_DIRTY_CAS
# 客户端是一个从服务器,并且版本低于 Redis 2.8
REDIS_SLAVE | REDIS_PRE_PSYNC
# 这是专门用于执行 Lua 脚本包含的 Redis 命令的伪客户端
# 它强制服务器将当前执行的命令写入 AOF 文件,并复制给从服务器
REDIS_LUA_CLIENT | REDIS_FORCE_AOF | REDIS_FORCE_REPL
- 输入缓冲区
typedef struct redisClient {
// ...
sds querybuf;
// ...
} redisClient;
- 输出缓冲区
执行命令所得的命令回复会被保存在客户端状态的输出缓冲区里面, 每个客户端都有两个输出缓冲区可用, 一个缓冲区的大小是固定的, 另一个缓冲区的大小是可变的:
-
- 固定大小的缓冲区用于保存那些长度比较小的回复, 比如
OK、简短的字符串值、整数值、错误回复,等等。 - 可变大小的缓冲区用于保存那些长度比较大的回复, 比如一个非常长的字符串值, 一个由很多项组成的列表, 一个包含了很多元素的集合, 等等。
- 固定大小的缓冲区用于保存那些长度比较小的回复, 比如
typedef struct redisClient {
// ...
char buf[REDIS_REPLY_CHUNK_BYTES];
int bufpos;
// ...
list *reply;
// ...
} redisClient;
客户端的固定大小缓冲区由 buf 和 bufpos 两个属性组成:
-
buf是一个大小为REDIS_REPLY_CHUNK_BYTES字节的字节数组, 而bufpos属性则记录了buf数组目前已使用的字节数量。REDIS_REPLY_CHUNK_BYTES常量目前的默认值为16*1024, 也即是说,buf数组的默认大小为 16 KB 。
可变大小缓冲区由 reply 链表和一个或多个字符串对象组成。通过使用链表来连接多个字符串对象, 服务器可以为客户端保存一个非常长的命令回复, 而不必受到固定大小缓冲区 16 KB 大小的限制。
buf 数组的空间已经用完, 或者回复因为太大而没办法放进 buf 数组里面时, 服务器就会开始使用可变大小缓冲区。
- 命令与命令参数
在服务器将客户端发送的命令请求保存到客户端状态的 querybuf 属性之后, 服务器将对命令请求的内容进行分析, 并将得出的命令参数以及命令参数的个数分别保存到客户端状态的 argv 属性和 argc 属性:
typedef struct redisClient {
// ...
robj **argv;
int argc;
// ...
} redisClient;
argv 属性是一个数组, 数组中的每个项都是一个字符串对象: 其中 argv[0] 是要执行的命令, 而之后的其他项则是传给命令的参数。
argc 属性则负责记录 argv 数组的长度。
举个例子, 对于图 13-4 所示的 querybuf 属性来说, 服务器将分析并创建图 13-5 所示的 argv 属性和 argc 属性。
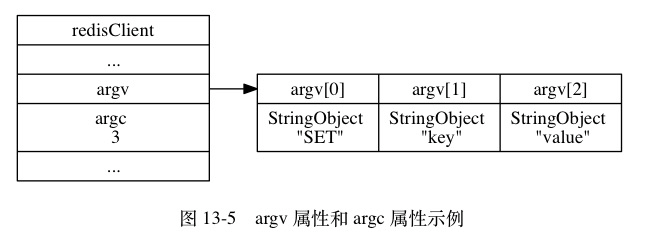
注意, 在图 13-5 展示的客户端状态中, argc 属性的值为 3 , 而不是 2 , 因为命令的名字 "SET" 本身也是一个参数。
当服务器从协议内容中分析并得出 argv 属性和 argc 属性的值之后, 服务器将根据项 argv[0] 的值, 在命令表中查找命令所对应的命令实现函数。
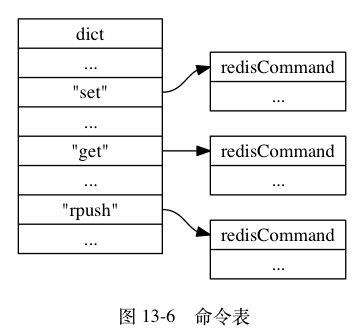
图 13-6 展示了一个命令表示例, 该表是一个字典, 字典的键是一个 SDS 结构, 保存了命令的名字, 字典的值是命令所对应的 redisCommand 结构, 这个结构保存了命令的实现函数、 命令的标志、 命令应该给定的参数个数、 命令的总执行次数和总消耗时长等统计信息。
当程序在命令表中成功找到 argv[0] 所对应的 redisCommand 结构时, 它会将客户端状态的 cmd 指针指向这个结构:
typedef struct redisClient {
// ...
struct redisCommand *cmd;
// ...
