Scrapy工作流程
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
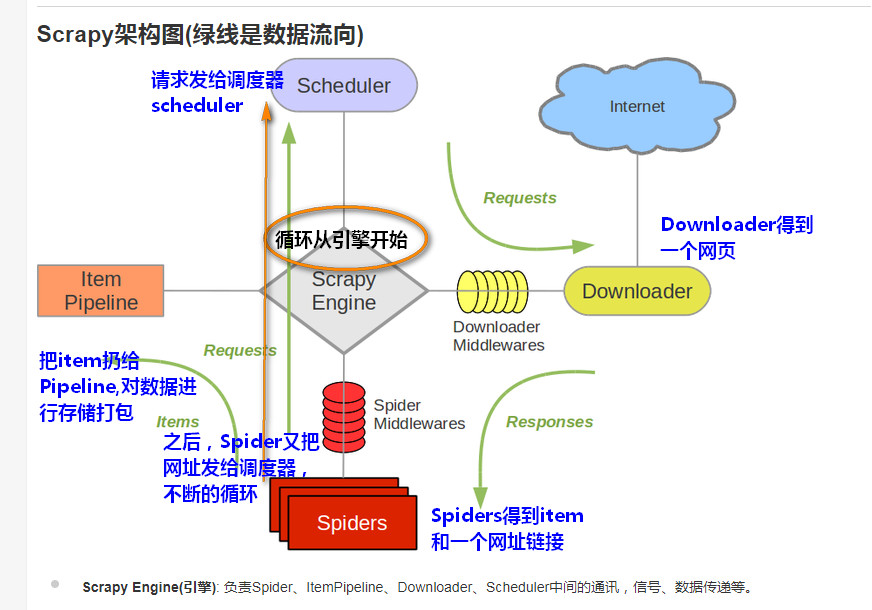
工作流程:
1.引擎把请求扔给调度器Scheduler.
2.Downloader 得到一个网页
3.Spider处理得到一个网址和item.
Spider把item扔给pipeline,把网址扔给scheduler,反复循环。
4.Pipeline流水线,把数据存储打包。
5.爬虫经过这些流程进行不断的循环。