} redisClient;
之后, 服务器就可以使用 cmd 属性所指向的 redisCommand 结构, 以及 argv 、 argc 属性中保存的命令参数信息, 调用命令实现函数, 执行客户端指定的命令。
图 13-7 演示了服务器在 argv[0] 为 "SET" 时, 查找命令表并将客户端状态的 cmd 指针指向目标 redisCommand 结构的整个过程。注意:针对命令表的查找操作不区分输入字母的大小写, 所以无论 argv[0] 是 "SET" 、 "set" 、或者 "SeT , 等等, 查找的结果都是相同的。
客户端状态的 authenticated 属性用于记录客户端是否通过了身份验证:
typedef struct redisClient {
// ...
int authenticated;
// ...
} redisClient;
如果 authenticated 的值为 0 , 那么表示客户端未通过身份验证; 如果 authenticated 的值为 1 , 那么表示客户端已经通过了身份验证。
当客户端 authenticated 属性的值为 0 时, 除了 AUTH 命令之外, 客户端发送的所有其他命令都会被服务器拒绝执行:
redis> PING
(error) NOAUTH Authentication required.
redis> SET msg "hello world"
(error) NOAUTH Authentication required.
authenticated 属性仅在服务器启用了身份验证功能时使用: 如果服务器没有启用身份验证功能的话, 那么即使 authenticated 属性的值为 0 (这是默认值), 服务器也不会拒绝执行客户端发送的命令请求。
- 时间
最后, 客户端还有几个和时间有关的属性:
typedef struct redisClient {
// ...
time_t ctime;
time_t lastinteraction;
time_t obuf_soft_limit_reached_time;
// ...
} redisClient;
-
ctime属性记录了创建客户端的时间, 这个时间可以用来计算客户端与服务器已经连接了多少秒 —— CLIENT_LIST 命令的age域记录了这个秒数:lastinteraction属性记录了客户端与服务器最后一次进行互动(interaction)的时间, 这里的互动可以是客户端向服务器发送命令请求, 也可以是服务器向客户端发送命令回复。lastinteraction属性可以用来计算客户端的空转(idle)时间, 也即是, 距离客户端与服务器最后一次进行互动以来, 已经过去了多少秒 —— CLIENT_LIST 命令的idle域记录了这个秒数:obuf_soft_limit_reached_time属性记录了输出缓冲区第一次到达软性限制(soft limit)的时间, 稍后介绍输出缓冲区大小限制的时候会详细说明这个属性的作用。
redis> CLIENT list
addr=127.0.0.1:53428 ... age=1242 ... idle=12 ...
3. 客户端的创建与关闭
- 普通客户端连接
普通的客户端,通过connect命令连接上服务器后,会被redis将客户端的状态结构体加入到redisServer的链表属性clients的末尾。下图表示c1比c2先连上的redis服务器
- 普通客户端关闭
客户端关闭有下述情况:
- 客户端进程退出,或被kill。
- 客户端发送不符合协议格式的请求,
- 或成为client kill的目标。
- 用户设置空转时限而客户端达到此时限(该条件有例外,如客户端是主服务器、从服务器、客户端被阻塞、客户端正在发布订阅,就算超过时限也不会被关闭)。
- 客户端发送命令超出默认的1GB大小的请求。
- 服务器回复给客户端的内容超过输出缓冲区规定大小的内容。
服务器通过两种方式来先知客户端输出缓冲区的大小:
- 硬性限制(hard limit)。规定一个值,输出缓冲区超过这个值,立刻关闭该客户端。
- 软性限制(soft limit)。当超过这个值,但是还没超过硬性限制,会写入上述提及redis客户端结构体中obuf_soft_limit_reached_time属性,作为超过软性限制开始的时间,之后服务器会持续监控此客户端,如果超出规定的软性限制的时间,则关闭客户端;如果软性限制时间之前,客户端输出缓冲区内容减小到软性限制之前,则不关闭客户端,并且将obuf_soft_limit_reached_time的值清零
- Lua脚本的伪客户端
服务器会在初始化时出创建负责运行Lua脚本中包含的Redis命令的伪客户端,并将其存放在redisClient类型的lua_client属性。该客户端创建后的整个生命周期中一直会存在,直到服务器关闭才会关闭。
struct redisServer {
// ...
redisClient *lua_client;
// ...
}
- AOF文件的伪客户端
服务器载入aof文件时,会创建用于执行aof文件包含的Redis命令的伪客户端,并且载入完毕后关闭该客户端。
六、服务器
一个命令请求从发送到获得回复的过程中, 客户端和服务器需要完成一系列操作。
举个例子, 如果我们使用客户端执行以下命令:
redis> SET KEY VALUE
OK
那么从客户端发送 SET KEY VALUE 命令到获得回复 OK 期间, 客户端和服务器共需要执行以下操作:
- 客户端向服务器发送命令请求
SET KEY VALUE。 - 服务器接收并处理客户端发来的命令请求
SET KEY VALUE, 在数据库中进行设置操作, 并产生命令回复OK。 - 服务器将命令回复
OK发送给客户端。 - 客户端接收服务器返回的命令回复
OK, 并将这个回复打印给用户观看。
本节接下来的内容将对这些操作的执行细节进行补充, 详细地说明客户端和服务器在执行命令请求时所做的各种工作。
0.导读
- 一个命令请求从发送到完成主要包括以下步骤: 1. 客户端将命令请求发送给服务器; 2. 服务器读取命令请求,并分析出命令参数; 3. 命令执行器根据参数查找命令的实现函数,然后执行实现函数并得出命令回复; 4. 服务器将命令回复返回给客户端。
serverCron函数默认每隔100毫秒执行一次, 它的工作主要包括更新服务器状态信息, 处理服务器接收的SIGTERM信号, 管理客户端资源和数据库状态, 检查并执行持久化操作, 等等。- 服务器从启动到能够处理客户端的命令请求需要执行以下步骤: 1. 初始化服务器状态; 2. 载入服务器配置; 3. 初始化服务器数据结构; 4. 还原数据库状态; 5. 执行事件循环。
1. 服务器执行过程
- a.客户端发送命令
Redis 服务器的命令请求来自 Redis 客户端, 当用户在客户端中键入一个命令请求时, 客户端会将这个命令请求转换成协议格式, 然后通过连接到服务器的套接字, 将协议格式的命令请求发送给服务器, 如图 14-1 所示。

- b.服务端读取命令
当客户端与服务器之间的连接套接字因为客户端的写入而变得可读时, 服务器将调用命令请求处理器来执行以下操作:
- 读取套接字中协议格式的命令请求, 并将其保存到客户端状态的输入缓冲区里面。
- 对输入缓冲区中的命令请求进行分析, 提取出命令请求中包含的命令参数, 以及命令参数的个数, 然后分别将参数和参数个数保存到客户端状态的
argv属性和argc属性里面。 - 调用命令执行器, 执行客户端指定的命令。
举个例子, 假设客户端执行命令:
SET KEY VALUE
服务器先对命令进行分析, 并将得出的分析结果保存到客户端状态的 argv 属性和 argc 属性里面, 如图 14-3 所示。
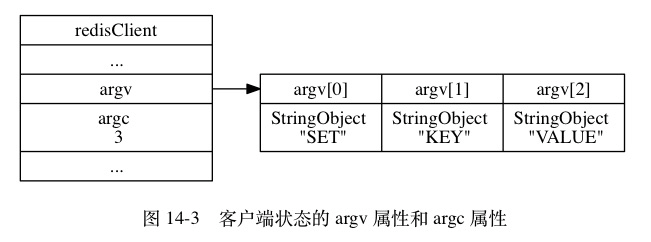
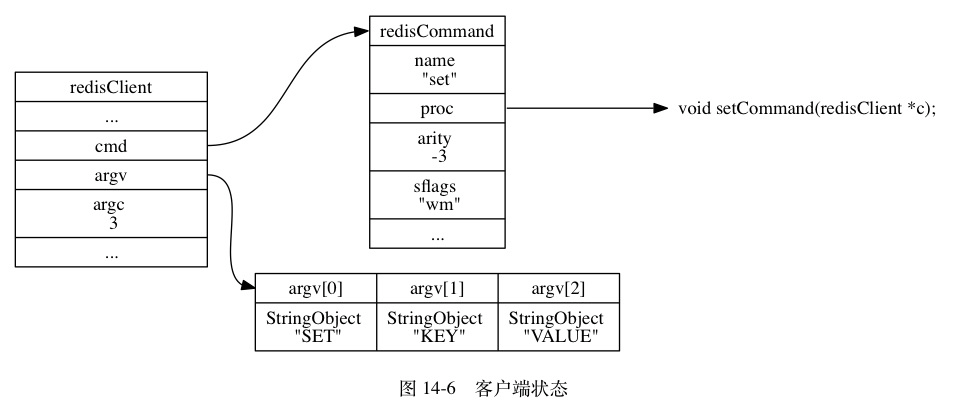
- c.服务端命令实现转换
命令执行器要做的第一件事就是根据客户端状态的 argv[0] 参数, 在命令表(command table)中查找参数所指定的命令, 并将找到的命令保存到客户端状态的 cmd 属性里面。
命令表是一个字典, 字典的键是一个个命令名字,比如 "set" 、 "get" 、 "del" ,等等; 而字典的值则是一个个 redisCommand 结构, 每个 redisCommand 结构记录了一个 Redis 命令的实现信息, 表 14-1 记录了这个结构的各个主要属性的类型和作用。
| 属性名 | 类型 | 作用 |
|---|---|---|
name |
char * |
命令的名字,比如 "set" 。 |
proc |
redisCommandProc * |
函数指针,指向命令的实现函数,比如 setCommand 。 redisCommandProc 类型的定义为 typedef void redisCommandProc(redisClient *c); 。 |
arity |
int |
命令参数的个数,用于检查命令请求的格式是否正确。 如果这个值为负数 -N ,那么表示参数的数量大于等于 N 。 注意命令的名字本身也是一个参数, 比如说 SET msg "hello world" 命令的参数是 "SET" 、 "msg" 、 "hello world" , 而不仅仅是 "msg" 和 "hello world" 。 |
sflags |
char * |
字符串形式的标识值, 这个值记录了命令的属性, 比如这个命令是写命令还是读命令, 这个命令是否允许在载入数据时使用, 这个命令是否允许在 Lua 脚本中使用, 等等。 |
flags |
int |
对 sflags 标识进行分析得出的二进制标识, 由程序自动生成。 服务器对命令标识进行检查时使用的都是 flags 属性而不是 sflags 属性, 因为对二进制标识的检查可以方便地通过 & 、 ^ 、 ~ 等操作来完成。 |
calls |
long long |
服务器总共执行了多少次这个命令。 |
milliseconds |
long long |
服务器执行这个命令所耗费的总时长。 |
表 14-2 列出了 sflags 属性可以使用的标识值, 以及这些标识的意义。
| 标识 | 意义 | 带有这个标识的命令 |
|---|---|---|
w |
这是一个写入命令,可能会修改数据库。 | SET 、 RPUSH 、 DEL ,等等。 |
r |
这是一个只读命令,不会修改数据库。 | GET 、 STRLEN 、 EXISTS ,等等。 |
m |
这个命令可能会占用大量内存, 执行之前需要先检查服务器的内存使用情况, 如果内存紧缺的话就禁止执行这个命令。 | SET 、 APPEND 、 RPUSH 、 LPUSH 、 SADD 、 SINTERSTORE ,等等。 |
a |
这是一个管理命令。 | SAVE 、 BGSAVE 、 SHUTDOWN ,等等。 |
p |
这是一个发布与订阅功能方面的命令。 | PUBLISH 、 SUBSCRIBE 、 PUBSUB ,等等。 |
s |
这个命令不可以在 Lua 脚本中使用。 | BRPOP 、 BLPOP 、 BRPOPLPUSH 、 SPOP ,等等。 |
R |
这是一个随机命令, 对于相同的数据集和相同的参数, 命令返回的结果可能不同。 | SPOP 、 SRANDMEMBER 、 SSCAN 、 RANDOMKEY ,等等。 |
S |
当在 Lua 脚本中使用这个命令时, 对这个命令的输出结果进行一次排序, 使得命令的结果有序。 | SINTER 、 SUNION 、 SDIFF 、 SMEMBERS 、 KEYS ,等等。 |
l |
这个命令可以在服务器载入数据的过程中使用。 | INFO 、 SHUTDOWN 、 PUBLISH ,等等。 |
t |
这是一个允许从服务器在带有过期数据时使用的命令。 | SLAVEOF 、 PING 、 INFO ,等等。 |
M |
这个命令在监视器(monitor)模式下不会自动被传播(propagate)。 | EXEC |
图 14-4 展示了命令表的样子, 并且以 SET 命令和 GET 命令作为例子, 展示了 redisCommand 结构:
-
- SET 命令的名字为
"set", 实现函数为setCommand; 命令的参数个数为-3, 表示命令接受三个或以上数量的参数; 命令的标识为"wm", 表示 SET 命令是一个写入命令, 并且在执行这个命令之前, 服务器应该对占用内存状况进行检查, 因为这个命令可能会占用大量内存。 - GET 命令的名字为
"get", 实现函数为getCommand函数; 命令的参数个数为2, 表示命令只接受两个参数; 命令的标识为"r", 表示这是一个只读命令。
- SET 命令的名字为

命令名字的大小写不影响命令表的查找结果
因为命令表使用的是大小写无关的查找算法, 无论输入的命令名字是大写、小写或者混合大小写, 只要命令的名字是正确的, 就能找到相应的
redisCommand结构。
- d.预执行命令
到目前为止, 服务器已经将执行命令所需的命令实现函数(保存在客户端状态的 cmd 属性)、参数(保存在客户端状态的 argv 属性)、参数个数(保存在客户端状态的 argc 属性)都收集齐了, 但是在真正执行命令之前, 程序还需要进行一些预备操作, 从而确保命令可以正确、顺利地被执行, 这些操作包括:
-
- 检查客户端状态的
cmd指针是否指向NULL, 如果是的话, 那么说明用户输入的命令名字找不到相应的命令实现, 服务器不再执行后续步骤, 并向客户端返回一个错误。 - 根据客户端
cmd属性指向的redisCommand结构的arity属性, 检查命令请求所给定的参数个数是否正确, 当参数个数不正确时, 不再执行后续步骤, 直接向客户端返回一个错误。 比如说, 如果redisCommand结构的arity属性的值为-3, 那么用户输入的命令参数个数必须大于等于3个才行。 - 检查客户端是否已经通过了身份验证, 未通过身份验证的客户端只能执行 AUTH 命令, 如果未通过身份验证的客户端试图执行除 AUTH 命令之外的其他命令, 那么服务器将向客户端返回一个错误。
- 如果服务器打开了
maxmemory功能, 那么在执行命令之前, 先检查服务器的内存占用情况, 并在有需要时进行内存回收, 从而使得接下来的命令可以顺利执行。 如果内存回收失败, 那么不再执行后续步骤, 向客户端返回一个错误。 - 如果服务器上一次执行 BGSAVE 命令时出错, 并且服务器打开了
stop-writes-on-bgsave-error功能, 而且服务器即将要执行的命令是一个写命令, 那么服务器将拒绝执行这个命令, 并向客户端返回一个错误。 - 如果客户端当前正在用 SUBSCRIBE 命令订阅频道, 或者正在用 PSUBSCRIBE 命令订阅模式, 那么服务器只会执行客户端发来的 SUBSCRIBE 、 PSUBSCRIBE 、 UNSUBSCRIBE 、 PUNSUBSCRIBE 四个命令, 其他别的命令都会被服务器拒绝。
- 如果服务器正在进行数据载入, 那么客户端发送的命令必须带有
l标识(比如 INFO 、 SHUTDOWN 、 PUBLISH ,等等)才会被服务器执行, 其他别的命令都会被服务器拒绝。 - 如果服务器因为执行 Lua 脚本而超时并进入阻塞状态, 那么服务器只会执行客户端发来的 SHUTDOWN nosave 命令和 SCRIPT KILL 命令, 其他别的命令都会被服务器拒绝。
- 如果客户端正在执行事务, 那么服务器只会执行客户端发来的 EXEC 、 DISCARD 、 MULTI 、 WATCH 四个命令, 其他命令都会被放进事务队列中。
- 如果服务器打开了监视器功能, 那么服务器会将要执行的命令和参数等信息发送给监视器。
- 检查客户端状态的
当完成了以上预备操作之后, 服务器就可以开始真正执行命令了。
注意
以上只列出了服务器在单机模式下执行命令时的检查操作, 当服务器在复制或者集群模式下执行命令时, 预备操作还会更多一些。
- e.执行命令
在前面的操作中, 服务器已经将要执行命令的实现保存到了客户端状态的 cmd 属性里面, 并将命令的参数和参数个数分别保存到了客户端状态的 argv 属性和 argc 属性里面, 当服务器决定要执行命令时, 它只要执行以下语句就可以了:
// client 是指向客户端状态的指针
client->cmd->proc(client);
该语句等于执行语句:
setCommand(client);
被调用的命令实现函数会执行指定的操作, 并产生相应的命令回复, 这些回复会被保存在客户端状态的输出缓冲区里面(buf 属性和 reply 属性), 之后实现函数还会为客户端的套接字关联命令回复处理器, 这个处理器负责将命令回复返回给客户端。
继续以之前的 SET 命令为例子, 图 14-6 展示了客户端包含了命令实现、参数和参数个数的样子。
函数调用 setCommand(client); 将产生一个 "+OK
" 回复, 这个回复会被保存到客户端状态的 buf 属性里面, 如图 14-7 所示。

- f.后续处理
在执行完实现函数之后, 服务器还需要执行一些后续工作,当以下操作都执行完了之后, 服务器对于当前命令的执行到此就告一段落了, 之后服务器就可以继续从文件事件处理器中取出并处理下一个命令请求了。
-
- 如果服务器开启了慢查询日志功能, 那么慢查询日志模块会检查是否需要为刚刚执行完的命令请求添加一条新的慢查询日志。
- 根据刚刚执行命令所耗费的时长, 更新被执行命令的
redisCommand结构的milliseconds属性, 并将命令的redisCommand结构的calls计数器的值增一。 - 如果服务器开启了 AOF 持久化功能, 那么 AOF 持久化模块会将刚刚执行的命令请求写入到 AOF 缓冲区里面。
- 如果有其他从服务器正在复制当前这个服务器, 那么服务器会将刚刚执行的命令传播给所有从服务器。
- g.命令回复
前面说过, 命令实现函数会将命令回复保存到客户端的输出缓冲区里面, 并为客户端的套接字关联命令回复处理器, 当客户端套接字变为可写状态时, 服务器就会执行命令回复处理器, 将保存在客户端输出缓冲区中的命令回复发送给客户端。
当命令回复发送完毕之后, 回复处理器会清空客户端状态的输出缓冲区, 为处理下一个命令请求做好准备。
- h.客户端接收命令
当客户端接收到协议格式的命令回复之后, 它会将这些回复转换成人类可读的格式, 并打印给用户观看(假设我们使用的是 Redis 自带的 redis-cli 客户端), 如图 14-8 所示。
继续以之前的 SET 命令为例子, 当客户端接到服务器发来的 "+OK
" 协议回复时, 它会将这个回复转换成 "OK
" , 然后打印给用户看:
redis> SET KEY VALUE
OK
以上就是 Redis 客户端和服务器执行命令请求的整个过程了。
2. serverConf命令操作
redis定时函数——serverCron,该函数,默认情况下,redis每100毫秒执行一次,这个执行间隔可以在配置文件进行设置。这个函数是用于管理服务器的资源,保证服务器更良好的运转。redis将部分用于此函数的属性,也存于结构体redisServer之中。
struct redisServer{
//...
time_t unixtime;
long long mstime;
unsigned lruclock:22;
size_t stat_peak_memory;
int shutdown_asap;
int aof_rewrite_scheduled;
pid_t rdb_child_pid;
pid_t aof_child_pid;
int cronloops;
//...
}
redis的serverCron函数,执行期间需要做11件事,如下:
- a.更新服务器时间缓存。
- redis中有许多功能要获取系统当前时间,则需要调用系统接口查询时间,这样比较耗时,因此redis在结构体中用unixtime、mstime属性,保存了当前时间,并且定时更新这个值。前者是秒级unix时间戳,后者是毫秒级unix时间戳。
- 但是,由于每100毫秒才更新因此,因而这两个值只会用在打印日志、更新服务器LRU时钟、决定是否进行持久化任务、计算服务器上线时间等,精度要求不高的地方使用。
- 对于键过期时间、慢查询日志等,服务器会再次进行系统时间调用,获取最精确的时间。
- b.更新lru始终
- lru记录的是服务器最后一次被访问的时间,是用于服务器的计算空转时长,用属性lruclock进行存储。默认情况下,每10秒更新一次。另外,每个redis对象也存了一个lru,保存的是该对象最后一次被被访问的时间。
- 当要计算redis对象的空转时间,则会用服务器的lru减去redis对象的lru,获得的结果即对象的空转时长。
- 在redis客户端,用命令objectidletime key,可以查看该key的空转时长,返回结果是以秒为单位。由于redis每10秒更新一次服务器的最后访问时间,因此不是很精确。
- c.更新服务器每秒执行命令次数
- 这个不是通过扫描全部的键,而是采用抽样的方式确定的结果。每100毫秒1次,随机抽取一些键,查看最近1秒是否有操作,来确定最近1秒的操作次数。
- 接着,会将这个值,与上一次的结果,取平均值,作为本次计算的每秒执行命令数。在存入结构体中,供下次取平均值使用。
- d.更新服务器内存峰值记录
- redis服务器中,用stat_peak_memory记录服务器内存峰值。每次执行serverCron函数,会查看当前内存使用量,并且与stat_peak_memory比较,如果超过这个值,就更新这个属性。
- e.处理sigterm终止信号
- redis服务器,用属性shutdown_asap记录当前的结果,0是不用进行操作,1的话是要求服务器尽快关闭。
- 因此,服务器关闭命令shutdown执行,并不会立即关闭服务器,
- 而是将服务器的shutdown_asap属性置成1,当下一次serverCron读取时,就会拒绝新的请求,完成当前正在执行的命令后,开始持久化相关的操作,结束持久化后才会关闭服务器。
- f.管理客户端资源
- 主要是会检查客户端的两个内容:
- 1)客户端很长时间没有和服务器响应,服务器认为该客户端超时,则会断开和该客户端的连接。
- 2)当客户端在上一次执行命令请求后,输入缓冲区超过规定的长度,程序会释放输入缓冲区,并创建一个默认大小的缓冲区,防止缓冲区过分消耗。
- 3)关闭输出缓冲区超出大小限制的客户端。
- g.管理数据库资源
- 主要是检查键是否过期,并且按照配置的策略,删除过期的键。如懒惰删除、定期删除等。
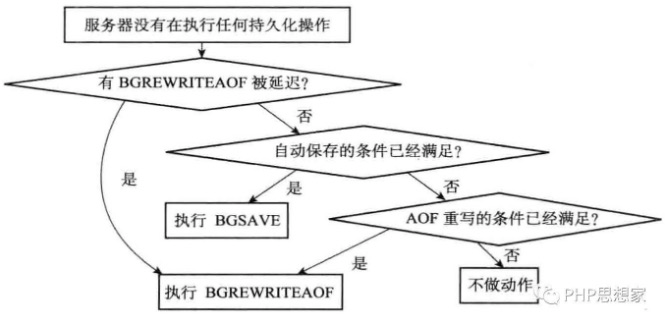
- h.执行被延迟的bgrewriteaofi.检查持久化操作的运行状态
- redis用属性aof_rewrite_scheduled记录是否有延迟的bgrewriteaof命令。
- 当执行bgsave命令期间,如果接收到bgrewriteaof命令,不会立即执行该命令,而是会将属性aof_rewrite_scheduled置成1。
- 每次执行serverCron函数执行时,发现属性aof_rewrite_scheduled是1,会检查当前是否在执行bgsave命令或bgrewriteaof命令,如果没有在执行这两个命令,则会执行bgrewriteaof命令。
redis服务器分别用rdb_child_pid和aof_child_pid属性,记录rdb和aof的子进程号(即子进程pid),如果没有在执行相应的持久化,则值是-1。
1)有一个值不是-1时。
-
- 每次服务器检查这两个属性,发现有一个不是-1,则会检查子进程是否有信号发来服务器进程。
- 如果有信号,表示rdb完成或aof重写完毕,服务器会进行后续的操作,比如用新的rdb、aof替换旧的相应文件。
- 如果没信号,表示持久化还没完成,程序不做动作。
2)两个值都是-1时。
-
- 两个值都是-1,会进行三个检查:
- 如果bgrewriteaof命令有存在延迟(即上述aof_rewrite_scheduled值是1),因为两个属性都是 -1,表示当前没有在持久化,则redis服务器会开始aof的重写。
- 检查服务器是否满足bgsave条件,如果满足,因为两个属性都是 -1,则会开始执行bgsave。
- 检查服务器是否满足bgrewriteaof条件,如果满足,因为两个属性都是 -1,则会开始执行bgrewriteaof。
- j.AOF缓冲区k.关闭异步客户端
- 如果开启aof,redis会记录每个写命令,写入aof缓冲区,但是为了减少磁盘I/O,不会立即写入aof文件。而是在执行serverCron函数时,才会开始将缓冲区内容写入aof文件。
- l.cronloops计数器加一
- redis用属性cronloops保存serverCron函数执行的次数。当执行一次serverCron,则会将属性值加1。
- 这个值目前的作用,是在主从复制情况下,会有一个条件是,每执行n次serverCron,则执行一次指定代码。
3. 服务器初始化
redis服务器开启时,会先进行初始化,主要有五个步骤,如下:
- a.初始化状态结构
- 首先,会创建一个structredisServer实例变量,存储服务器的状态。
- 接着,redis初始化服务器,会执行一次redis.c/initServerConfig函数,主要工作是设置服务器运行ID、默认运行频率、默认配置文件路径、运行架构、默认端口号、RDB条件、AOF条件、LRU时钟、创建命令表。
- 初始化状态结构,都是简单的结构,后续的数据库、共享对象、慢查询日志、Lua环境等,都是后面才创建的。
- b.加载用户配置c.初始化数据结构
- 在启动redis服务器时,可以通过参数指定配置文件、端口号等。redis会载入这些配置,并且和默认不同的时候,会覆盖默认的配置。
- 例如输入redis-server –port5000,则会先创建端口基于6379的,再在这一步修改端口号为5000。
- 在加载用户配置的文件,如果有定义新的结果,则使用新结果,否则就使用默认值。
1)创建数据结构
在第一步,只创建了一个命令表,在此步骤则会创建其他数据结构,包括:
server.client //链表,用于存储普通客户端,每个节点是一个redisClient结构;
server.db //链表,保存所有的数据库;
server.pubsub_channels//链表,保存频道订阅信息;server.pubsub_patterns链表,保存模式订阅信息。
server.lua //用于执行lua脚本的环境。
server.showlog //用于保存慢查询。
服务器会为上述结构分配内存空间。在此步骤才创建数据结构,是因为如果第一步创建,而第二步加载用户自定义配置的时候,有可能会修改到某些内容,则还需要重写。而命令表由于是固定的,因此可以放到第一步创建。
2)其他设置操作
除了创建数据结构,还会进行一些重要的设置,包括:
-
- 为服务器设置进程信号处理器。
- 创建共享对象,包括整数1~10000的字符串对象,“OK”、“ERR”回复的字符串对象等,用于避免反复创建相同对象。
- 打开服务器监听端口,为监听的套接字添加相应的应答事件,等待服务器正式运行时接收客户端的连接。
- 为serverCron函数创建时间事件,等待服务器正式执行serverCron。
- 如果AOF持久化开启,则打开aof文件,如果不存在则创建aof文件。
- 初始化服务器后台I/O模块(bio),为将来的I/O做好准备。
- d.还原数据库状态
- 如果开启aof,则载入aof文件;如果没有开启aof,则载入rdb文件。载入完成后,在日志中打印载入的耗时。
- e.执行事件循环
- 初始化最后一步,服务器将打印连接成功的日志。并且开始事件循环,初始化正式完成,可以开始处理客户端的请求。
内容参考自《Redis设计与实现》 https://book.douban.com/subject/25900156/